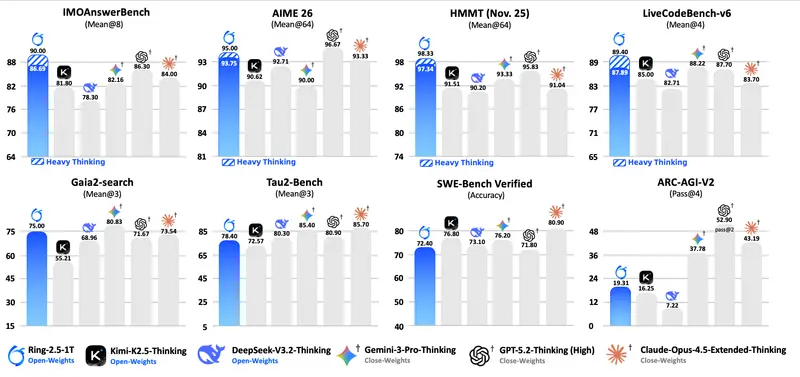
武汉大学、新加坡国立大学、中南大学、电子科技大学和微软的研究人员推出一个用于加速扩散模型(Diffusion Models)的轻量级框架 Glance,通过“慢-快”(Slow-Fast)的阶段感知(phase-aware)策略实现高效的加速。
- 项目主页:https://zhuobaidong.github.io/Glance
- GitHub:https://github.com/CSU-JPG/Glance
- 模型:https://huggingface.co/CSU-JPG/Glance
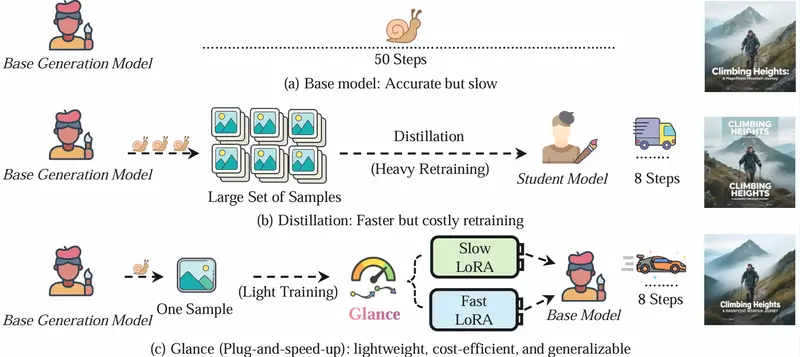
Glance 通过引入两个轻量级的 LoRA(Low-Rank Adaptation)适配器(Slow-LoRA 和 Fast-LoRA),在保持高质量生成的同时,显著减少了扩散模型的推理步骤。例如,Glance 能够在仅使用 1 个训练样本和 1 个 GPU 小时的情况下,将 50 步的扩散模型加速到 8 步,同时保持与原模型相当的生成质量。

主要功能
- 加速扩散模型:Glance 能够将复杂的扩散模型加速到仅需 8-10 步,同时保持高质量的图像生成。
- 轻量级适配:通过 Slow-LoRA 和 Fast-LoRA 适配器,Glance 在不重新训练整个模型的情况下实现加速。
- 数据和计算效率:Glance 仅需 1 个训练样本和 1 个 GPU 小时的训练时间,即可实现高效的加速,显著降低了数据和计算成本。
- 强泛化能力:即使在极少量的训练数据下,Glance 也能在未见过的提示(prompts)上生成高质量的图像。
主要特点
- 阶段感知加速:Glance 根据扩散过程中的信噪比(SNR)将去噪过程分为“慢”阶段(高噪声)和“快”阶段(低噪声),分别用 Slow-LoRA 和 Fast-LoRA 适配器处理。
- 轻量级 LoRA 适配器:通过在预训练的扩散模型中插入低秩适配器,Glance 在不改变基础模型结构的情况下实现加速。
- 极低数据需求:Glance 仅需 1 个训练样本即可学习有效的加速策略,显著减少了数据需求。
- 广泛的适用性:Glance 的加速策略不仅适用于文本到图像生成任务,还可以扩展到图像编辑、遥感图像生成等其他生成任务。
工作原理
- 扩散模型回顾:
- 扩散模型通过逐步去噪的方式将噪声数据转换为真实数据。Glance 通过优化去噪过程中的关键步骤来加速这一过程。
- 扩散模型的生成轨迹可以分为两个阶段:早期的语义阶段(高噪声)和后期的细节细化阶段(低噪声)。
- Slow-Fast 阶段划分:
- 慢阶段(Slow Phase):在高噪声阶段,模型主要关注全局结构和语义信息的恢复。Glance 在这一阶段使用 Slow-LoRA 适配器,确保语义信息的准确恢复。
- 快阶段(Fast Phase):在低噪声阶段,模型主要进行细节和纹理的细化。Glance 在这一阶段使用 Fast-LoRA 适配器,加速细节的生成。
- LoRA 适配器:
- Slow-LoRA:专注于早期高噪声阶段,确保全局语义的稳定恢复。
- Fast-LoRA:专注于后期低噪声阶段,加速细节的生成。
- 训练过程:
- Glance 通过在单个 GPU 上使用仅 1 个训练样本进行训练,显著减少了训练成本。训练过程中,Slow-LoRA 和 Fast-LoRA 适配器分别学习对应的去噪阶段。
测试结果
- 加速效果:
- Glance 在多个基准测试中实现了高达 5 倍的加速,同时保持与基础模型相当的生成质量。
- 在 COCO 数据集上,Glance 的 FID 分数与 50 步的基础模型相当,显示出极高的生成保真度。
- 泛化能力:
- 尽管仅使用 1 个训练样本,Glance 在未见过的提示上表现出色,生成的图像在语义和细节上均保持高质量。
- 数据效率:
- Glance 在仅使用 1 个训练样本的情况下,能够学习到有效的加速策略,显著减少了数据需求。
Glance 通过阶段感知的 Slow-Fast 策略和轻量级 LoRA 适配器,显著加速了扩散模型的推理过程,同时保持了高质量的生成能力。其极低的数据需求和强泛化能力使其在数据稀缺的领域中具有广泛的应用前景。未来,Glance 可以进一步探索动态专家切换和零样本扩散蒸馏等方向,以进一步提高其效率和适用性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...