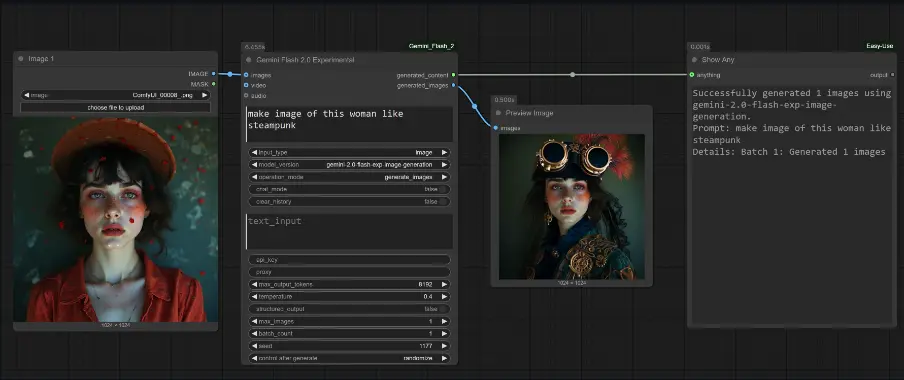
ComfyUI-QwenVL 是一款专为 ComfyUI 设计的自定义节点,核心优势在于深度集成了阿里巴巴云 Qwen 团队开发的 Qwen-VL 系列视觉 - 语言模型(LVLMs),涵盖最新的 Qwen3-VL 和 Qwen2.5-VL 全系列模型。
通过这个节点,用户无需复杂配置,就能在 ComfyUI 工作流中直接调用强大的多模态 AI 能力,高效完成文本生成、图像理解、视频分析三大核心任务 —— 无论是给图像写详细描述、提取视频关键信息,还是基于视觉内容生成结构化文本,都能实现无缝衔接。
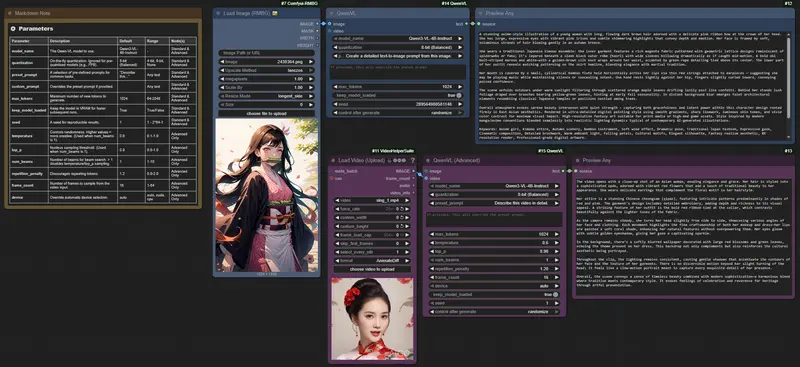
v1.0.0 初始发布:核心更新亮点(2025/10/17)
作为首次正式发布,v1.0.0 版本已具备完善的功能闭环,适配不同用户需求:
- 全系列模型支持:覆盖 Qwen3-VL 和 Qwen2.5-VL 所有主流型号,兼顾性能与轻量化;
- 自动化模型管理:首次使用时自动从 Hugging Face 下载所需模型,无需手动配置路径;
- 多规格量化选项:支持 4 位、8 位、FP16 即时量化,灵活平衡 VRAM 占用与生成质量;
- 双节点设计:同时提供标准节点(快速上手)和高级节点(精细调控),新手与资深用户都能适配;
- 硬件兼容性保障:自动检测 GPU 能力,避免 FP8 等不兼容模型的运行错误;
- 多模态输入支持:不仅能处理单张图像,还能直接解析视频帧序列,覆盖更多使用场景;
- 性能优化特性:“保持模型加载” 选项可减少重复加载耗时,种子参数确保生成结果可重现。
核心功能:为什么选择 ComfyUI-QwenVL?
1. 灵活的节点与提示系统
- 标准节点:一键调用核心功能,无需调整复杂参数,适合快速完成基础任务(如图像描述、简单分析);
- 高级节点:开放温度、束搜索、设备选择等细粒度参数,满足专业用户的定制化需求;
- 预设 + 自定义提示:内置 “Describe this...” 等常见任务预设,也可自由编写提示词,完全掌控生成逻辑。
2. 智能硬件适配与内存管理
- 硬件感知:自动识别 GPU 型号与显存大小,推荐适配的模型与量化规格,避免运行报错;
- 量化自适应:根据显存情况选择合适的量化模式,低显存 GPU 也能流畅运行大模型;
- 内存优化:“保持模型加载” 选项将模型常驻 VRAM,连续运行时速度提升明显,且可手动关闭以释放资源。
3. 全面的输入支持与稳定体验
- 多格式输入:支持单张图像(JPG/PNG 等)、视频帧序列(自动采样关键帧);
- 健壮错误处理:遇到显存不足、硬件不兼容等问题时,会输出清晰的提示信息,方便排查;
- 简洁日志输出:运行时控制台仅显示关键信息,避免冗余日志干扰操作。
快速安装:3 步完成部署
第一步:克隆仓库到 ComfyUI 目录
打开终端,执行以下命令,将插件仓库克隆到 ComfyUI 的自定义节点目录:
cd ComfyUI/custom\_nodes
git clone https://github.com/1038lab/ComfyUI-QwenVL.git
第二步:安装依赖包
进入插件目录,通过 pip 安装所需依赖(确保已激活 ComfyUI 对应的 Python 环境):
cd ComfyUI/custom\_nodes/ComfyUI-QwenVL
pip install -r requirements.txt
第三步:重启 ComfyUI
依赖安装完成后,重启 ComfyUI 软件,即可在节点列表中找到 QwenVL 相关节点,无需额外配置。
模型下载:自动与手动两种方式
1. 自动下载(推荐)
首次使用节点并选择模型后,插件会自动从 Hugging Face 下载对应文件,默认保存到 ComfyUI/models/LLM/Qwen-VL/ 目录,无需手动干预。
2. 手动下载(可选)
若需提前下载或替换模型,可直接访问以下链接下载,然后将文件放置到 ComfyUI/models/LLM/Qwen-VL/ 目录:
| 模型名称 | 下载链接 |
|---|---|
| Qwen3-VL-4B-Instruct | Download |
| Qwen3-VL-4B-Instruct-FP8 | Download |
| Qwen3-VL-8B-Instruct | Download |
| Qwen3-VL-4B-Thinking | Download |
| Qwen3-VL-4B-Thinking-FP8 | Download |
| Qwen2.5-VL-3B-Instruct | Download |
| Qwen2.5-VL-7B-Instruct | Download |
使用教程:基础与高级玩法
1. 基础使用(快速上手)
适合新手或简单任务,全程仅需 4 步:
- 在 ComfyUI 节点面板中,找到
🧪AILab/QwenVL类别,添加 “QwenVL” 标准节点; - 在节点参数中选择所需模型(默认推荐 Qwen3-VL-4B-Instruct);
- 将图像或视频帧序列节点的输出,连接到 QwenVL 节点的输入端口;
- 选择预设提示或填写自定义提示词,点击 “Queue Prompt” 运行工作流,即可获得生成结果。
2. 高级使用(精细调控)
若需优化生成效果或适配特殊场景,可使用 “QwenVL(高级)” 节点,重点关注以下参数:
- 温度(temperature):调整生成随机性,0.1 更严谨,1.0 更具创造性;
- 束搜索(num_beams):大于 1 时会禁用温度 /top_p 采样,生成结果更连贯;
- 重复惩罚(repetition_penalty):大于 1.0 可减少重复内容,推荐 1.2 左右;
- 帧计数(frame_count):处理视频时可调整采样帧数,16 帧为默认平衡值,复杂视频可适当增加。
关键参数解读:按需调整更高效
| 参数名称 | 功能描述 | 默认值 | 取值范围 | 适用节点 |
|---|---|---|---|---|
| model_name | 选择使用的 Qwen-VL 模型 | Qwen3-VL-4B-Instruct | - | 标准 + 高级 |
| quantization | 模型量化模式(预量化模型忽略) | 8-bit (Balanced) | 4-bit/8-bit/None | 标准 + 高级 |
| preset_prompt | 预定义提示词 | "Describe this..." | 任意文本 | 标准 + 高级 |
| custom_prompt | 自定义提示词(覆盖预设) | - | 任意文本 | 标准 + 高级 |
| max_tokens | 生成文本的最大长度 | 1024 | 64-2048 | 标准 + 高级 |
| keep_model_loaded | 模型常驻 VRAM(加速后续运行) | True | True/False | 标准 + 高级 |
| seed | 生成结果种子(确保可重现) | 1 | 1-2^64-1 | 标准 + 高级 |
| temperature | 控制生成随机性(num_beams=1 时生效) | 0.6 | 0.1-1.0 | 仅高级 |
| top_p | 核采样阈值(num_beams=1 时生效) | 0.9 | 0.0-1.0 | 仅高级 |
| num_beams | 束搜索数量(>1 禁用温度 /top_p) | 1 | 1-10 | 仅高级 |
| repetition_penalty | 减少重复内容的惩罚系数 | 1.2 | 0.0-2.0 | 仅高级 |
| frame_count | 视频输入的采样帧数 | 16 | 1-64 | 仅高级 |
| device | 手动指定运行设备(覆盖自动选择) | auto | auto/cuda/cpu | 仅高级 |
量化选项对比:选对模式更省心
不同量化模式对应不同的硬件条件与使用需求,可根据 GPU 显存大小选择:
| 量化模式 | 精度类型 | 内存占用 | 运行速度 | 生成质量 | 推荐适用场景 |
|---|---|---|---|---|---|
| None (FP16) | 16 位浮点 | 高 | 最快 | 最佳 | 高显存 GPU(16GB+) |
| 8-bit (Balanced) | 8 位整数 | 中 | 快 | 很好 | 平衡需求(8GB + 显存) |
| 4-bit (VRAM-friendly) | 4 位整数 | 低 | 较慢 * | 良好 | 低显存 GPU(<8GB) |
* 注:4 位量化虽大幅降低显存占用,但因需要实时去量化计算,部分低配电脑可能出现速度变慢,属于正常现象。
实用设置建议:新手避坑指南
- 模型选择:新手优先用 Qwen3-VL-4B-Instruct(平衡性能与速度);40 系列 GPU 可尝试 FP8 版本,性能更优;
- 内存模式:计划连续运行多次时,保持
keep_model_loaded=True;若需同时运行其他大模型节点,可临时关闭释放 VRAM; - 量化选择:默认 8 位即可满足多数场景;显存 > 16GB 选 FP16 追求最佳质量;显存 < 8GB 选 4 位确保流畅运行;
- 性能优化:首次加载模型可能较慢,后续运行会明显加快;处理长视频时,可适当降低 frame_count 减少耗时。
关于 Qwen-VL 模型
ComfyUI-QwenVL 节点的核心能力来自阿里巴巴云 Qwen 团队的开源视觉 - 语言模型(LVLMs)。这类模型的优势在于能深度理解视觉内容(图像 / 视频)与文本的关联,不仅能生成描述性文本,还能完成视觉问答、内容分析、逻辑推理等复杂任务,尤其适合需要跨模态交互的场景。
未来路线图:后续更新计划
已完成(v1.0.0)
- ✅ Qwen3-VL/2.5-VL 全系列模型支持
- ✅ 自动模型下载与管理
- ✅ 4 位 / 8 位 / FP16 量化功能
- ✅ FP8 模型硬件兼容性检查
- ✅ 图像 / 视频帧序列输入支持
未来计划
- 🔄 支持 GGUF 格式模型,适配 CPU 及更多硬件;
- 🔄 集成更多主流视觉 - 语言模型,提供更丰富选择;
- 🔄 新增微调相关参数,支持生成效果定制;
- 🔄 强化视频处理能力,支持更多视频格式与分析功能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











