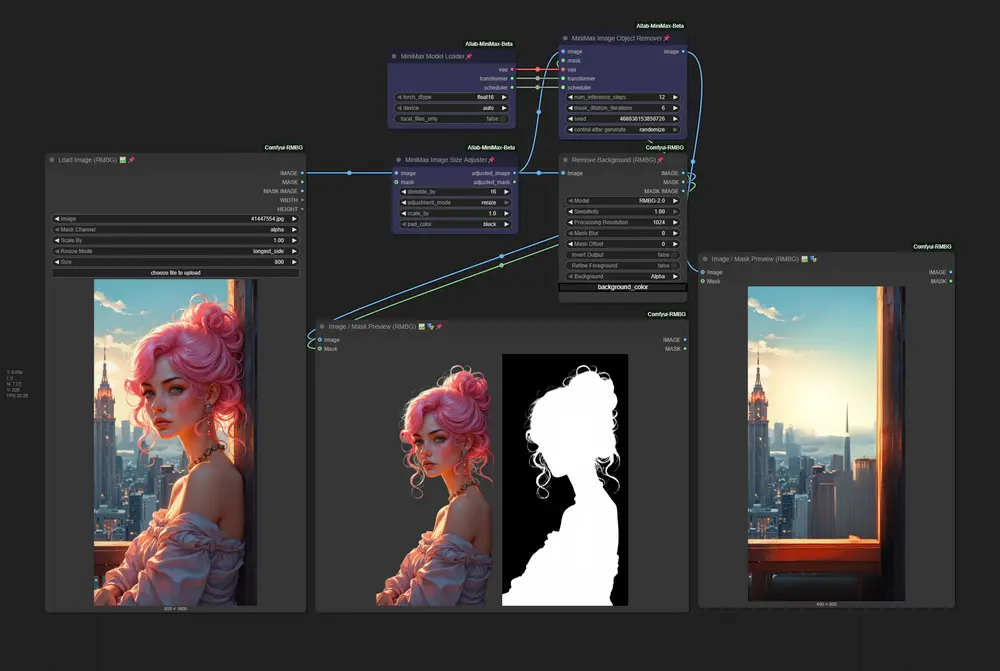
开发者obisin打造的 FSampler 的新插件已上线,为 ComfyUI 用户提供了一种无需训练、不依赖特定模型的扩散模型采样加速方案。它通过预测每一步的噪声(epsilon),减少对主模型的调用次数,在保持图像质量的同时显著提升生成速度。
该插件兼容主流采样器(如 Euler、DPM++、DDIM 等),支持固定跳步模式与激进自适应模式,适用于 flux、wan2.2、qwen 等常用模型,目前已在 2080 Ti 上完成初步测试。
核心原理:预测噪声,跳过冗余计算
FSampler 并非修改采样器本身,而是一个轻量级加速层,位于调度器与积分器之间。其核心思想是:
利用最近几步真实的 epsilon 输出,外推出后续步骤的噪声值,并将其直接输入现有采样器流程中,从而跳过部分昂贵的 UNet 推理调用。
这种方式被称为“Epsilon 外推”,具有以下特点:
- 无需训练:完全基于已有输出做数学推导;
- 采样器无关:不影响 Euler、DPM++ 2M/2S、LMS、RES 等算法的原始数学逻辑;
- 确定性强:由于所有方程为确定性运算,相同种子下,跳步与非跳步结果高度一致,适合生产前快速预览。
支持模式:从保守到激进,灵活选择
FSampler 提供多种跳步策略,满足不同场景需求:
| 模式 | 说明 | 加速效果 | 推荐用途 |
|---|---|---|---|
none | 基线模式(无跳步) | 0% | 质量验证基准 |
h2/s2, h2/s3 | 使用前2步预测,线性外推 | ~20–25% | 快速稳定加速 |
h3/s3, h3/s4 | Richardson 外推法 | ~12–16% | 高质量敏感任务 |
h4/s4 | 三次多项式预测 | ~10–12% | 极端保质场景 |
adaptive | 自适应门控:对比 h3 和 h2 预测评分,动态决定是否跳步 | 40–60%+ | 追求极致效率 |
💡 小贴士:建议从
h2开始测试,确认稳定性后再尝试adaptive模式。
关键技术保障:稳定、可控、可诊断
为了防止因跳步引入伪影或漂移,FSampler 内置多重保护机制:
✅ 学习稳定器 L(Learning Stabilizer)
- 对预测的 epsilon 进行缩放校正(除以 L);
- 仅在真实模型调用时更新 L,确保长期稳定性。
✅ 多重验证机制
- 幅度钳位:防止预测值过大;
- 有限差分检查:检测异常变化趋势;
- 余弦相似度比对:确保预测 epsilon 与历史方向一致。
✅ 安全防护设置
protect_first_steps:保护起始阶段关键细节(默认开启);protect_last_steps:保留最后几轮精细修复;- 最大连续跳步步数限制:防止单次跳跃过多导致失控。
✅ 实时诊断输出
每步显示:
- σ 值、epsilon 范数、x_rms;
- 当前跳步状态(如
[RISK]提示); - 各阶段耗时统计,便于性能分析。
如何安装?
方法一:Git 克隆(推荐)
cd ComfyUI/custom_nodes
git clone https://github.com/obisin/comfyui-FSampler
重启 ComfyUI 即可使用。
方法二:手动安装
- 下载仓库 ZIP 包;
- 解压至
ComfyUI/custom_nodes/comfyui-FSampler/; - 重启 ComfyUI。
⚠️ 测试提示:建议启用
comfy cache,避免模型加载时间干扰性能对比。
如何使用?(ComfyUI 工作流集成)
- 替换原有的
KSampler节点为FSampler或FSampler Advanced; - 正常连接模型、VAE、正负提示词等;
- 在参数中设置:
- 选择采样器与调度器(完全兼容原有配置);
- 设置
skip_mode:none:用于验证基线质量;h2/h3:推荐起点;adaptive:追求最大加速;
- 可选调整
protect_first_steps和protect_last_steps(通常默认即可);
📌 建议先用
skip_mode=none跑一次作为参考,再开启跳步进行对比。
兼容性说明
| 功能 | 是否支持 | 说明 |
|---|---|---|
| LoRA / ControlNet / IP-Adapter | ✅ | FSampler 位于中间层,对条件透明 |
| SDXL Turbo / LCM | ⚠️ 有限支持 | 低步数(<10步)场景收益较小 |
| 自定义调度器 | ✅ | 只要输出 sigma 序列即可兼容 |
| f16 / f8 模型 | ✅ | 已在混合精度环境下测试通过 |
常见问题解答
Q: 图像出现伪影怎么办?
A: 按顺序尝试以下操作:
- 使用
skip_mode=none验证是否原生问题; - 改用更保守的
h2或h3模式; - 增加
protect_first_steps(如设为 5–10); - 更换采样器组合(某些组合本就不稳定)。
Q: 和其他加速方法冲突吗?
A: 不冲突!FSampler 与其他优化方式互补:
- 可与 LCM/Turbo 蒸馏模型共用;
- 支持 量化模型运行;
- 兼容 动态 CFG 等技巧;
- 它专注于减少采样步数,而非降低单步推理成本。
视觉效果对比(实测示例)
所有测试均使用相同 seed、prompt 和 comfy cache 环境,确保公平比较。

Wan2.2 模型
- [baseline.png] — 原始结果
- [fsampler_none.png] — 无跳步验证
- [fsampler_h2.png] — h2/s2 模式,约 24% 加速,细节保留良好
- [fsampler_adaptive.png] — 自适应模式,流畅过渡,复杂结构未崩坏
Qwen 模型
- 类似趋势:h2 保持一致性,adaptive 显著提速且未见明显退化
🔍 观察发现:跳步并非单纯“降质”,而是引导模型走向略有不同的合理变体——这反而可用于探索创意多样性。
注意事项
- 目前已在 flux、wan2.2、qwen 上测试,欢迎社区测试其他模型并反馈;
adaptive模式较激进,在极端 prompt 或复杂控制条件下可能出现退化,请务必先验证;- 所有跳步均为确定性过程,相同配置下可复现结果,利于批量生产前快速筛选。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











