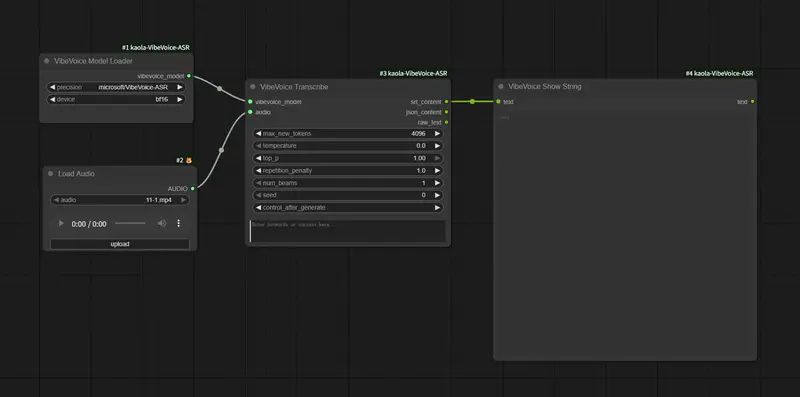
ComfyUI VibeVoice ASR是一款专为ComfyUI打造的自定义节点,核心价值在于将Microsoft VibeVoice ASR强大的语音识别能力集成到ComfyUI工作流中,让用户无需切换外部工具,直接在ComfyUI内完成高质量、长时程的语音转录任务,同时支持说话人分离、时间戳标注与标准SRT字幕导出,满足音频转文字、字幕制作、会议记录整理等多场景需求。
相较于传统语音识别工具,这款自定义节点无需复杂的命令行操作,完全适配ComfyUI的可视化工作流逻辑,拖拽节点即可完成配置与运行,降低了VibeVoice ASR模型的使用门槛,让ComfyUI用户(无论是创作者、开发者还是音频从业者)都能快速上手,实现语音数据的高效处理。
此外,该节点还支持上下文/热词补充,可提升专业术语、特殊姓名的识别准确性,同时输出SRT字符串与原始JSON数据,兼顾普通用户的便捷使用与高级用户的二次开发需求。
核心功能特性:强大、全面、适配ComfyUI工作流
ComfyUI VibeVoice ASR的功能围绕“高质量语音转录”展开,完美继承了Microsoft VibeVoice ASR的核心优势,同时针对ComfyUI环境进行优化,核心特性如下:
- 长时语音识别支持:突破普通语音识别工具的时长限制,单次可处理长达60分钟的音频文件,无需分段切割,适合处理会议录音、播客、长篇有声书等长时程音频内容,提升处理效率。
- 自动生成标准SRT字幕:转录完成后,自动生成带精准时间戳的标准SRT格式字幕,无需手动校对时间轴,可直接用于视频剪辑、字幕投放等场景,节省后期制作时间。
- 智能说话人分离:能够自动识别音频中的不同说话者,并以“说话人0、说话人1”等格式进行标注区分,适合整理会议记录、访谈内容,快速区分不同发言者的表述,便于后续内容梳理。
- 上下文/热词优化:支持手动输入上下文信息(如专业术语、人名、地名、行业黑话等),帮助模型提升特殊内容的识别准确性,解决专业场景下语音识别误差过高的问题。
- 双格式丰富输出:同时提供两种输出格式,满足不同用户需求——
srt_content为直接可用的字幕文本,适合普通用户;json_content为详细原始JSON数据,包含完整的转录信息、时间戳、说话人标签,适合高级用户进行二次处理与开发。 - ComfyUI无缝集成:作为ComfyUI自定义节点,完全适配ComfyUI的可视化工作流,可与其他音频处理节点、文本处理节点联动,构建更复杂的自动化工作流,无需脱离ComfyUI环境。
安装步骤:三步完成部署,重启即可使用
该节点的安装流程简单清晰,核心分为“克隆仓库、安装依赖、重启ComfyUI”三步,前置要求是已安装并正常运行ComfyUI,且具备Python环境。
步骤1:克隆项目仓库到ComfyUI自定义节点目录
首先打开终端(Windows可使用CMD或PowerShell,Mac/Linux使用终端),切换到ComfyUI的custom_nodes目录,然后克隆项目源码:
# 切换到ComfyUI自定义节点目录(请替换为你的ComfyUI实际路径)
cd ComfyUI/custom_nodes/
# 克隆项目仓库
git clone https://github.com/kana112233/ComfyUI-kaola-VibeVoice-ASR.git
# 进入项目目录
cd ComfyUI-kaola-VibeVoice-ASR
步骤2:安装项目所需依赖
项目运行需要特定的Python依赖包,执行以下命令安装requirements.txt中列出的所有依赖:
# 安装依赖包
pip install -r requirements.txt
⚠️ 重要注意事项:
- 该节点要求
transformers库版本≥4.51.3,若你的环境中该库版本过低,会导致节点运行失败,请执行pip install --upgrade transformers进行更新。- 安装过程中若出现网络超时,可切换国内PyPI镜像源(如阿里云、清华源)加速安装。
步骤3:重启ComfyUI,验证节点是否生效
安装完成后,关闭当前运行的ComfyUI服务,然后重新启动ComfyUI。
重启成功后,在ComfyUI的节点列表中,找到VibeVoice类别,即可看到该节点的所有相关组件,说明安装成功,可开始配置使用。
详细使用指南:可视化配置,拖拽即可运行
该节点包含两个核心组件:VibeVoice 模型加载器(负责加载模型与配置运行环境)和VibeVoice 转录(负责执行具体的语音转录任务),以下是详细的使用说明与配置要点。
前置提醒:显存要求
该模型(约7B参数)对显卡显存要求较高,经实测,12G显存运行时会出现显存不足(爆显存)的问题,推荐使用16G及以上显存的GPU运行,若显存不足,可尝试降低精度模式(如从bf16切换为fp16),或使用CPU运行(CPU运行速度较慢,仅适合短音频测试)。
组件1:VibeVoice 模型加载器(核心配置)
该节点的作用是加载VibeVoice ASR模型,并配置运行精度与设备,核心配置项如下:
- model_name(模型路径/名称)
- 自动下载(推荐,适合有网络连接的用户):保持默认值
microsoft/VibeVoice-ASR即可,首次运行时,模型会自动下载到HuggingFace缓存文件夹(默认路径:~/.cache/huggingface),后续运行可直接复用,无需重复下载。 - 手动指定(适合离线使用或网络不佳的用户):先从HuggingFace官网下载
microsoft/VibeVoice-ASR模型文件,将其放置在本地文件夹(建议路径:ComfyUI/models/vibevoice),然后在此配置项中粘贴该文件夹的绝对路径(示例:Windows路径D:\ComfyUI\models\vibevoice\VibeVoice-ASR,Linux/Mac路径/content/ComfyUI/models/vibevoice/VibeVoice-ASR)。
- 自动下载(推荐,适合有网络连接的用户):保持默认值
- precision(运行精度)
- 推荐选项:
bf16(适合现代高端GPU,显存占用相对合理,运行速度快,识别效果好)。 - 备选选项:
fp16(适合中端GPU,显存占用略低于bf16,识别效果基本无损耗)、fp32(适合低端GPU或CPU,显存/内存占用最高,运行速度最慢,仅作为兜底选择)。
- 推荐选项:
- device(运行设备)
- 推荐选项:
auto(自动检测当前环境的可用设备,优先选择GPU,无需手动配置,适合大多数用户)。 - 备选选项:
cuda(强制使用NVIDIA GPU运行)、mps(适合Mac设备带Apple Silicon芯片)、cpu(强制使用CPU运行,仅适合测试)。
- 推荐选项:
组件2:VibeVoice 转录(执行转录任务)
该节点的作用是接收音频输入,执行语音转录任务,并输出结果,核心配置项与输出说明如下:
- 核心输入项
audio:连接ComfyUI的标准AUDIO输出节点(如LoadAudio节点,用于加载本地音频文件),支持常见音频格式(如MP3、WAV等)。context_info(可选,非必填):输入上下文补充信息,如专业术语、人名、地名、项目名称等,帮助模型提升特殊内容的识别准确性,示例:“人工智能、ComfyUI、VibeVoice、语音识别”。
- 核心输出项
srt_content:标准SRT格式的字幕文本,包含时间戳与转录内容,可直接复制保存为.srt文件,用于视频字幕制作。json_content:详细的原始JSON数据,包含完整的转录信息(每个语句的开始时间、结束时间、转录文本、说话人标签等),适合高级用户进行二次处理(如数据提取、格式转换等)。
快速上手:使用示例工作流
项目仓库中已提供现成的示例工作流文件examples/vibevoice_workflow_example.json,无需手动配置节点,步骤如下:
- 找到该JSON文件,将其保存到本地。
- 打开ComfyUI,直接将该JSON文件拖放到ComfyUI的工作流编辑区域。
- 替换工作流中的
LoadAudio节点的音频文件路径(选择你自己的本地音频文件)。 - 按需调整
VibeVoice 模型加载器的配置(如设备、精度)。 - 点击ComfyUI的“运行”按钮,即可开始执行语音转录任务,等待运行完成后,查看输出结果。
更新方法:更新核心VibeVoice库,保持功能最新
该节点将原始VibeVoice仓库作为子模块包含在VibeVoice_src目录中,若需要更新核心VibeVoice库(获取最新功能与Bug修复),执行以下命令即可:
# 切换到ComfyUI自定义节点的项目目录
cd ComfyUI/custom_nodes/ComfyUI-kaola-VibeVoice-ASR/VibeVoice_src
# 拉取最新代码,完成更新
git pull
更新完成后,无需重新安装依赖,直接重启ComfyUI即可生效,节点会使用更新后的核心库运行。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











