
Lightrick官方发布LTX-2一月末更新,本次更新围绕创作者在真实世界视频工作流中的核心需求——更高精度、更灵活的可控性展开,通过优化Gemma文本编码节点、新增多模态引导器、升级IC-LoRA训练器三大核心模块,解决了显存占用高、跨模态同步难、微调效率低等痛点,帮助创作者从“原始生成”转向“有意图、可重复的精准生成”。所有更新均基于社区反馈打造,适配消费级硬件,进一步降低了专业AI视频创作的门槛。
Gemma文本编码节点全新升级:解决显存瓶颈,提速提示词迭代
Gemma作为LTX-2的文本编码模型,虽能输出高质量编码,但较大的显存占用导致其在消费级显卡上频繁卸载/重新加载,成为提示词迭代的最大瓶颈——尤其是频繁修改提示词时,操作效率极低。本次更新通过新增3个专属节点,从根本上解决该问题,实现更轻松、更快速的提示词条件化。
1. 新增两大核心节点,彻底优化Gemma使用体验
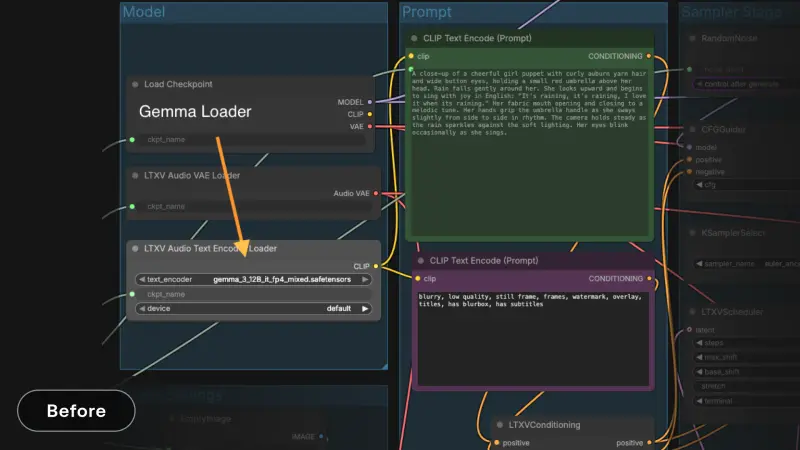
节点1:LTXVSaveConditioning / LTXVLoadConditioning
- 核心功能:支持保存/加载已完成的提示词编码,保存后再次使用无需重新加载Gemma模型,直接调用编码结果即可。
- 适用场景:重用固定提示词集的工作流(如Detailer流程),这类场景的有效提示词通常为空白或静态,一次编码可反复使用,大幅减少显存占用和等待时间。
节点2:Gemma API Text Encoding (LTX)
- 核心功能:通过Lightrick官方API执行Gemma文本编码,完全免费,专门为本地运行LTX的创作者设计。
- 核心优势:编码速度快(不到1秒完成),无需将Gemma模型加载到本地显存,即使频繁修改提示词,也不会产生额外的硬件开销,直接消除提示词迭代的最大瓶颈。
- 注意事项:该节点仅处理纯文本编码,若需要提示词增强,需在编码前完成相关操作。
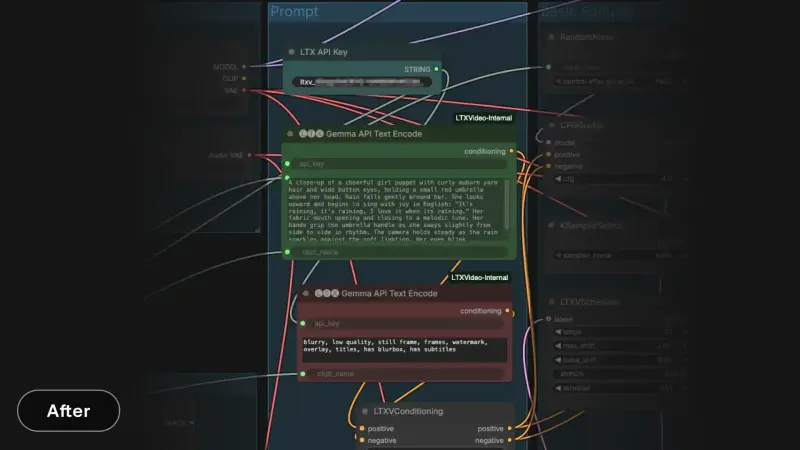
2. Gemma API编码节点快速上手(3步操作)
- 从Lightrick官方控制台获取专属API密钥;
- 配置节点参数,需与下游模型保持一致:
api_key:你的LTX官方API密钥;prompt:需要编码的文本提示词;ckpt_name:指定LTX检查点(如ltx-2-19b-dev-fp8.safetensors),需匹配后续管道使用的模型;
- 直接使用节点输出的嵌入向量,可无缝连接到下游所有节点,与本地编码节点使用方式完全一致。
3. 实际使用效果
社区早期测试反馈,本次优化让提示词迭代的体验发生质的变化:修改提示词从“高成本操作”变为“正常工作流环节”,创作者可更自由地进行提示词实验,无需承受“一次做对”的压力,迭代周期大幅缩短,尤其在消费级GPU上,体验提升尤为明显。
新增多模态引导器:实现提示词与跨模态对齐的独立精细控制
多模态引导器是分类器自由引导(CFG)技术的扩展升级,核心解决AI视频创作中“音频-视频耦合度难控制、跨模态同步性差、视觉伪影多”的问题。它通过最多四次模型调用,构建多维度的引导方向,将提示词遵从性、视觉稳定性、跨模态同步性的控制解耦,让创作者可根据需求独立调参,实现更精准的创作意图表达。
1. 三大独立引导拨盘,按模态灵活配置
多模态引导器提供3个核心调参拨盘,每个拨盘均可针对不同模态单独设置参数,覆盖创作核心需求:
CFG引导(cfg > 1)
- 核心作用:推动模型向正向提示词靠拢、远离负向提示词,控制提示词的遵从性和语义准确性。
- 实用技巧:当视频的视觉风格、物体保真度为核心需求时,适当提高
cfg值。
时空引导(stg > 0)
- 核心作用:推动模型远离自身的扰动、降级版本,减少视频结构性伪影,避免刚性物体破裂(基于STG专属技术实现)。
- 实用技巧:当视频出现物体破裂、画面闪烁、结构失真等问题时,提高
stg值。
跨模态引导(modality_scale > 1)
- 核心作用:推动模型远离“忽略其他模态”的生成版本,控制音频-视频的跨模态同步性。
- 实用技巧:高值强制更紧密的同步(适合口型同步、节奏性肢体运动);低值允许更松散的耦合(让运动更自然),按需调整平衡同步性与自然度。
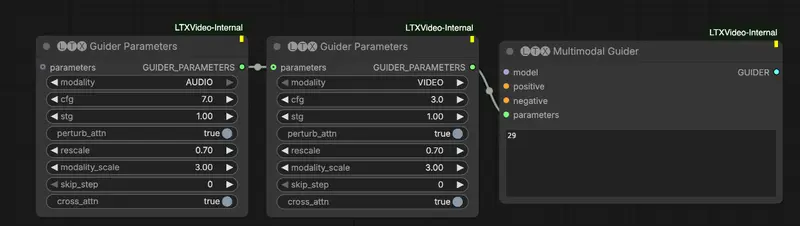
2. 附加实用参数,适配精细化调参需求
除三大核心拨盘外,多模态引导器还提供5个附加参数,满足进阶调参需求,默认参数可适配大多数场景,无需额外修改:
| 参数名 | 取值范围 | 核心作用 | 实用建议 |
|---|---|---|---|
skip_blocks | 数值 | 禁用STG扰动模型中的指定注意力层 | 无特殊实验需求,直接使用第29层 |
skip_step | 0/1/2 | 定期跳过某模态的扩散步骤 | 0=不跳过(默认);1=隔一步跳一次;2=三步跳两步 |
rescale | 0~1 | 引导后的结果归一化 | 0=不归一化;1=完全归一化;0~1=部分归一化(高CFG/STG值时用,防止画面过饱和) |
perturb_attn | True/False | 控制STG引导的扰动模型是否针对当前模态扰动 | 通常设为True(默认) |
cross_attn | True/False | 控制当前模态到其他模态的交叉注意力层是否激活 | 通常设为True(默认) |
3. 核心价值
通过将三大核心控制维度解耦,创作者无需再为“兼顾提示词准确性而牺牲同步性”“为减少伪影而丢失风格”发愁,可根据具体创作需求,独立调整每个维度的参数,实现从“被动接受生成结果”到“主动控制生成过程”的转变。
IC-LoRA训练器全面改进:提速推理,优化内存,实现联合控制
IC-LoRA作为LTX-2的重要微调工具,本次更新针对真实硬件的实操痛点进行多项优化,同时推出全新的IC-LoRA联合控制模型,让微调更高效、更稳定,推理速度大幅提升,适配本地或受限GPU的使用场景。
1. 三大核心优化:让微调更适配真实硬件
- 内存行为优化:针对常见训练工作流优化内存占用,减少显存溢出风险,在消费级GPU上也能稳定运行;
- 迭代周期提速:优化训练流程,大幅缩短微调的迭代时间,提升创作效率;
- 训练过程可预测:解决此前微调中参数波动、结果不稳定的问题,在本地或受限GPU上实现更可控的微调。
2. 推理速度翻倍:核心优化原理
本次更新通过参考视频缩放的方式降低计算成本,实现推理速度质的提升:
- 训练阶段:将参考视频按比例缩小(通常2倍),用于视频到视频生成,大幅降低交叉注意力层的计算量;
- 推理阶段:沿用相同的缩放方法,让RoPE与更小的特征网格对齐,从底层减少计算开销。
- 实际效果:推理速度提升约2倍,具体提升幅度根据视频的长度和分辨率略有差异。
3. 新增IC-LoRA联合控制模型:一站式支持多条件微调
作为训练器优化的延伸,官方全新训练了IC-LoRA联合控制模型,核心亮点为:
- 基于小网格工作,与上述缩放优化完美适配,不牺牲推理速度;
- 一站式支持深度、姿态、边缘三种条件的微调,无需单独加载多个模型;
- 智能自动识别:根据用户提供的输入条件,自动选择对应的微调逻辑,无需手动切换,操作更便捷。
4. 使用方式
将你的ComfyUI更新至最新版本,直接使用官方提供的专属Comfy工作流,即可快速启用IC-LoRA联合控制功能,无需额外的配置和改造。
本次LTX-2一月末更新是一次围绕真实视频工作流的精准优化,没有堆砌花哨功能,而是聚焦创作者在实际使用中遇到的显存瓶颈、调参难、微调效率低三大核心痛点,通过:
- Gemma编码节点优化+免费API,彻底解决提示词迭代的硬件限制;
- 多模态引导器,实现提示词、视觉稳定性、跨模态同步性的独立精细控制;
- IC-LoRA训练器升级+联合控制模型,实现推理提速、内存优化、多条件一站式微调。
三大核心模块的升级,让LTX-2在“可控性、效率、适配性”上实现全面提升,不仅让专业创作者能更精准地实现创作意图,也让消费级硬件用户能更流畅地进行AI视频创作,真正实现“从原始生成到有意图、可重复的精准生成”的转变。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











