
在 AI 视频与图像编辑中,高质量对象移除一直是一个挑战:既要自然填补背景,又要保持时间连贯性,同时避免生成伪影或“幻觉内容”。
ComfyUI MiniMax-Remover 是基于最新研究 MiniMax-Remover(来自港中大、深大等团队)开发的 ComfyUI 自定义节点插件,将这一前沿方法无缝集成到你的工作流中。
它无需复杂配置,仅需 6–12 次推理步骤,即可完成高质量的对象移除,且无需分类器自由引导(CFG),显著提升效率与稳定性。
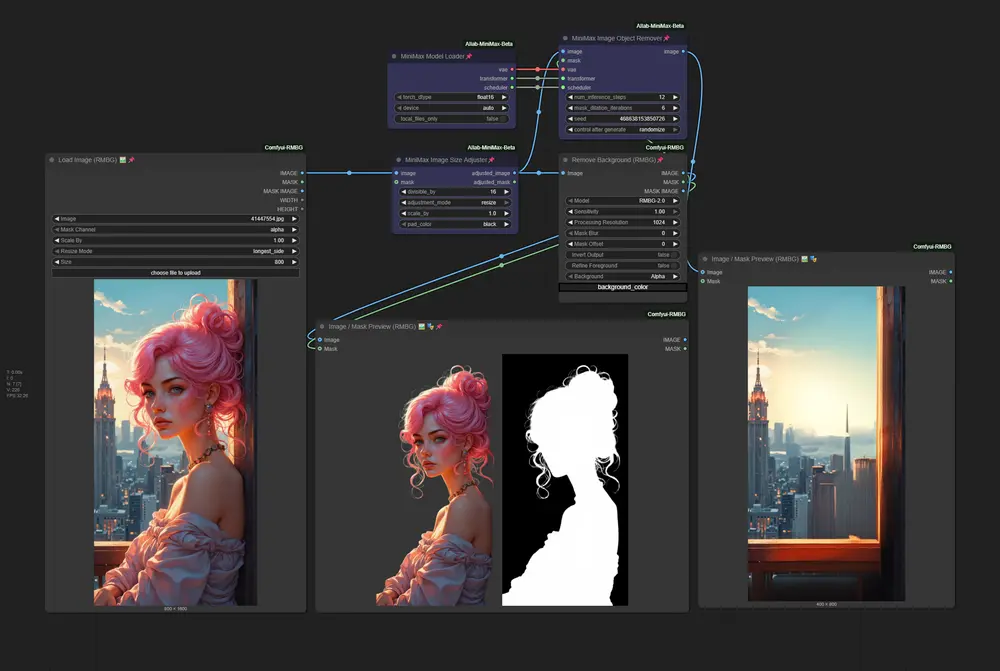
核心特性
| 特性 | 说明 |
|---|---|
| ⚡ 极速推理 | 仅需 6–12 步,无需 CFG,适合快速迭代 |
| 🎯 高质量修复 | 背景重建自然,有效防止伪影与虚假对象 |
| 💪 强鲁棒性 | 基于对抗性优化,在噪声干扰下仍稳定输出 |
| 📱 图像 & 视频支持 | 支持单图修复与多帧视频移除 |
| 🔧 易于集成 | 标准 ComfyUI 节点接口,拖拽即用 |
| 🌐 自动模型管理 | 首次使用自动下载模型,支持手动安装 |
安装方法
✅ 方法一:ComfyUI Manager(推荐)
- 打开 ComfyUI Manager
- 搜索
MiniMax-Remover - 点击 Install
- 重启 ComfyUI
✅ 依赖项与模型将自动处理
🛠️ 方法二:手动安装
# 1. 进入自定义节点目录
cd ComfyUI/custom_nodes
# 2. 克隆仓库
git clone https://github.com/1038lab/ComfyUI-MiniMax-Remover.git
安装依赖
- 便携版 ComfyUI(Windows):
..\..\..\python_embeded\python.exe -m pip install -r requirements.txt - 标准 Python 环境:
pip install -r requirements.txt
重启 ComfyUI 后即可在节点菜单中使用。
模型下载
🌐 自动下载(推荐)
首次使用任一节点时,系统将自动从 Hugging Face 下载所需模型组件至:
ComfyUI/models/MiniMax-Remover/
📦 手动下载(备用方案)
huggingface-cli download zibojia/minimax-remover \
--include vae transformer scheduler \
--local-dir ./models/MiniMax-Remover
或访问 Hugging Face 页面 手动下载以下文件夹并放入对应路径:
vae/transformer/scheduler/
✅ 验证:确保
models/MiniMax-Remover/目录下包含以上三个子文件夹
可用节点一览
| 节点名称 | 功能说明 |
|---|---|
| MinimaxModelLoader | 加载 VAE、Transformer 和 Scheduler,支持精度与设备设置 |
| MinimaxVideoLoader | 加载视频文件,输出帧序列 |
| MinimaxVideoRemover | 视频对象移除主节点(需配合模型加载器) |
| MinimaxImageRemover | 图像对象移除主节点(支持单图处理) |
| ImageSizeAdjuster | 自动调整图像尺寸,确保分辨率可被 16 整除 |
推荐设置
🎛️ Minimax 模型加载器
| 参数 | 推荐值 | 说明 |
|---|---|---|
scheduler_type | FlowMatchEulerDiscreteScheduler | 推理更快,质量稳定 |
torch_dtype | float16 | 显存减半,推荐 GPU 用户 |
device | auto | 自动检测 CUDA/ROCM/CPU |
🖼️ 掩码要求与最佳实践
✅ 支持格式
- 灰度图(推荐)
- RGB 图像(自动转换)
- 格式:PNG、JPG、TIFF 等
📏 掩码规范
- 前景为白色(值 255),背景为黑色(值 0)
- 完全覆盖需移除对象
- 边缘清晰,避免毛刺或噪点
- 分辨率与原图一致
🔧 高级建议
- 使用
mask_dilation_iterations微调边缘覆盖范围 - 若边缘不齐,先用
ImageSizeAdjuster对齐尺寸 - 开启
fix_dimensions=True可自动处理尺寸不匹配问题
性能优化建议
🚀 提升速度
- 使用
FlowMatchEulerDiscreteScheduler(比 UniPC 更快) - 设置
num_inference_steps=6–12 - 分辨率控制在 ≤1024×1024
- 启用
float16精度
💾 显存管理
- 减少 batch size 或帧数
- 处理长视频时分段处理
- 关闭其他 GPU 应用
⚙️ 质量调优
| 问题 | 建议 |
|---|---|
| 修复不完整 | 增加 num_inference_steps 至 16–20 |
| 出现伪影 | 检查掩码质量,避免过小或复杂区域 |
| 时间不连贯 | 确保视频帧序列连续,temporal_frames 设置合理 |
| 颜色偏差 | 使用 float32 测试是否为精度问题 |
系统要求
| 项目 | 要求 |
|---|---|
| Python | 3.8 或更高 |
| GPU | NVIDIA(推荐),支持 CUDA |
| 显存 | ≥6GB(推荐 8GB+) |
| 内存 | ≥8GB |
| 磁盘空间 | ≥5GB(含模型) |
依赖项(自动安装)
通过 requirements.txt 安装以下核心库:
torch>=1.13.0diffusers>=0.21.0decord>=0.6.0(视频加载)einops,scipy,opencv-pythonhuggingface_hub,accelerate
故障排除
| 问题 | 解决方案 |
|---|---|
| 模型下载失败 | 手动下载并放置到 models/MiniMax-Remover/ |
| CUDA 内存不足 | 降低分辨率、使用 float16、减少步数 |
| 张量维度错误 | 使用 ImageSizeAdjuster 对齐尺寸,检查图像通道(应为 RGB) |
| 掩码无效 | 确保为标准黑白掩码,无透明通道(RGBA → RGB) |
| 移除质量差 | 提高掩码精度,尝试不同调度器,增加步数 |
⚠️ 若出现“尺寸不可被 16 整除”警告,请启用
fix_dimensions=True或使用尺寸调整节点。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











