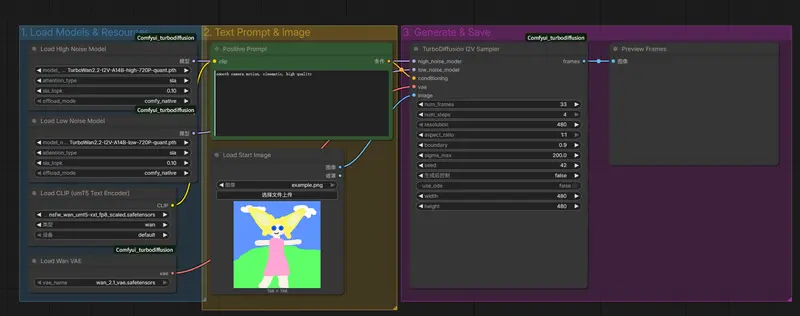
在当前生成模型向更大规模、更高分辨率演进的趋势下,推理效率成为制约用户体验的关键瓶颈。尤其对于基于 DiT(Diffusion Transformer)架构的大模型(如 FLUX、Hidream),传统推理方式在高分辨率生成中面临显存占用高、速度慢等问题。
ComfyUI-TaylorSeer 是 TaylorSeer 方法在 ComfyUI 中的完整集成实现,旨在显著提升 DiT 类模型的推理速度,同时保持生成质量稳定。
它不是简单的缓存优化,而是一种结构化特征重用机制,通过智能跳过冗余计算,在不修改模型结构的前提下实现高效加速。
核心优势:更快、更稳、更可控
| 特性 | 说明 |
|---|---|
| ⚡ 显著提速 | 在 30 步扩散过程中,最高可达 2 倍加速 |
| 📏 质量保留 | 合理配置下,结果与原始输出几乎无损 |
| 💾 显存可预期 | 缓存机制透明,显存增长与分辨率线性相关 |
| 🔗 兼容主流 DiT 模型 | 已支持 FLUX、Hidream,WAN 2.1 即将上线 |
重要提示
请确保你的 ComfyUI 主分支版本 新于提交 c496e53,否则可能出现兼容性问题。
最新更新
- 2025/05/25:新增 block swap 功能,支持在有限显存下运行 Hidream 和 FLUX 模型,进一步降低硬件门槛
- 2025/05/13:正式支持 Hidream 模型,并在 checkpoint 切换时自动卸载旧模型缓存,避免显存泄漏
- 2025/04/30:项目首次发布,支持 FLUX 系列模型
快速开始
安装步骤
- 进入
ComfyUI/custom_nodes目录 - 执行克隆命令:
git clone https://github.com/your-repo/ComfyUI-TaylorSeer.git - 启动或重启 ComfyUI
安装完成后,你可以在节点菜单中找到 TaylorSeer 相关组件,无缝接入现有工作流。
使用说明
显存需求(GPU Memory Usage)
TaylorSeer 的加速机制依赖于在显存中缓存中间特征(Taylor Cache),因此会带来额外显存开销。以下是典型场景下的估算值:
🔹 FLUX 模型(FP8 精度,1024×1024 图像)
| 阶数(Order) | 显存增加量 |
|---|---|
| 阶数 0 | +2 GB |
| 阶数 1 | +4 GB |
| 阶数 2 | +6 GB |
🔹 Hidream 模型(FP8 精度,1024×1024 图像)
| 阶数(Order) | 显存增加量 |
|---|---|
| 阶数 0 | +5 GB |
| 阶数 1 | +10 GB |
| 阶数 2 | +15 GB |
⚠️ 注意:显存占用随分辨率和批量图像数量线性增长。建议在 24GB 显存及以上设备上运行高阶缓存。
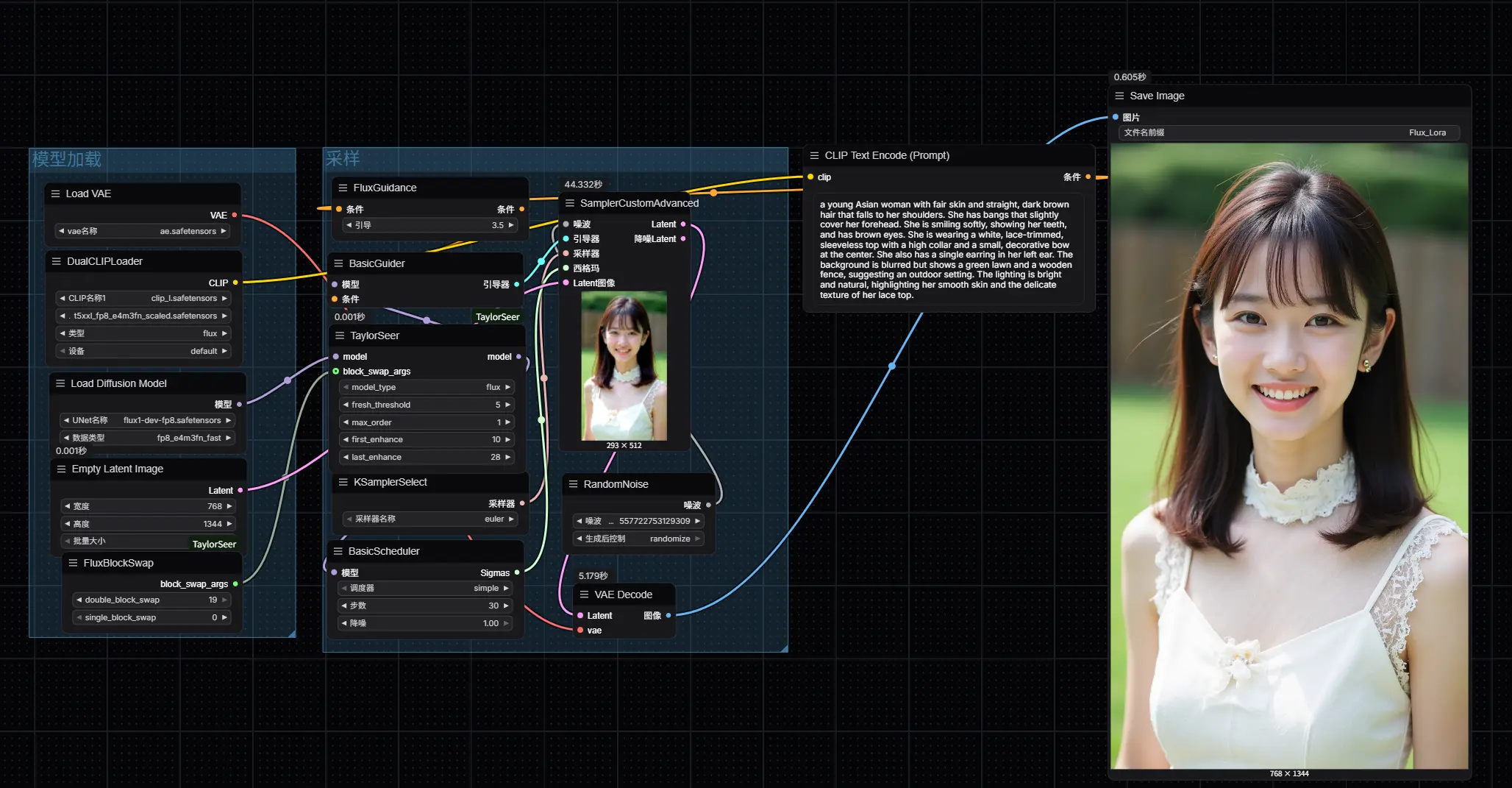
加速控制:first_enhance 参数
该参数决定 Taylor Cache 从第几步开始介入推理过程。
- 推荐设置:
first_enhance = 10 - 在 30 步扩散中,此时介入可实现:
- 推理速度提升约 2 倍
- 视觉质量与原始结果高度一致
- 构图、主体、细节无明显偏移
数值越小,介入越早,加速越明显,但可能轻微影响生成稳定性;建议根据任务需求权衡。
与 TeaCache 的对比
TaylorSeer 并非首个 DiT 加速方案。相比已有的 TeaCache 方法,其在多个维度表现更优:
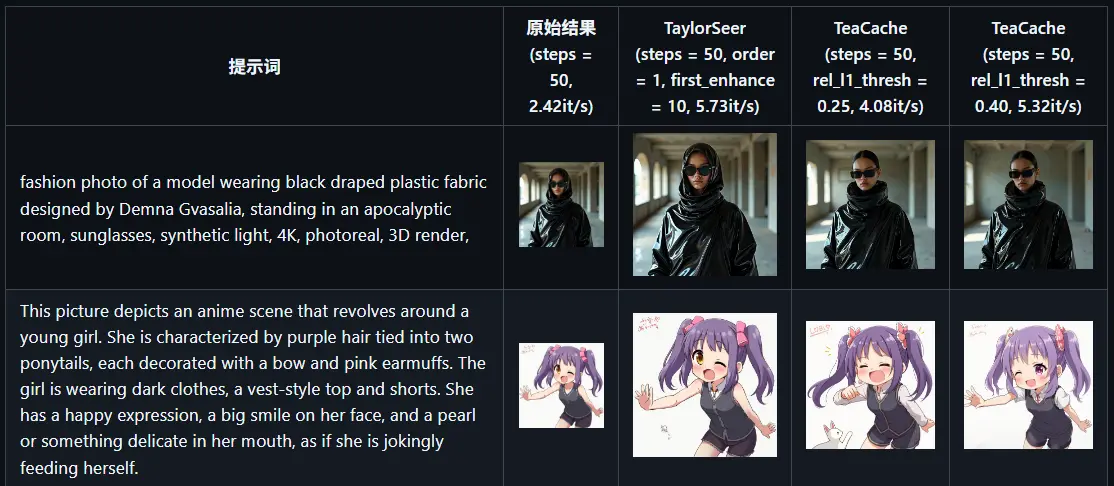
实测表明,TaylorSeer 在复杂场景(如人物姿态、多对象布局)中更能保持原始语义结构,更适合对生成一致性要求较高的应用。
未来规划
- ✅ 支持 WAN 2.1 模型(开发中)
- ✅ 探索 CPU 卸载与分块缓存,进一步降低显存压力
- ✅ 提供更细粒度的缓存策略配置接口
- ✅ 优化多卡并行支持
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











