在图像生成领域,如何将特定角色或物体自然地“插入”已有场景,一直是可控生成的重要挑战。传统方法依赖掩码、姿态估计或多阶段控制,流程复杂且泛化能力有限。
Flux Omini Kontext 提供了一种更轻量、更灵活的解决方案——它不修改模型架构,而是通过调整 Flux.1-Kontext-dev 模型中的 3D RoPE(Rotary Position Embedding)嵌入,实现基于参考图像的角色/物体插入。
- GitHub:https://github.com/Saquib764/omini-kontext
这一思路受 OminiControl 项目启发,但关键区别在于:OminiControl 针对的是使用 2D RoPE 的 Flux.1 dev 模型,而 Omini Kontext 面向的是支持时空建模的 3D RoPE 架构,为图像编辑引入了深度与空间整合能力。
核心能力:从参考图到场景融合
Omini Kontext 的核心功能是:给定一张参考图像(如一个卡通角色)和一段文本提示,将其自然地合成到目标场景中,支持位置与融合程度的控制。
🎯 示例:角色插入
以下为训练后模型的实际输出示例:
提示词:“将角色添加到图像中。角色表现出害怕的情绪。”
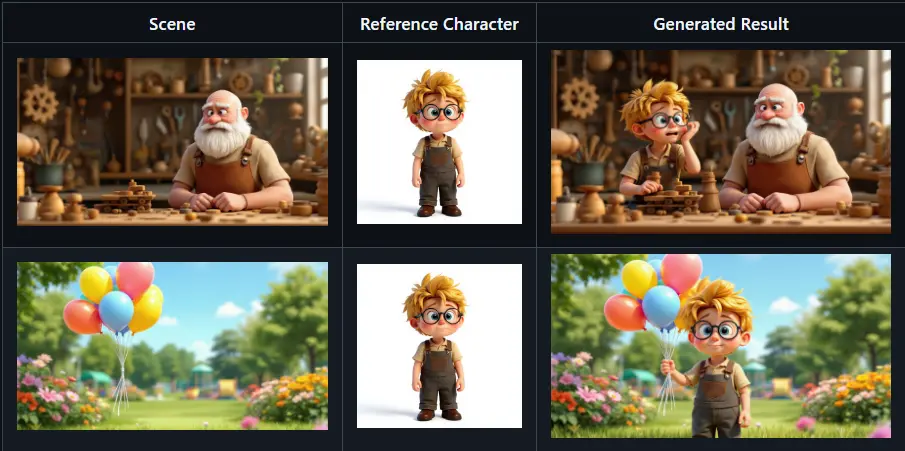
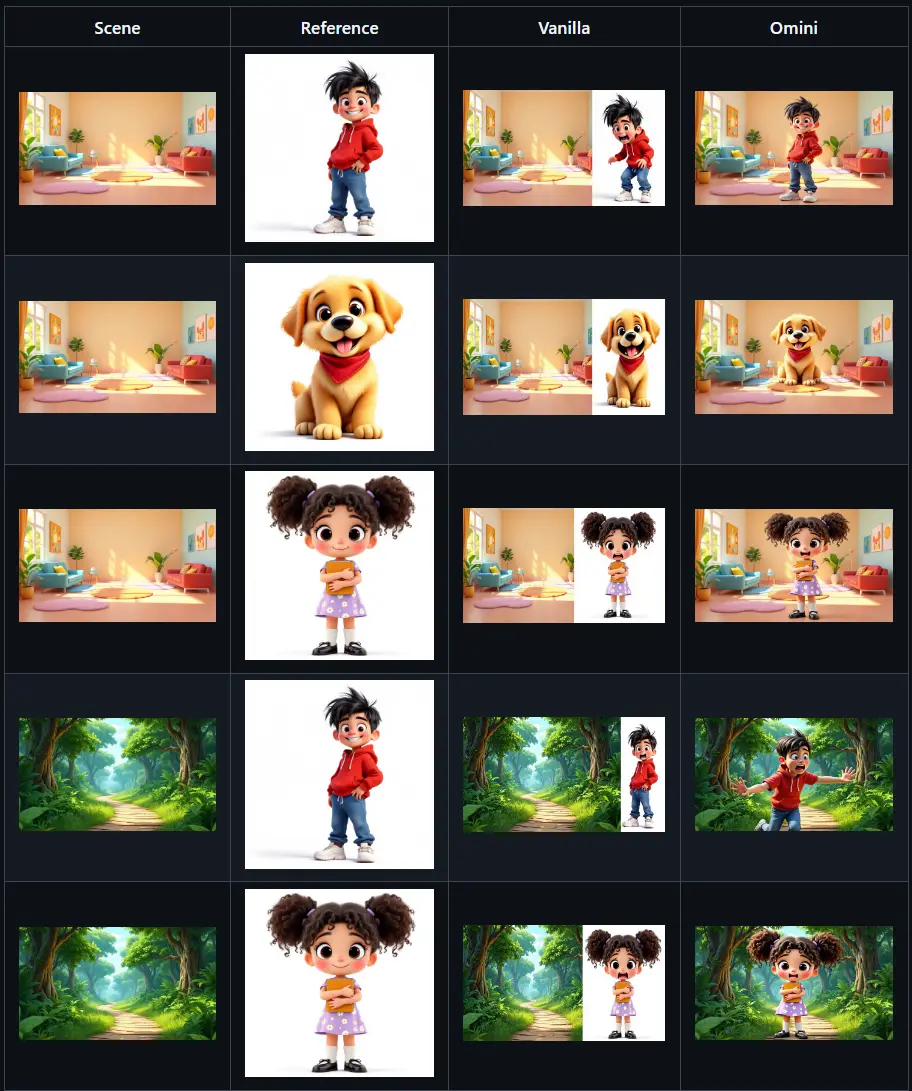
对比原始 Flux.1-Kontext-dev 模型与加入 角色插入 LoRA 的 Omini Kontext 模型:
| 模型 | 插入准确性 | 情绪表达 | 场景协调性 |
|---|---|---|---|
| 原始模型 | ❌ 无明确插入能力 | ❌ 无法响应情绪提示 | ⚠️ 常出现畸变或错位 |
| Omini Kontext + LoRA | ✅ 高精度定位 | ✅ 情绪匹配良好 | ✅ 融合自然,光照协调 |
这表明,通过 LoRA 微调与 RoPE 调整,模型已学会从参考图中提取语义特征,并在指定位置进行可控生成。
技术原理:利用 3D RoPE 实现空间感知编辑
Omini Kontext 并未改动模型主干结构,而是巧妙利用了 Flux.1-Kontext-dev 中的 3D 旋转位置编码(3D RoPE)。
什么是 3D RoPE?
不同于标准的 2D 位置编码,3D RoPE 将空间坐标扩展至三维:
- X、Y:图像平面位置
- Z:可理解为“深度”或“注意力权重层级”,用于控制元素的“融入强度”
Omini Kontext 通过在推理时调整参考图像对应的 RoPE 偏移量(delta),实现对插入对象的:
- 位置控制(X/Y 偏移)
- 深度整合(Z 值调节,控制是“浮在表面”还是“融入场景”)
这种方法无需额外控制网络(如 ControlNet),即可实现轻量级的空间感知编辑。
框架特性:高效、灵活、可扩展
Omini Kontext 不只是一个模型,更是一套完整的训练与推理框架,具备以下核心功能:
| 特性 | 说明 |
|---|---|
| 🚀 基于 Lightning 的训练 | 使用 PyTorch Lightning,支持分布式训练与快速迭代 |
| 🎯 LoRA 微调 | 仅增加约 0.1% 参数量,内存友好,适合消费级 GPU |
| 🖼️ 多图像输入 | 支持输入图像 + 参考图像双输入,带位置偏移控制 |
| 📝 文本条件处理 | 结合 CLIP 与 T5 编码器,支持复杂语义提示 |
| ⚡ 梯度检查点 | 显存不足时启用,降低训练内存占用 |
| 🔧 多种优化器 | 支持 AdamW、Prodigy、SGD,适配不同训练需求 |
| 📊 实验监控 | 集成日志系统,便于跟踪 loss、生成质量等指标 |
| 🎨 分辨率灵活 | 支持多种宽高比与分辨率输入输出 |
当前进展与未来规划
✅ 已实现
- 基础训练与推理脚本开源
- LoRA 微调流程稳定
- ComfyUI 集成可用
- 支持角色插入任务
🔜 待办事项
- 实现参考对象的位置与大小显式控制
- 优化预处理流程,移除无关像素以加速推理
- 部署公共在线演示(Demo)
- 发布 Replicate 版本,便于云端调用
- 扩展更多专用模型(见下文)
未来模型路线图
Omini Kontext 将逐步扩展为多任务图像编辑平台,计划训练以下专用模型:
| 模型类型 | 目标 |
|---|---|
| 人物模型 | 用于真实人类主体的插入与编辑 |
| 服装模型 | 支持服饰、配饰等时尚元素替换 |
| 物体模型 | 针对家具、电子产品等常见物品 |
| 角色模型 | 专精动漫、卡通风格角色合成 |
每个模型均可通过 LoRA 形式发布,用户可按需加载。
ComfyUI 集成:无缝接入工作流
为便于使用,开发者开发了 ComfyUI-Omini-Kontext 插件,实现图形化操作,支持复杂工作流编排。
✅ 主要功能
- 角色/物体插入,支持空间控制
- LoRA 加载与强度调节
- 内存优化:VAE 切片 + 瓦片生成
- 支持 text2img 与 img2img 模式
- reference_delta 参数控制插入位置
🔧 可用节点说明
1. Omini Kontext 管道加载器
加载主模型,可选加载 LoRA 权重。
- 输入:
model_path(HuggingFace ID 或本地路径),lora_path(可选) - 输出:
OMINI_KONTEXT_PIPELINE
2. Omini Kontext 管道(主生成节点)
执行图像生成的核心节点。
- 必填输入:
- pipeline
- prompt(文本提示)
- reference_image(参考图)
- reference_delta_x/y/z(位置偏移,默认 0, 0, 96)
- 生成参数(步数、CFG、分辨率、种子等)
- 可选输入:
- input_image(img2img 模式)
- negative_prompt
- true_cfg_scale
- 输出:生成图像
3. Omini Kontext 图像缩放
将任意图像缩放到适合 Kontext 模型的最佳分辨率。
- 输入:任意尺寸图像
- 输出:标准化尺寸图像(如 1024×1024)
4. Omini Kontext LoRA 加载器
动态向管道注入 LoRA 权重。
- 输入:pipeline、lora_name、strength(强度)、adapter_name
- 用途:多 LoRA 切换、混合使用
5. 高级编码器节点(用于定制流程)
- 图像编码器:将图像转为潜在表示
- 文本编码器:编码 prompt
- 参考编码器:处理 reference_image 与 delta
- 潜在组合器:融合输入与参考 latent
使用建议与技巧
📍 参考偏移参数(reference_delta)
| 维度 | 作用 | 典型取值 |
|---|---|---|
| X | 水平偏移 | -100 ~ 100 |
| Y | 垂直偏移 | -100 ~ 100 |
| Z | 深度/融合强度 | 48 ~ 144(默认 96) |
提示:增大 Z 值可使对象更“融入”背景;减小则更像“贴图”。
💾 显存管理
- 自动启用 VAE 切片与瓦片技术
- 24GB 显存:支持最高 1024×1024 分辨率
- 16GB 显存:建议 768×768 或更低
🔊 LoRA 强度建议
1.0:标准强度(推荐起点)0.5–0.8:轻微影响,适合细节增强1.2–1.5:强干预,适用于风格化插入
常见问题与解决
| 问题 | 解决方案 |
|---|---|
No module named 'diffusers' | 运行 pip install git+https://github.com/huggingface/diffusers.git |
CUDA out of memory | 降低分辨率,关闭其他程序,或启用 CPU offload(未来支持) |
401 Unauthorized 加载模型 | 运行 huggingface-cli login 并输入 HuggingFace Token |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











