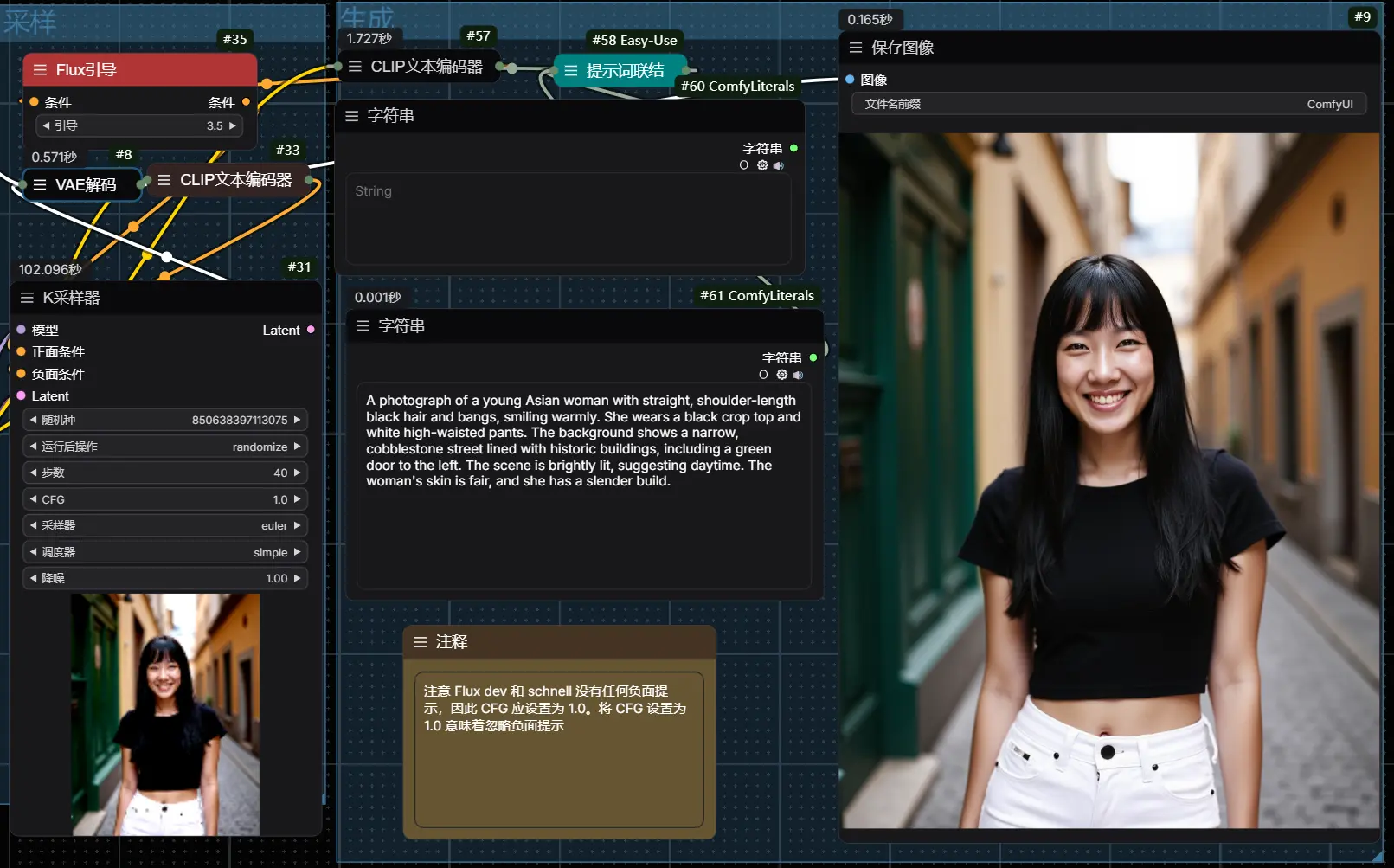
新加坡国立大学的研究团队提出了一种名为OminiControl的新型框架,它旨在为预训练的DiT模型(FLUX模型)提供最小化和通用的控制。OminiControl通过整合图像条件,使得DiT模型能够处理各种图像生成任务,包括主题驱动生成和空间对齐任务(如边缘、深度等)。例如,你想要生成一张在咖啡馆里拿着啤酒的女孩的图片,或者想要对一张模糊的照片进行去模糊处理,OminiControl框架都能够根据这些具体的图像条件来生成或修改图片。
- GitHub:https://github.com/Yuanshi9815/OminiControl
- 模型:https://huggingface.co/Yuanshi/OminiControl
- Demo:https://huggingface.co/spaces/Yuanshi/OminiControl
目前已有两款ComfyUI插件支持此框架,但由于该框架并没有得到ComfyUI原生支持,两款插件对于显存要求都较高:
- ComfyUI Diffusers OminiControl:https://github.com/Macoron/ComfyUI-Diffusers-OminiControl
- ComfyUI_RH_OminiControl:https://github.com/HM-RunningHub/ComfyUI_RH_OminiControl
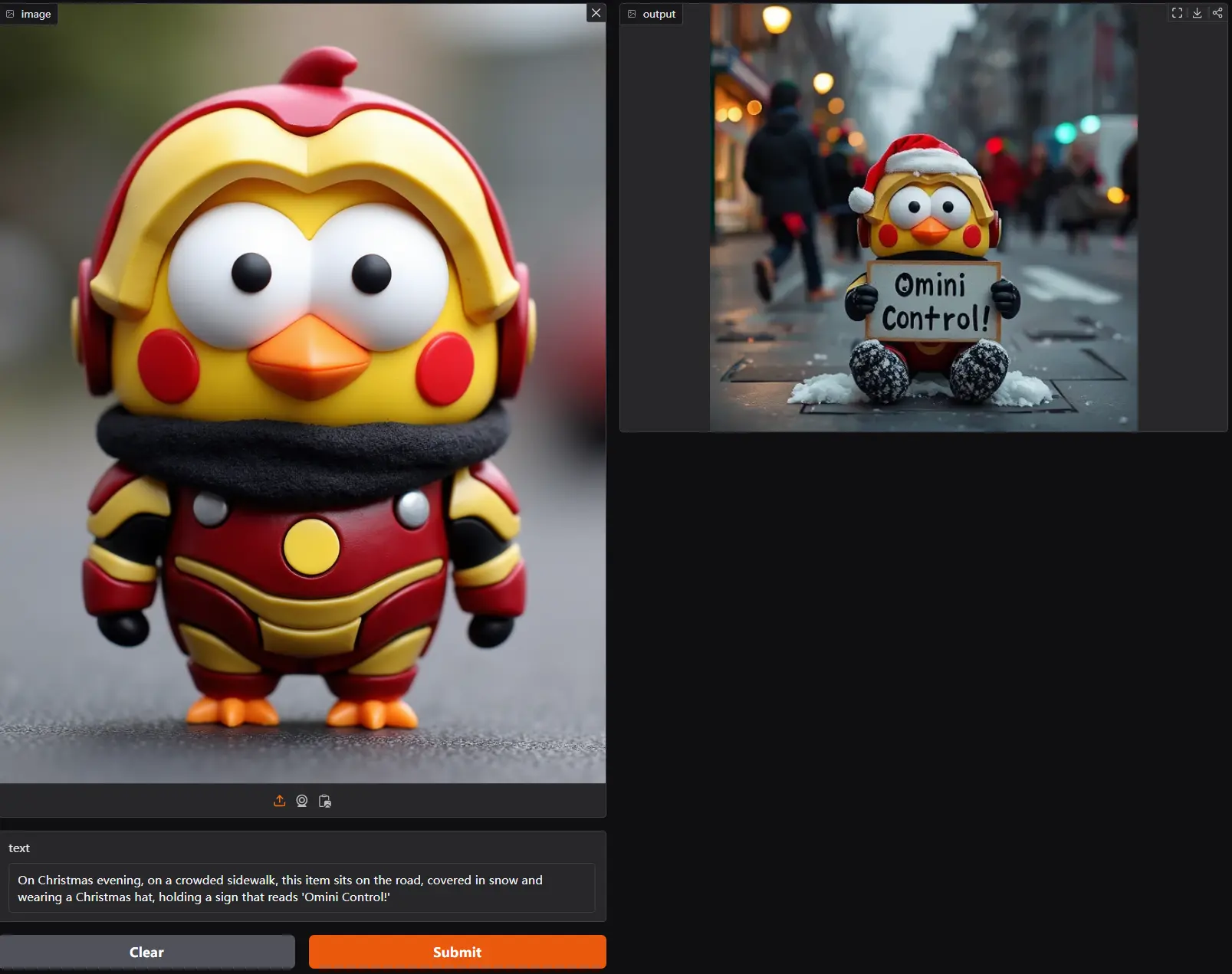
核心特点:
- 高效参数重用:OminiControl仅需增加0.1%的额外参数即可实现图像条件的有效集成。这种方法不仅减少了模型的复杂性和计算成本,还提高了模型的泛化能力和性能。
- 广泛的任务支持:OminiControl能够以统一的方式处理多种图像条件任务,包括主体驱动的生成和空间对齐的条件(如边缘、深度等)。这种灵活性使得OminiControl在各种应用场景中都能表现出色。
- 自监督训练:OminiControl的能力是通过在DiT自身生成的图像上进行训练实现的,尤其是对于主体驱动的生成任务,这种方法能够显著提升模型的表现。

主要功能:
- 图像条件编码:将图像条件有效地编码并整合到DiT模型中。
- 多模态注意力处理:通过灵活的多模态注意力处理器处理不同的图像条件。
- 参数高效:与依赖于复杂架构的额外编码器模块的方法不同,OminiControl以极少的额外参数实现图像条件的整合。
主要特点:
- 统一框架:能够在一个统一的框架内处理空间对齐和非空间对齐的控制任务。
- 参数效率:仅需要极少的额外参数(0.1%)就能实现图像条件的整合。
- 性能优越:在多种图像生成任务中,OminiControl的性能超过了现有的基于UNet和DiT适应模型。
工作原理:
OminiControl通过以下步骤工作:
- 参数重用机制:利用模型已有的VAE编码器处理条件图像,将其投影到与噪声图像标记相同的潜在空间中。
- 特征增强:通过可学习的位置嵌入增强编码的特征,并将其与潜在噪声一起整合到去噪网络中。
- 多模态注意力交互:在DiT的变换器块中,条件和生成标记之间直接进行多模态注意力交互,促进信息交换和控制信号传播。
优势与贡献
- 优于现有模型:广泛的评估结果显示,OminiControl在主体驱动的和空间对齐的条件生成任务上均优于现有的基于UNet和DiT适配的模型。
- 数据集发布:研究团队还发布了名为Subjects200K的数据集,该数据集包含超过200,000张身份一致的图像,以及一个高效的数据合成管道。这些资源的发布将进一步推动主体一致生成研究的发展。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
![蓝莓真身!Black Forest Labs推出FLUX1.1 [pro]和BFL API,生成质量更高速度更快](https://pic.sd114.wiki/wp-content/uploads/2024/10/1727983937-FLUX1-1.webp~tplv-o4t1hxlaqv-image.image)



暂无评论...











