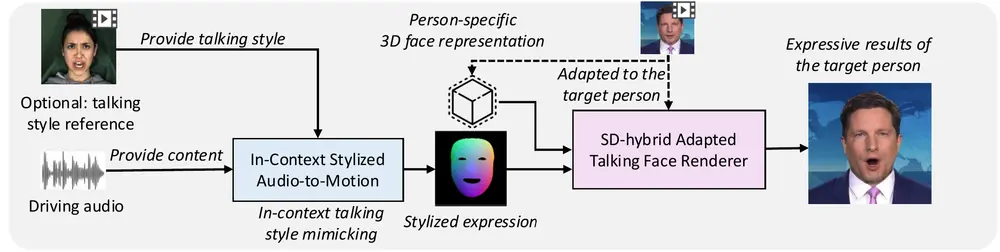
上海交通大学、山东大学、电子科技大学和香港科技大学的研究人员推出加速DiT架构模型推理速度的新方法TaylorSeer,扩散模型在图像和视频生成任务中表现出色,但其计算需求较高,限制了实时应用的可行性。TaylorSeer 通过预测未来时间步的特征来加速扩散模型,而不是简单地重用之前的特征,从而在保持生成质量的同时显著提高推理速度。
以生成高清图像为例,传统的扩散模型需要逐帧计算特征,这在实时应用中非常耗时。TaylorSeer 则通过预测后续时间步的特征,减少了重复计算,从而加快了生成速度。例如,在生成一个包含复杂场景的图像时,TaylorSeer 可以在短时间内生成高质量的图像,而传统方法可能需要更长的时间来完成同样的任务。
主要功能
- 加速扩散模型的推理速度:通过预测未来时间步的特征,减少重复计算。
- 保持生成质量:即使在高加速比下,也能保持与原始模型相近的生成质量。
- 无需额外训练:TaylorSeer 是一种训练无关的方法,可以直接应用于现有的扩散模型。
主要特点
- “Cache-then-Forecast”范式:与传统的“Cache-then-Reuse”方法不同,TaylorSeer 通过预测未来特征来加速模型,而不是简单地重用之前的特征。
- 高阶泰勒展开:利用泰勒展开来近似特征的变化轨迹,能够更准确地预测未来特征,尤其适用于长距离时间步的加速。
- 适应性强:适用于多种扩散模型,包括基于 U-Net 和 Transformer 的模型。
工作原理
TaylorSeer 的核心思想是利用扩散模型特征在时间步上的连续性和可预测性。具体来说:
- 特征轨迹预测:通过计算特征在不同时间步的导数,并利用泰勒展开来预测未来时间步的特征。
- 高阶导数近似:使用有限差分法来近似高阶导数,从而在不增加额外计算成本的情况下提高预测精度。
- 动态缓存和预测:在推理过程中,动态选择需要计算的时间步,并预测其他时间步的特征,从而减少计算量。
测试结果
实验表明,TaylorSeer 在多种扩散模型上表现出色:
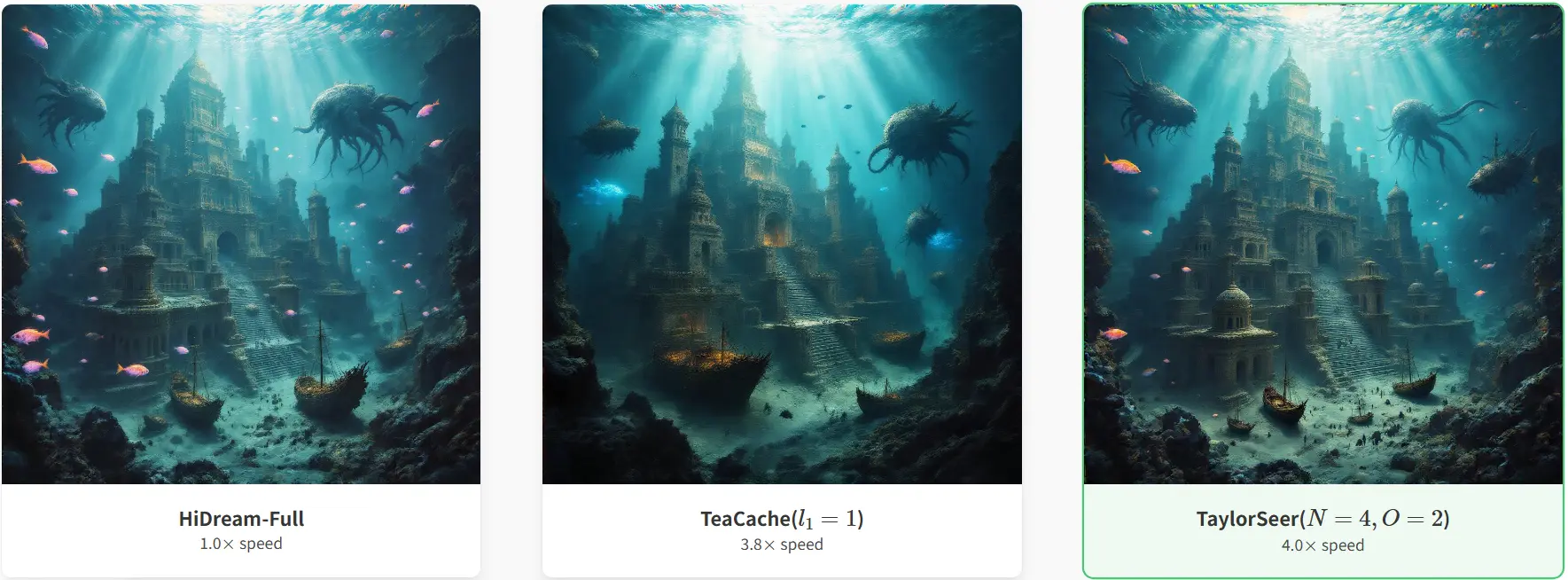
- FLUX 模型:在 4.99× 加速比下,图像生成质量几乎无损,Image Reward 为 0.9953,CLIP Score 为 19.637。
- HunyuanVideo 模型:在 5.00× 加速比下,视频生成质量保持在 79.93% 的 VBench 评分。
- DiT 模型:在 4.53× 加速比下,FID 为 2.65,显著优于其他加速方法。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











