
在大语言模型(LLM)领域,扩散型大语言模型(Diffusion Large Language Models, DLLMs)正凭借其并行生成能力与全局上下文建模优势,成为传统自回归模型(AR)的有力竞争者。然而,一个长期制约其落地的关键瓶颈始终存在:生成长度必须在推理前静态预设。

过短的长度限制了复杂任务的表现力,而过长则带来冗余计算,甚至损害性能。如何让 DLLM “自主决定该说多少”?香港中文大学与上海 AI 实验室的研究团队给出了答案——
他们提出了 DAEDAL(Dynamic Adaptive Length Expansion for Diffusion LLMs),一种无需训练、两阶段、自适应长度扩展的去噪策略,首次实现了 DLLM 在推理过程中的动态长度调整。
核心挑战:静态长度的两难困境
传统 DLLMs 在生成前需指定输出 token 数量(如 512)。这一“先定后做”的模式导致:
- 🔹 长度不足:面对数学推理、长文本摘要等复杂任务,模型“话没说完就被打断”。
- 🔹 长度过长:简单问答被迫填充冗余 token,浪费算力,甚至引入噪声。
- 🔹 依赖人工调优:需为不同任务手动配置最优长度,成本高且难以泛化。
DAEDAL 的核心洞察是:模型自身知道它需要多长。
研究发现,在去噪过程中,模型对 [EOS](结束符)的预测置信度,能有效反映当前长度是否充足。DAEDAL 正是利用这一内部信号,构建了一套无需额外训练的动态扩展机制。
DAEDAL 的两阶段动态扩展机制
DAEDAL 采用两阶段策略,在不修改模型权重的前提下,实现长度的智能调控。
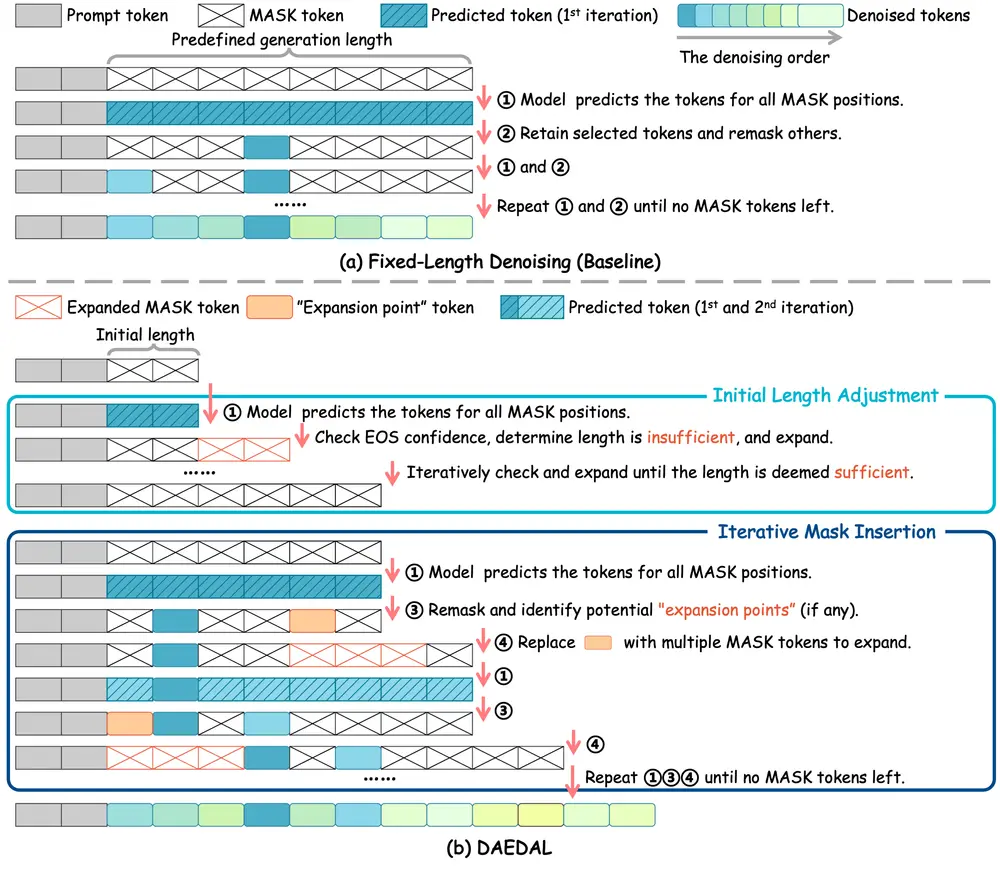
第一阶段:初始长度调整(Initial Length Adjustment)
在正式去噪开始前,DAEDAL 执行一次“快速探针”:
- 从一个统一的短初始长度(如 128 tokens)开始。
- 检查序列末尾的
[EOS]预测置信度。 - 若置信度低,说明模型“觉得不够用”,则向序列末尾添加多个
[MASK]标记以扩展长度。 - 重复此过程,直到
[EOS]置信度达标或达到最大长度。
✅ 结果:为每个任务分配一个合理的全局起始长度,避免从一开始就“先天不足”。
第二阶段:迭代掩码插入(Iterative Mask Insertion)
在多步去噪过程中,DAEDAL 持续监控每个 [MASK] 位置的预测不确定性:
- 若某个
[MASK]的预测概率分布高度分散(即模型“很犹豫”),则将其标记为“扩展点”。 - 将该单个
[MASK]替换为一组新的[MASK]标记(如 3-5 个),为模型提供“讨论空间”。 - 在后续去噪步中,这些新插入的 token 将被逐步填充。
✅ 结果:在需要展开论述、填补逻辑间隙的局部区域,实现精细化的动态扩容。
核心特点
| 特性 | 说明 |
|---|---|
| 🔄 动态长度调整 | 根据任务复杂度自动决定输出长度,无需预设 |
| ⚙️ 无需训练 | 纯推理策略,可直接应用于现有 DLLMs,零训练成本 |
| 🧩 两阶段设计 | 全局粗调 + 局部精修,兼顾效率与完整性 |
| 📡 利用内部信号 | 基于 [EOS] 置信度和 token 预测不确定性,实现自适应决策 |
| 💡 提升有效计算率 | 减少无效 token 生成,提高“有效标记比率”(Effective Ratio) |
实验结果:性能与效率双提升
在多个标准基准上的测试表明,DAEDAL 不仅有效,而且高效。
✅ 性能超越固定长度基线
- 在 GSM8K(数学推理)任务上:
- DAEDAL 准确率:85.8%
- 最优固定长度基线:83.8%
- 提升 2.0 个百分点
这表明,动态扩展能显著增强模型处理复杂任务的能力。
✅ 更高的计算效率
- DAEDAL 生成的总 token 数(Ntoken)通常低于固定长度基线的最优设置。
- 同时保持甚至提升任务性能,意味着其有效标记比率(Eratio = 有用输出 / 总计算量)显著更高。
- 避免了“为 200 token 的回答支付 512 token 的算力”问题。
✅ 强大的自适应能力
- DAEDAL 生成的响应长度分布更广,能根据问题自然伸缩。
- 简单问题输出简洁,复杂问题充分展开,行为更接近人类表达习惯。
意义与展望
DAEDAL 的提出,标志着 DLLMs 从“僵化流程”向“智能应答”迈出了关键一步。
它不仅解决了静态长度这一核心痛点,更重要的是:
- 证明了模型内部信号可用于指导推理过程优化。
- 提供了一种无需训练即可增强模型能力的通用范式。
- 缩小了 DLLMs 与自回归模型在生成灵活性上的关键差距。
未来,这一动态生成思想有望扩展至视频、音频等多模态扩散模型,推动生成式 AI 向更高效、更智能的方向发展。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











