ComfyUI-LaoLi-Shadow(简称“影子插件”)是一款专为ComfyUI打造的底层性能优化插件,核心解决两大行业痛点:一是工作流启动慢、模型加载耗时久;二是大模型(SDXL/Flux/WanVideo/Qwen等)采样时显存占用过高,频繁出现OOM(爆显存)崩溃。
插件通过自研“影子加载”技术实现工作流极速启动,搭配“显存排队”机制与模型动态卸载策略,同时支持多类型模型深度优化,让小显存显卡也能流畅运行大模型、多模型协作任务,是ComfyUI用户提升运行效率、降低硬件门槛的必备工具。
⚠️ 重要提醒:该插件为底层级优化,ComfyUI启动时即生效,会全局接管模型加载与显存管理逻辑,影响所有工作流;若需关闭,需直接删除插件,仅关闭节点开关仍会保留部分底层优化效果。
核心特性:三大核心能力,全面提升ComfyUI运行性能
1. 全自动影子模式:极速启动,零显存零硬盘占用
插件核心的“影子加载”技术,颠覆传统模型加载逻辑:加载Checkpoint、ControlNet等模型时,不读取硬盘、不占用显存,仅在工作流真正进入采样阶段时,才触发模型的实际加载。
- 优势:工作流启动速度大幅提升,尤其是包含多个大模型的复杂工作流,启动耗时从分钟级降至秒级;启动阶段显存占用为0,避免启动时就因显存不足报错。
2. 智能显存共存:动态卸载,小显存也能多模型协作
内置智能显存管理算法,自动识别模型使用状态,实时卸载未参与计算的模型,解决VLM、LLM、绘图模型等多模型协作时的显存冲突问题。
- 优势:8G/12G小显存显卡,也能流畅运行“VLM反推+ControlNet绘图+大模型采样”的复杂工作流,无需手动卸载模型,全程自动化。
3. 通用模型支持:全场景兼容,覆盖主流大模型
自研Dominant Layer Search(核心层搜索)全局算法,深入模型底层识别核心计算层,完美支持各类主流模型与复杂封装模型:
- 绘图模型:SD1.5、SDXL、Flux;
- 视频/多模态模型:WanVideo、Qwen;
- 封装模型:各类第三方Wrapper封装的定制化模型,无需适配修改,直接兼容。
核心节点详解:三大节点分工明确,全局优化+精准控制
插件包含三大核心节点,分别负责全局控制、推理显存优化、流程执行管控,覆盖从启动到采样的全流程优化,节点可单独使用,也可组合搭配。
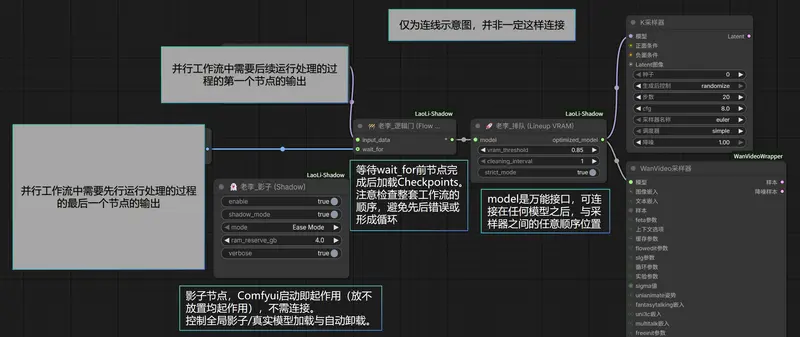
1. 影子(Shadow)—— 全局控制器,底层优化总开关
核心作用:无需任何连线,添加到工作流中即生效,全局接管ComfyUI底层模型加载与显存管理逻辑,是插件的核心控制节点。
参数详解
- enable(启用):插件总开关。⚠️ 关键提醒:关闭该开关后,底层优化逻辑仍会部分生效;若完全不想使用插件,需直接删除插件文件,仅关闭开关无效。
- shadow_mode(影子模式):插件核心功能开关。
True(开启):启用延迟加载,工作流启动时,所有模型均为“影子状态”,硬盘读取与显存占用均为0,仅采样时加载真身。False(关闭):切换为传统加载模式,模型启动时直接加载,与原生ComfyUI逻辑一致。
- mode(运行模式):显存管理策略,二选一。
Ease Mode(安逸模式,推荐):智能显存管理,显存不足时自动卸载未使用模型(如VLM反推完成后自动卸载,释放显存给绘图模型),兼顾性能与稳定性。Monitor Mode(监控模式):仅监控显存占用,不主动执行卸载操作,仅提升运行流畅度,无法显著降低显存占用,不推荐常规使用。
- ram_reserve_gb(内存保留):系统防卡死安全气囊。
- 作用:当系统物理内存(RAM)剩余量低于设定值(如4.0GB)时,强制触发垃圾回收(GC),释放内存,防止电脑因内存耗尽死机。
- 建议:16G内存设为4.0GB,32G及以上内存设为6.0GB-8.0GB。
- verbose(日志):控制台日志开关,建议开启,可查看模型加载、显存清理、垃圾回收的实时日志,便于排查问题。
2. 排队(Lineup VRAM)—— 推理显存保姆,杜绝采样爆显存
核心作用:利用全局算法深入扫描模型内部,在每一层计算前实时检查显存,防止KSampler采样过程中,因显存瞬间峰值导致的OOM崩溃,是大模型采样的“显存保镖”。
核心优势
- 万能兼容:无论标准Checkpoint,还是深层封装的Qwen、WanVideo、Flux包装器,都能自动识别核心计算层,无需手动适配。
- 影子穿透:若连接的是“影子状态”模型,会强制加载模型真身,并执行显存优化,不影响影子模式的核心优势。
连接说明
- 输入(model):连接大模型加载节点(如Load Checkpoint、Load ControlNet),或任意模型处理节点的输出。
- 输出(optimized_model):连接到KSampler或其他需要调用模型的节点,替代原生模型输出。
参数详解
- vram_threshold(显存阈值):显存警戒线,默认0.85(总显存的85%)。
- 作用:显存占用达到阈值时,自动触发模型清理与垃圾回收。
- 建议:8G-12G显存设为0.80;16G-24G显存设为0.85或0.90;24G以上显存可设为0.95。
- cleaning_interval(清理间隔):显存检查频率。
1:每计算1层检查1次显存,最安全,防崩效果最好,推荐所有用户使用。2:每计算2层检查1次,运行速度稍快,但显存激增时可能来不及清理,风险略高,仅推荐高显存用户尝试。
- strict_mode(严格模式):清理策略开关,默认
True(推荐)。True:显存超标时,强制暂停GPU(Synchronize)执行清理,彻底杜绝爆显存,稳定性拉满。False:仅发送清理请求,不暂停GPU,速度略快,但无法拦截突发显存激增,易出现崩溃。
3. 逻辑门(Flow Gate)—— 流程红绿灯,解决并行资源冲突
核心作用:强制控制ComfyUI工作流的执行顺序,解决并行任务导致的显存、模型资源冲突,是多模型协作工作流的“流程管家”。
典型应用场景
强制要求“先执行B任务,再执行A任务”,例如:先运行VLM图像反推生成提示词,待VLM模型释放显存后,再加载ControlNet模型进行绘图,避免两个模型同时占用显存。
连接说明
- input_data(输入):连接需要延迟执行的资源(如ControlNet模型、Checkpoint大模型、采样节点)。
- wait_for(等待):连接必须优先执行的任务输出(如VLM节点输出的提示词、预处理节点的结果)。
- 输出:连接到原本
input_data需要接入的节点(如KSampler)。
安装步骤:一键克隆,重启即生效
1. 克隆插件仓库
打开终端,进入ComfyUI的custom_nodes目录,执行克隆命令:
# 切换到ComfyUI自定义节点目录(替换为你的ComfyUI实际路径)
cd ComfyUI/custom_nodes
# 克隆影子插件仓库
git clone https://github.com/Laolilzp/ComfyUI-LaoLi-Shadow.git
2. 重启ComfyUI
克隆完成后,关闭当前运行的ComfyUI服务,重新启动即可。
- 启动后,在ComfyUI节点搜索框中输入“影子”“Lineup”“Flow Gate”,即可找到三大核心节点,说明安装成功。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











