ComfyUI-QwenASR是一款专为Qwen3-ASR(自动语音识别)模型打造的ComfyUI自定义节点包,核心定位是为ComfyUI用户提供简单、可靠、高效的语音转文本及字幕生成工作流,无需复杂的外部工具或命令行操作,仅通过可视化节点拖拽即可完成语音处理任务。
这款节点包聚焦于实际使用场景的便捷性,不仅支持基础的语音转文本,还针对长音频处理、精准字幕生成等核心需求做了优化,同时提供本地模型缓存、双下载源支持,既降低了模型使用门槛,又提升了国内用户的下载与运行体验,适合内容创作者、音频从业者以及ComfyUI爱好者,用于处理播客、会议录音、短视频音频等各类语音内容。
通义千问开源 Qwen3-ASR 与 Qwen3-ForcedAligner:支持流式、多语言、高并发的语音识别与对齐工具
相较于其他语音识别节点,ComfyUI-QwenASR的核心优势在于“轻量简易”与“功能实用”,无需繁琐配置,新手也能快速上手,同时满足长音频、精准时间轴字幕等核心需求,完美融入ComfyUI的自动化工作流生态。
核心功能特性:简易高效,覆盖语音处理核心需求
ComfyUI-QwenASR的功能围绕“简化语音转写流程、提升字幕生成精度”展开,核心特性兼顾便捷性与实用性,具体如下:
- 双核心节点设计,按需选择:提供两个核心功能节点,分别对应“简易语音转文本”与“字幕生成”,用户可根据自身需求选择对应的节点,无需加载冗余功能,轻量高效。
- 长音频自动分块处理:无需手动将长音频切割分段,节点会在模型管道内部自动进行分块处理,轻松应对长篇会议录音、播客、有声书等长时程音频内容,提升处理效率。
- 强制对齐器,生成精准字幕:内置强制对齐器模型,能够为转录内容生成带精准时间轴的字幕,解决普通字幕时间轴偏差较大的问题,满足视频字幕制作等高精度需求。
- 本地模型缓存,重复使用更便捷:下载的模型会统一缓存到
ComfyUI/models/Qwen3-ASR/目录下,后续使用无需重复下载,节省网络带宽,同时支持离线运行(模型下载完成后)。 - HuggingFace / ModelScope 双下载源支持:适配不同网络环境的用户,国内用户优先选择ModelScope下载源,可获得更快的下载速度与更稳定的连接,避免网络超时问题。
- 灵活输出配置,满足多样需求:字幕生成节点支持多种输出格式(none/txt/srt)与自定义输出路径,兼顾普通用户的直接使用与高级用户的后续处理需求。
核心节点介绍:功能清晰,快速上手
ComfyUI-QwenASR仅包含两个核心节点,功能划分明确,操作简单,在ComfyUI搜索框中输入ASR即可快速找到这两个节点,无需在繁杂节点列表中查找。
节点1:ASR (QwenASR)——快速语音转文本
该节点的核心用途是完成基础、快速的语音转文本任务,不生成时间轴,适合仅需要提取音频文字内容的场景(如整理会议核心纪要、提取播客文字稿等)。
- 输入项:仅需连接ComfyUI的标准
AUDIO输出(如来自LoadAudio节点,用于加载本地MP3、WAV等常见格式音频文件)。 - 优化提示:可在节点中输入关键词、人名、专业术语等信息,帮助模型提升特殊内容的识别准确率,减少转录误差。
- 输出项:仅输出
text(纯文本内容),可直接连接ShowText节点查看结果,或连接SaveText节点保存为本地文本文件。
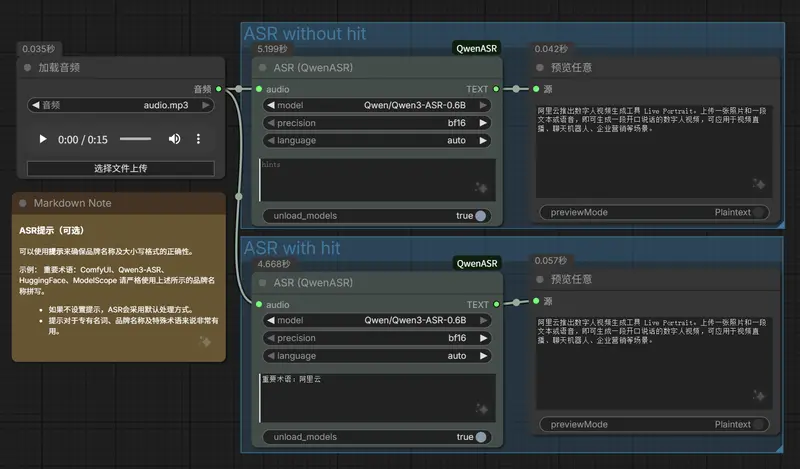
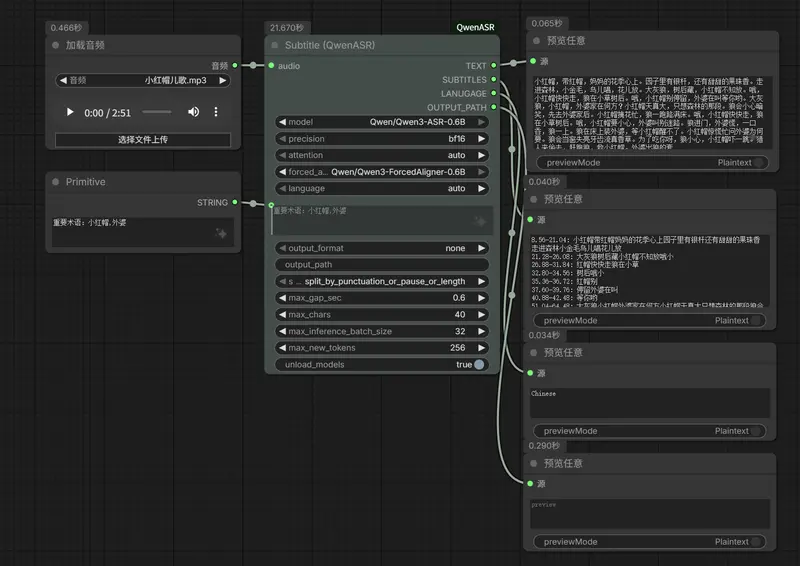
节点2:Subtitle (QwenASR)——带时间戳精准字幕生成
该节点的核心用途是生成带精准时间轴的字幕,适合视频字幕制作、需要对应语音与文本时间点的场景,功能更丰富,配置更灵活。
- 输入项:
- 核心输入:
AUDIO(连接LoadAudio节点加载的音频文件)。 - 优化选项:可输入关键词、人名、专业术语等,提升特殊内容识别准确率。
- 高级选项:强制对齐器(开启后提升时间轴精度)、最大批处理大小(调整运行效率,适配不同硬件)、最大新生成词数(控制转录文本长度)。
- 核心输入:
- 输出项:
text:纯文本转录内容(无时间轴)。subtitles:带精准时间轴的字幕内容。language:识别出的音频语言。OUTPUT_PATH:字幕文件的保存路径(可自定义)。
- 额外配置:
- 输出格式:支持
none(仅在ComfyUI内查看,不保存文件)、txt(保存为纯文本字幕文件)、srt(保存为标准SRT字幕文件,可直接用于视频剪辑)。 - 输出路径:默认保存到
ComfyUI/output/ComfyUI-QwenASR/,可自定义修改,方便后续查找与整理。 - 分块模式:默认采用“标点+停顿+长度”综合分块,更适合字幕生成,保证字幕语句的完整性与连贯性。
- 输出格式:支持
安装步骤:三步完成部署,重启即可使用
该节点包的安装流程简单易懂,核心分为“克隆仓库、安装依赖、重启ComfyUI”三步,前置要求是已安装并正常运行ComfyUI,且具备完整的Python环境。
步骤1:克隆项目仓库到ComfyUI自定义节点目录
打开终端(Windows使用CMD/PowerShell,Mac/Linux使用终端),切换到ComfyUI的custom_nodes目录,然后克隆项目源码:
# 切换到ComfyUI自定义节点目录(请替换为你的ComfyUI实际路径)
cd ComfyUI/custom_nodes
# 克隆项目仓库
git clone https://github.com/1038lab/ComfyUI-QwenASR.git
步骤2:安装项目所需依赖包
进入项目目录,执行命令安装requirements.txt中列出的所有依赖(PS:依赖项较多且有固定版本的依赖项,可能会与其他节点冲突),保证节点能够正常运行:
# 进入ComfyUI-QwenASR项目目录
cd ComfyUI-QwenASR
# 安装依赖包
pip install -r requirements.txt
步骤3:重启ComfyUI,验证节点是否生效
安装完成后,关闭当前正在运行的ComfyUI服务,然后重新启动ComfyUI。
重启成功后,在ComfyUI的搜索框中输入ASR,若能找到ASR (QwenASR)与Subtitle (QwenASR)两个节点,说明安装成功,可开始配置使用。
模型管理:双下载源、自定义路径,适配不同场景
ComfyUI-QwenASR支持多款Qwen3系列模型,同时提供灵活的配置选项,适配不同网络环境与模型存储需求,具体如下:
支持的模型列表
该节点包支持以下三款模型,满足不同精度与功能需求:
Qwen/Qwen3-ASR-1.7B:大参数语音识别模型,识别准确率更高,适合对转录精度要求较高的场景(显存占用相对较高)。Qwen/Qwen3-ASR-0.6B:轻量语音识别模型,显存占用较低,运行速度更快,适合普通场景与中端硬件(默认使用该模型)。Qwen/Qwen3-ForcedAligner-0.6B:强制对齐器模型,专门用于生成精准时间轴字幕,仅在使用Subtitle (QwenASR)节点时加载。
模型默认存储位置
所有下载的模型都会统一缓存到以下目录,后续使用无需重复下载,支持离线运行:
ComfyUI/models/Qwen3-ASR/
配置文件修改(config.json):自定义默认设置
项目仓库根目录下的config.json文件用于配置默认设置,用户可编辑该文件修改默认下载源、默认模型等,适配自身需求。
- 示例配置内容:
{
"defaults": {
"source": "ModelScope",
"repo_id": "Qwen/Qwen3-ASR-0.6B"
}
}
- 关键配置说明:
source:默认下载源,可选HuggingFace或ModelScope,国内用户推荐选择ModelScope,下载速度更快、连接更稳定。repo_id:默认使用的模型,可根据自身硬件配置与精度需求,修改为Qwen/Qwen3-ASR-1.7B或Qwen/Qwen3-ASR-0.6B。
自定义模型路径(extra_model_paths.yaml)
若不想将模型存储在默认目录,可将模型的父目录添加到ComfyUI的extra_model_paths.yaml配置文件中,节点会自动在该配置的路径中搜索Qwen3-ASR系列模型,无需手动指定模型路径。
使用示例:两种经典工作流,拖拽即可运行
ComfyUI-QwenASR提供两种经典工作流,无需复杂配置,拖拽节点即可快速上手,满足不同场景需求。
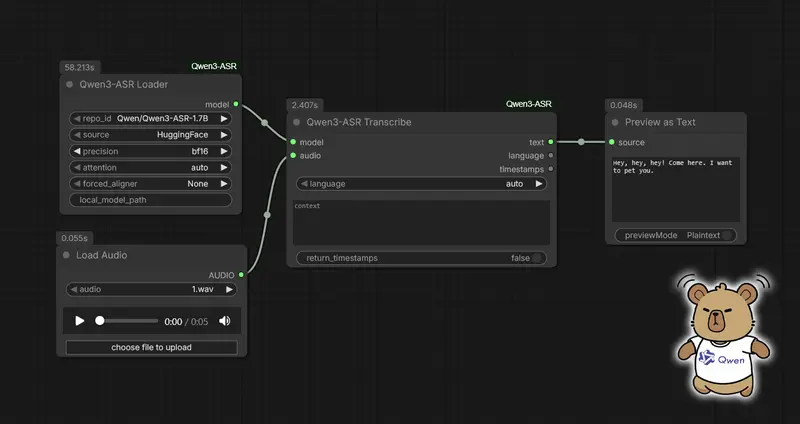
示例1:语音转文本工作流(仅提取文字内容)
该工作流用于快速将音频转换为纯文本,步骤简单,适合整理会议纪要、播客文字稿等场景:
LoadAudio(加载本地音频)→ ASR (QwenASR)(执行语音转文本)→ ShowText(查看转录结果)
- 扩展:若需要保存文本文件,可将
ASR (QwenASR)的输出连接SaveText节点,自定义保存路径与文件名。
示例2:字幕生成工作流(生成带精准时间轴的字幕)
该工作流用于生成带时间轴的字幕,适合视频字幕制作等场景,支持直接保存为SRT文件:
LoadAudio(加载本地音频)→ Subtitle (QwenASR)(生成字幕)→ ShowText(查看结果)/ SaveText(保存字幕文件)
- 关键配置:在
Subtitle (QwenASR)节点中,将输出格式设置为srt,即可生成标准SRT字幕文件,直接用于Pr、剪映等视频剪辑软件。
注意事项:避坑指南,保证运行顺畅
- 长音频处理无需手动分段,节点会在内部自动分块处理,但硬件配置较低时(如显存不足),处理速度可能较慢,建议耐心等待。
- 生成带精准时间轴的字幕,必须保证
Qwen/Qwen3-ForcedAligner-0.6B模型可用(已下载或已配置自定义路径),否则无法生成精准时间轴。 - 若更换电脑、迁移ComfyUI或手动调整模型存储路径,可通过节点的
local_model_path参数手动指定模型路径,保证节点能够正常加载模型。 - 安装依赖时若出现网络超时,可切换国内PyPI镜像源(如清华源、阿里云源)加速安装,避免依赖缺失导致节点运行失败。
同类节点
- ComfyUI-Qwen3-ASR:https://github.com/DarioFT/ComfyUI-Qwen3-ASR
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...