
之前已向大家介绍了《新的4位量化方法SVDQuant》,现在该方法已经推出了适用于ComfyUI的节点以及相应的量化模型。为了能够充分利用这些资源,用户需要安装Nunchaku推理引擎。对于显存小于12GB的设备来说,这个量化模型尤为有用。根据研究团队的报告,以FLUX.1模型为例,SVDQuant技术在12B参数的FLUX.1模型上,可以将原始BF16模型的内存占用减少3.5倍,并且在配备16GB显存的笔记本电脑级RTX4090显卡上,相较于仅量化权重的NF4 W4A16基线,实现了3倍的速度提升。
- 插件地址:https://github.com/mit-han-lab/nunchaku/tree/main/comfyui
- Nunchaku 推理引擎:https://github.com/mit-han-lab/nunchaku
- 模型地址:https://huggingface.co/collections/mit-han-lab/svdquant-67493c2c2e62a1fc6e93f45c
安装步骤
- 安装Nunchaku推理引擎:请按照
README.md中的说明进行安装。 - 配置ComfyUI和SVDQuant:
- 在
comfyui目录下的custom_nodes文件夹中创建一个新的文件夹,并命名为svdquant。 - 将
nunchaku/comfyui文件夹内的所有文件复制到新创建的svdquant文件夹下。 - 将SVDQuant工作流配置从
workflows文件夹放入user/default/workflows文件夹内。
- 在
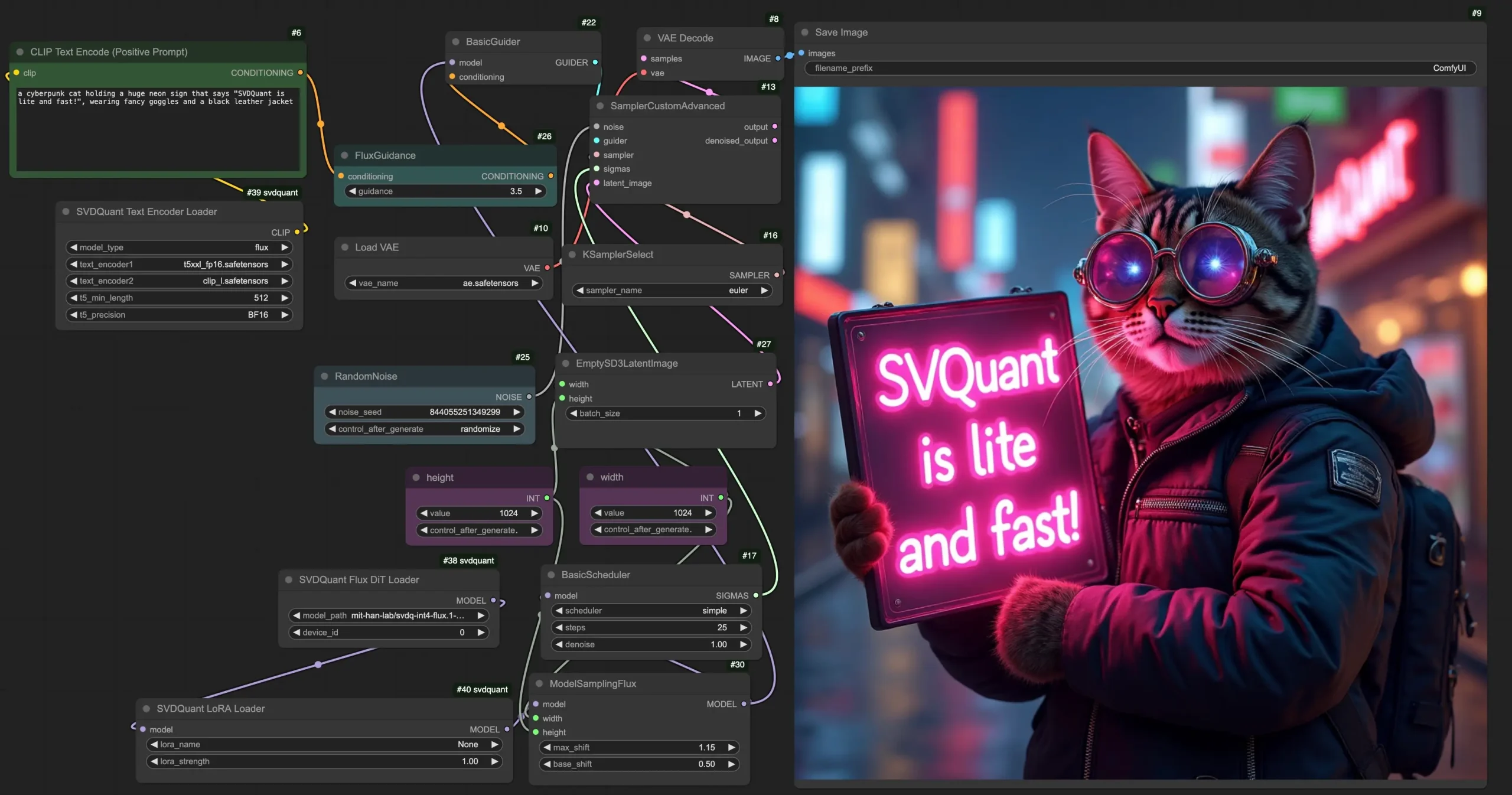
使用SVDQuant节点
SVDQuant Flux DiT Loader
此节点用于加载FLUX扩散模型。配置选项包括:
model_path: 指定模型位置。可以选择mit-han-lab/svdq-int-flux.1-schnell或mit-han-lab/svdq-int-flux.1-dev。模型将自动从Hugging Face仓库下载。device_id: 指示运行模型的GPU ID。
SVDQuant LoRA Loader
此节点用于加载SVDQuant扩散模型的LoRA模块。需要注意的是:
- 将LoRA检查点放置在
models/loras目录中,它们将在lora_name选项中显示。确保您的LoRA检查点符合SVDQuant格式。即将发布一个LoRA转换脚本,同时示例LoRA会自动从Hugging Face仓库下载。 - 注意:目前一次只能加载一个LoRA。
SVDQuant Text Encoder Loader
此节点用于加载文本编码器。针对FLUX模型,使用以下文件:
text_encoder1:t5xxl_fp16.safetensorstext_encoder2:clip_l.safetensors
此外,您可以调整以下设置以优化性能:
t5_min_length: 设置T5文本嵌入的最小序列长度。推荐使用512,以获得更好的图像质量。t5_precision: 选择INT4精度以减少约15GB的GPU内存使用量。若要使用INT4文本编码器,请先安装deepcompressor:
git clone https://github.com/mit-han-lab/deepcompressor
cd deepcompressor
pip install poetry
poetry install
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











