
扩散模型因其在生成高保真图像方面的卓越能力而备受关注。然而,这些模型在内存和计算方面的要求非常高,这限制了它们在消费级设备和需要低延迟的应用中的部署。为了解决这些问题,研究人员提出了多种技术,包括后训练量化和量化感知训练。然而,这些方法在处理扩散模型时效果有限,因为扩散模型需要同时对权重和激活进行低比特量化,以防止性能下降。
现有方法的局限性
仅权重量化:如NormalFloat4(NF4)等方法对语言模型效果良好,但在扩散模型中效果不佳。 异常值问题:现有的量化方法在4比特精度下难以处理权重和激活中的异常值,导致视觉质量和计算效率下降。
SVDQuant 方法
来自麻省理工学院、英伟达、卡耐基梅隆大学、普林斯顿大学、加州大学伯克利分校、上海交通大学和Pika Labs的研究人员提出了一种新的4位量化方法——SVDQuant,它专门针对扩散模型(diffusion models),旨在通过量化权重和激活值为4位来加速模型的推理过程,同时保持图像质量。

- 项目主页:https://hanlab.mit.edu/projects/svdquant
- GitHub:https://github.com/mit-han-lab/deepcompressor
- Nunchaku 推理引擎:https://github.com/mit-han-lab/nunchaku
- 模型:https://huggingface.co/collections/mit-han-lab/svdquant-67493c2c2e62a1fc6e93f45c
- Demo:https://svdquant.mit.edu
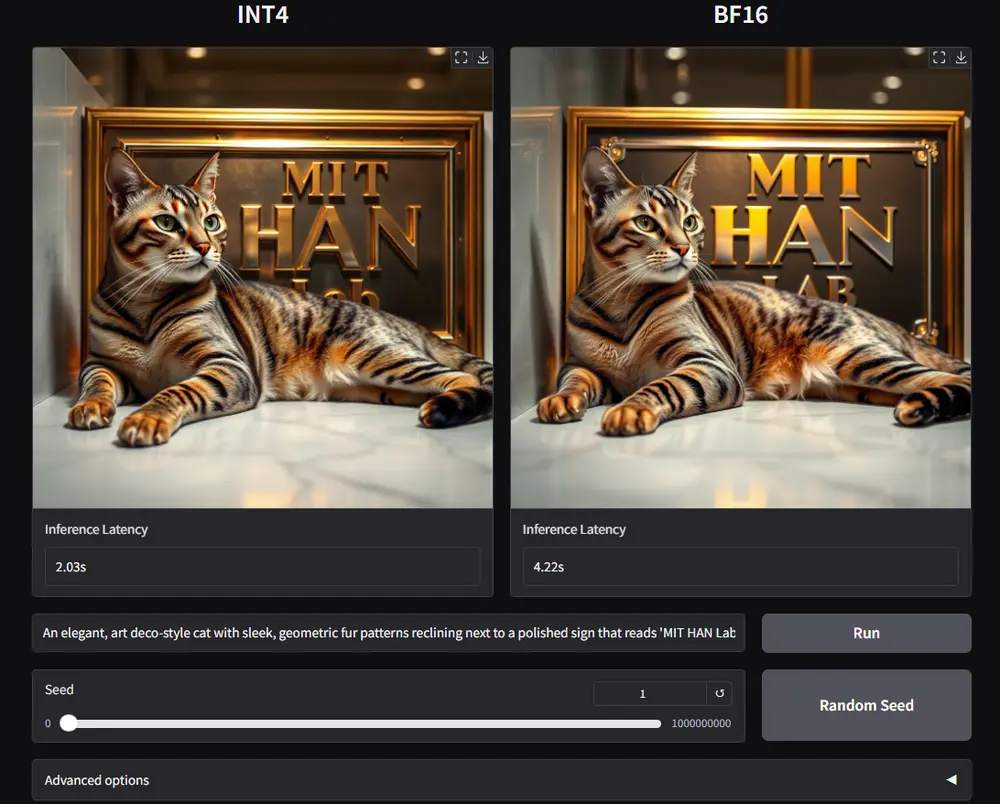
研究团队以FLUX.1模型为例,展示了SVDQuant技术的应用效果。在12B参数的FLUX.1模型上,SVDQuant技术能够将原始BF16模型的内存占用减少3.5倍,并且在16GB的笔记本电脑级RTX4090显卡上,相比于仅量化权重的NF4 W4A16基线,实现了3倍的速度提升。
主要功能
4位量化:将扩散模型的权重和激活值量化到4位,以减少模型大小和提高推理速度。 图像质量保持:在量化的同时,保持生成图像的视觉质量。 内存和速度优化:通过优化内存访问和计算内核,减少模型部署时的内存占用和提高模型运行速度。
主要特点
低秩分支:引入一个16位的低秩分支来吸收权重和激活值中的异常值(outliers),从而简化4位量化过程。 内核融合:通过Nunchaku推理引擎,将低秩分支的计算内核与4位量化和计算内核融合,减少内存访问开销。 与LoRA集成:SVDQuant可以与预训练的低秩适配器(LoRAs)无缝集成,无需重新量化。
工作原理
异常值迁移:首先通过平滑技术将激活值中的异常值迁移到权重,使得激活值更容易量化。 低秩分解:对更新后的权重进行奇异值分解(SVD),将其分解为低秩部分和残差。 量化残差:只对残差进行4位量化,因为残差中的异常值较少,量化难度降低。 内核融合:通过Nunchaku推理引擎,将低秩分支的计算内核与4位量化和计算内核融合,减少数据移动和内核调用次数。
实验结果
内存节省:在 FLUX.1 和 SDXL 等模型上,SVDQuant 实现了3.5倍的内存节省。例如,120亿参数的FLUX.1模型从22.7 GB减少到6.5 GB。 延迟减少:在笔记本设备上,SVDQuant 实现了高达10.1倍的延迟节省。 图像质量:SVDQuant 在效率和视觉保真度方面超越了最先进的量化方法。在多个扩散模型架构中,SVDQuant 的配置在 LPIPS 评分上与16比特基线紧密对齐,同时显著减少了模型大小和延迟。
具体应用场景
边缘设备部署:在内存和计算资源受限的边缘设备上部署大型扩散模型,如智能手机或IoT设备。 实时应用:在需要快速响应的应用中,如实时图像编辑或虚拟现实(VR)应用。 云计算和数据中心:在云计算和数据中心中,通过减少模型大小和提高推理速度,提高服务效率和降低运营成本。
SVDQuant 通过先进的4比特量化方法,有效地处理了扩散模型中的异常值问题,同时保持了图像质量,显著减少了内存和延迟。Nunchaku 推理引擎进一步优化了量化过程,消除了冗余数据移动,为大规模扩散模型的有效部署奠定了基础。这使得在内存有限的设备上实时生成高质量图像成为可能,推动了扩散模型在消费硬件上的实际应用。
总之,SVDQuant 和 Nunchaku 推理引擎为解决扩散模型的内存和延迟挑战提供了有效的解决方案,为大规模扩散模型的实际部署铺平了道路。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











