
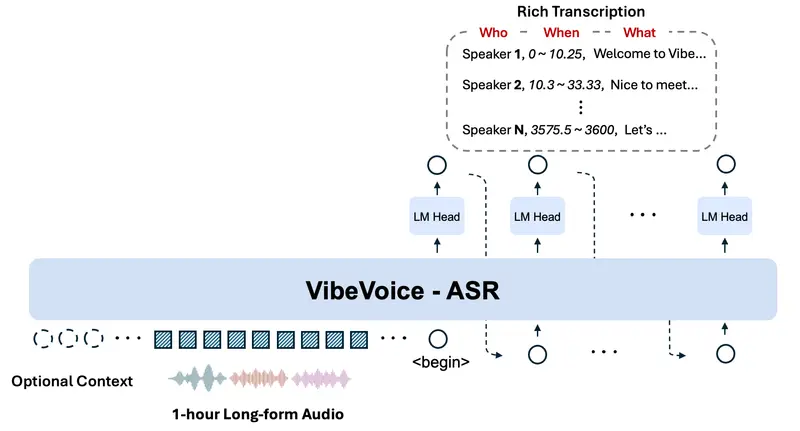
微软正式开源 VibeVoice-ASR——一款面向真实场景的统一语音识别模型。它能单次处理长达60分钟的连续音频,并输出包含说话人身份、精确时间戳与文本内容的结构化转录结果,同时支持用户注入自定义热词以提升领域准确性。
- GitHub:https://github.com/microsoft/VibeVoice/blob/main/docs/vibevoice-asr.md
- 模型:https://huggingface.co/microsoft/VibeVoice-ASR
- Demo:https://aka.ms/vibevoice-asr
这一发布标志着语音识别从“短片段处理”向“长上下文理解”的重要演进。
为什么 VibeVoice-ASR 不同?
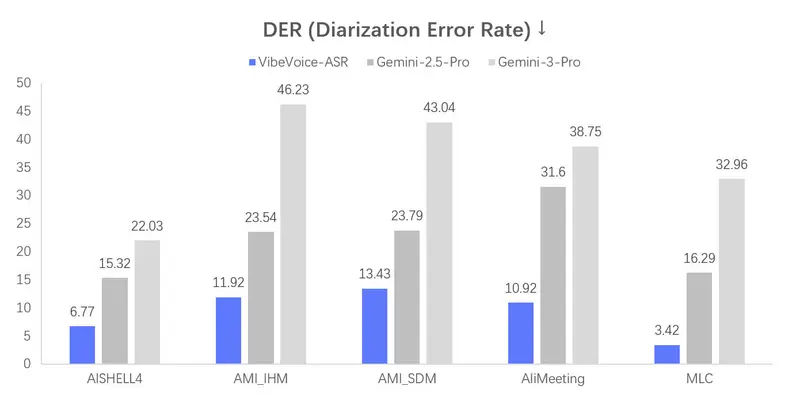
传统 ASR(自动语音识别)系统通常将长音频强制切分为30秒以内的片段,再分别转写。这种方式虽简化了计算,却带来三大问题:
- 说话人混淆:无法跨片段追踪同一说话人
- 上下文断裂:语义连贯性丢失,影响专有名词与代词解析
- 时间戳错位:拼接后难以对齐原始时间轴
VibeVoice-ASR 通过端到端建模,直接处理长达 60 分钟 的音频(受限于 64K token 上下文窗口),从根本上避免上述问题。
核心特性
单次处理 60 分钟音频
- 无需预分割,保留完整对话流
- 在整个会话中维持一致的说话人嵌入(speaker embedding)
- 适用于会议记录、访谈、课程讲座等长时场景
自定义热词(Custom Hotwords)
- 用户可提供人名、术语、产品名等关键词列表
- 模型在解码阶段动态增强这些词汇的识别概率
- 显著提升医疗、法律、金融等专业领域的转写准确率
结构化输出:“谁 + 何时 + 说什么”
模型联合执行三项任务:
- 语音识别(ASR):生成文本
- 说话人日志(Speaker Diarization):标注每段话的说话人(如 Speaker A/B)
- 时间戳对齐:精确到毫秒级的起止时间
输出示例(JSON 格式):
{
"segments": [
{
"speaker": "Speaker_1",
"start": 12.45,
"end": 18.20,
"text": "我们需要在下周三前完成模型评估。"
},
{
"speaker": "Speaker_2",
"start": 18.80,
"end": 24.10,
"text": "明白,我会协调数据团队优先处理。"
}
]
}
典型应用场景
- 企业会议纪要:自动区分发言人,生成可搜索的会议记录
- 学术访谈转录:保留研究者与受访者的完整对话脉络
- 客户服务质检:分析客服与用户的交互质量,无需人工分段
- 播客/视频字幕:一键生成带说话人标识的 SRT 或 VTT 文件
开源与部署
- 完全开源:模型权重、推理代码与文档已发布
- 本地优先:支持 CPU/GPU 推理,数据不离开设备
- 灵活集成:提供 Python API,可嵌入现有工作流
💡 虽然模型支持60分钟输入,但实际性能受硬件限制。建议在 32GB+ 内存设备上处理超长音频。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











