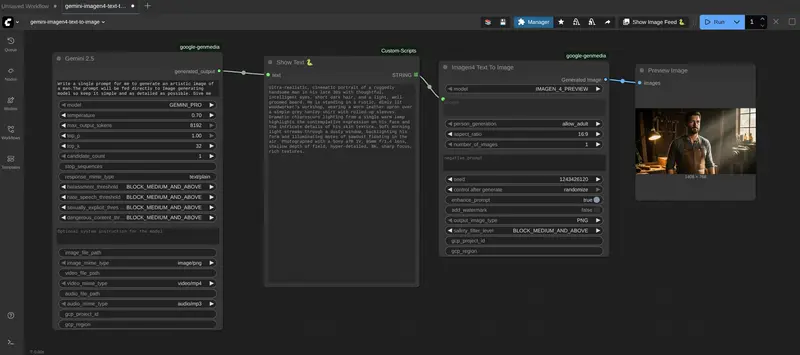
ComfyUI GeminiOllama Extension是一款ComfyUI插件,此插件将 Google 的 Gemini API、OpenAI(ChatGPT)、Anthropic 的 Claude、Ollama、Qwen 以及多种图像处理工具集成到 ComfyUI 中,使用户能够直接在 ComfyUI 工作流中利用这些强大的模型和功能。
功能
1、 多种 AI API 集成
Google Gemini:支持 gemini-2.0-pro、gemini-2.0-flash、gemini-1.5-pro 等模型 OpenAI:支持 gpt-4o、gpt-4-turbo、gpt-3.5-turbo 及 DeepSeek 模型 Anthropic Claude:支持 claude-3.7-sonnet、claude-3.5-sonnet、claude-3-opus 等模型 Alibaba Qwen:支持 qwen-max、qwen-plus、qwen-turbo 模型 Ollama:运行本地模型,支持自定义参数
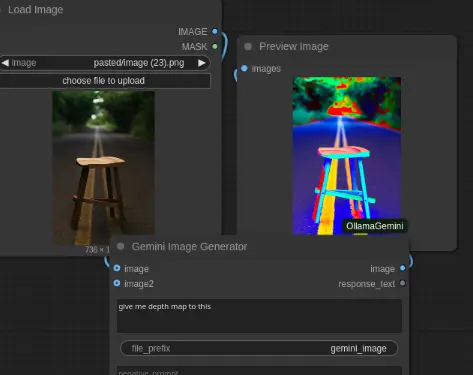
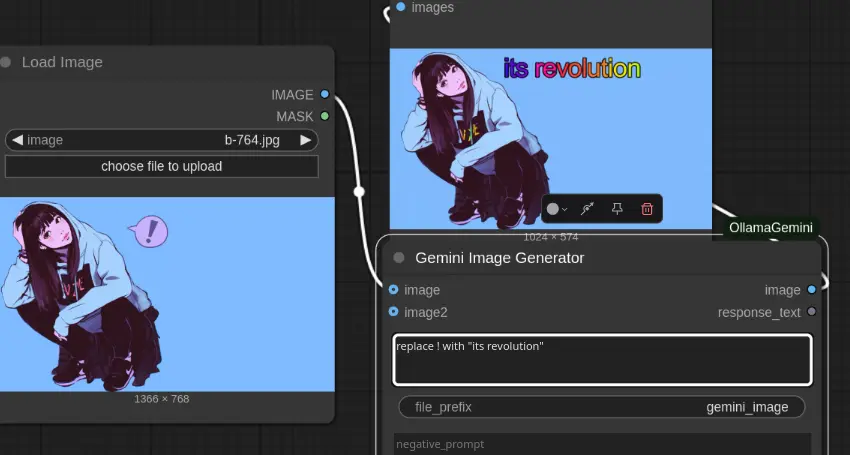
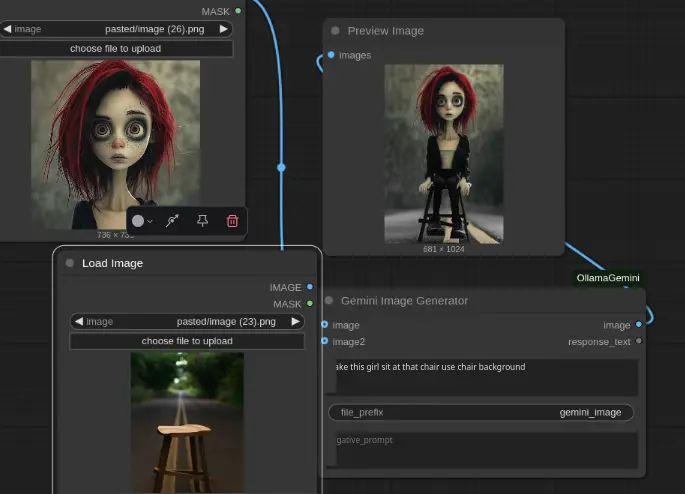
2、 Gemini 图像生成
使用 Google 的 Gemini 2.0 Flash 模型直接生成图像 支持通过提示词和负面提示词进行自定义 自动保存生成图像到 ComfyUI 的输出目录
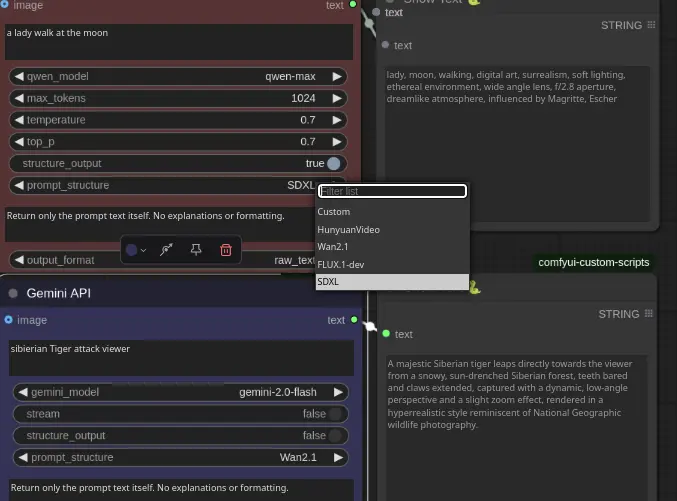
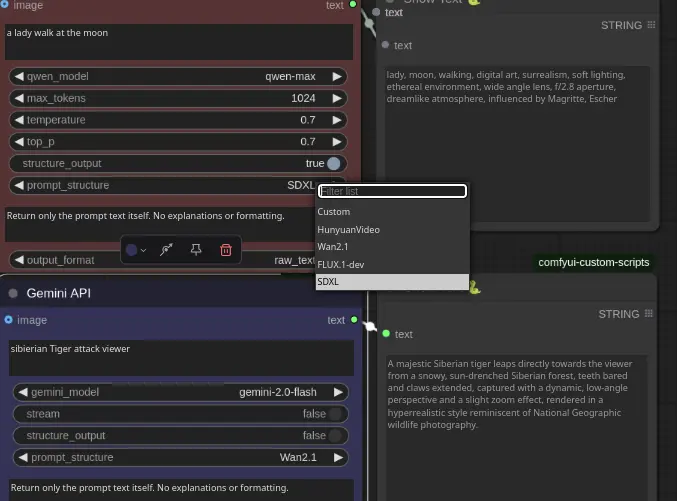
3、 提示词增强
将简单提示词转换为针对特定模型的详细指令 提供多种专用模板(SDXL、Wan2.1、FLUX.1-dev、HunyuanVideo) 仅返回增强后的提示词,不包含额外评论
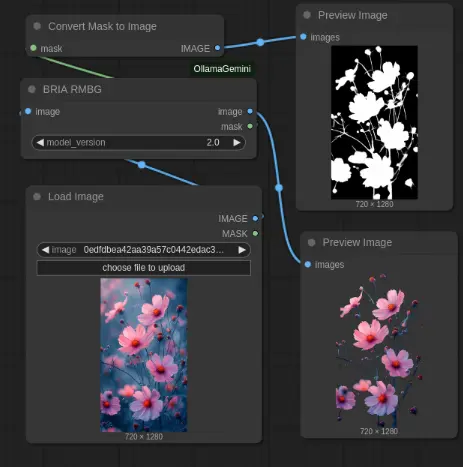
4、 背景移除(BRIA RMBG)
高质量背景移除,保留精细细节 支持复杂边缘、头发、细茎和透明元素的保留 生成透明图像和 Alpha 蒙版
5、 SVG 转换
将光栅图像转换为高质量矢量图形 提供多种矢量化参数以实现精确控制 直接在 ComfyUI 中保存和预览 SVG 文件
6、 FLUX 分辨率
提供精确的图像尺寸调整,支持预定义和自定义选项 多种分辨率预设,适用于各种使用场景 自定义尺寸参数,提供完全控制
7、 ComfyUI 风格器
提供数百种艺术风格,增强创作控制 风格类别包括艺术风格、相机设置、情绪等 支持轻松组合多种风格元素
安装与设置
ComfyUI 管理器(推荐)
如果尚未安装,请先安装 ComfyUI 管理器。 在 ComfyUI 中,转到“管理器”选项卡,搜索“OllamaGemini”。 点击“安装”。
API Key设置
| Provider | Where to Get | Free Tier |
|---|---|---|
| Google Gemini | Google AI Studio | ✅ Yes |
| OpenAI | OpenAI Platform | ❌ No |
| Anthropic Claude | Anthropic Console | ✅ Limited |
| Ollama | Ollama (runs locally) | ✅ Yes |
| Alibaba Qwen | DashScope Console | ✅ Limited |
使用配置文件
在插件目录中创建或编辑 config.json 文件:
{
"GEMINI_API_KEY": "your_gemini_api_key",
"OPENAI_API_KEY": "your_openai_api_key",
"ANTHROPIC_API_KEY": "your_claude_api_key",
"OLLAMA_URL": "http://localhost:11434",
"QWEN_API_KEY": "your_qwen_api_key"
}快速入门指南
使用 AI API 服务
在工作流中添加相应的 API 节点(Gemini API、OpenAI API、Claude API 等)。 在文本字段中输入提示词。 从下拉菜单中选择所需的模型。 根据需要调整参数,如温度和最大令牌数。 若需增强提示词,启用“structure_output”并选择提示词结构模板。 将输出连接到工作流中的其他节点。
使用 Gemini 生成图像
在工作流中添加“Gemini 图像生成器”节点。 输入描述所需图像的提示词。 可选:添加负面提示词以排除不需要的元素。 将输出连接到预览节点以查看生成的图像。
移除背景
在工作流中添加“BRIA RMBG”节点。 将图像源连接到输入端。 将 model_version 设置为 2.0 以获得最佳效果。 连接图像输出以查看透明结果。 连接蒙版输出以查看生成的蒙版。
将图像转换为 SVG
在工作流中添加“将图像转换为 SVG”节点。 将图像源连接到输入端。 配置矢量化参数。 将输出连接到“保存 SVG 文件”节点。 设置文件名前缀并启用预览。
为什么选择此扩展?
全面的 API 集成
通过单一界面访问最强大的 AI 模型:
Google Gemini:gemini-2.0-pro、gemini-2.0-flash、gemini-1.5-pro 等 OpenAI:gpt-4o、gpt-4-turbo、gpt-3.5-turbo 及 DeepSeek 模型 Anthropic Claude:claude-3.7-sonnet、claude-3.5-sonnet、claude-3-opus 等 Alibaba Qwen:qwen-max、qwen-plus、qwen-turbo、qwen-max-longcontext Ollama:运行任何本地模型,支持自定义参数
高级提示词增强
通过专用模板将简单提示词转换为详细的、特定于模型的指令:
SDXL:针对 Stable Diffusion XL 优化,包含详细艺术参数 Wan2.1:包含主体、场景和风格元素的专用格式 FLUX.1-dev:增强格式,包含深度效果和相机细节 HunyuanVideo:专为视频生成设计,描述连贯 自定义:为特定需求创建自己的提示词结构
高质量工具
BRIA RMBG:业界领先的背景移除工具,保留精细细节 SVG 转换:使用 vtracer 进行高质量矢量化 FLUX 分辨率:精确的图像尺寸调整,支持预定义和自定义选项 ComfyUI 风格器:提供数百种艺术风格,增强创作控制
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











