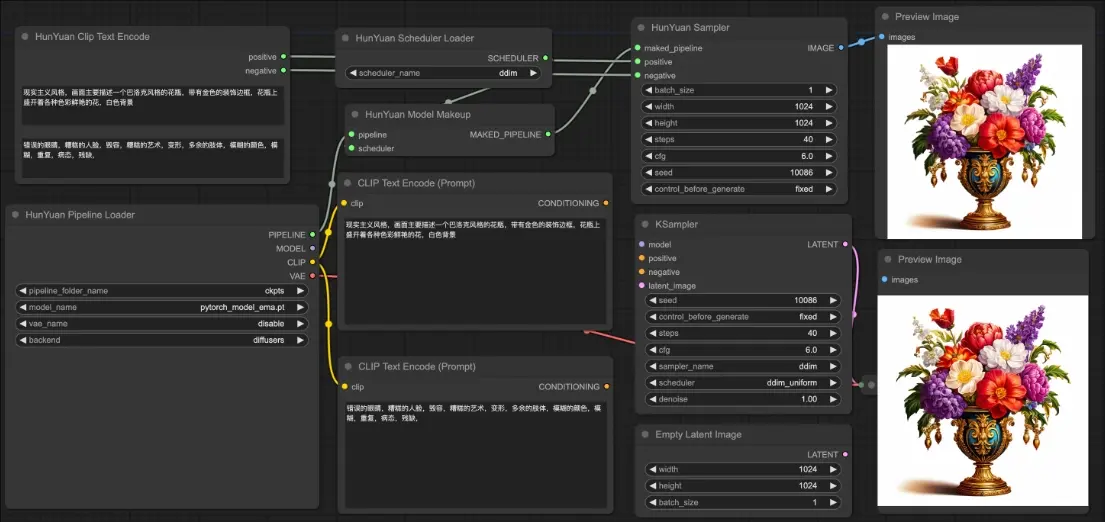
ComfyUI-Youtu-VL 是一个专为 腾讯 Youtu-VL(40 亿参数轻量级视觉语言模型)设计的自定义节点插件,让 ComfyUI 用户无需离开工作流即可调用强大的视觉理解能力。该模型支持视觉定位、分割、深度估计、姿态估计等以视觉为中心的任务,并特别优化了与生成式 AI 工作流的协同——如为绘画模型(Z-Image、Qwen Image等)自动生成高质量提示词或 LoRA 训练标签。
核心优势:双引擎 + 零配置
- 双推理引擎,按需切换
- 标准版(transformers):高精度,适合研究或对输出质量要求严苛的场景,支持 Flash Attention 2 加速和 BitsAndBytes 4/8-bit 量化。
- GGUF 版(llama.cpp):低显存、高速度,可在 6GB 显存消费级 GPU 上流畅运行,支持 CPU/GPU 混合推理与 GPU 卸载层数调节。
- 零配置体验
模型在首次使用时自动从 HuggingFace 下载,无需手动管理权重文件。
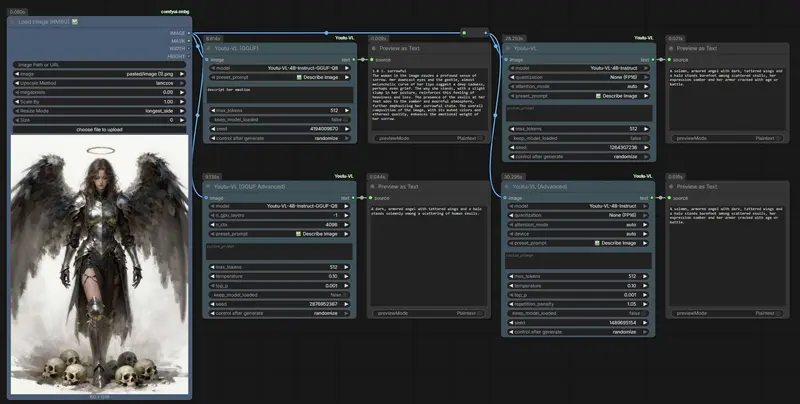
六大智能预设,开箱即用
节点内置 config.json 预设,一键触发常见任务:
| 预设 | 功能 | 典型用途 |
|---|---|---|
| 📝 详细描述 | 生成包含光线、构图、主体细节的完整段落 | Z-Image、Qwen Image 提示词增强 |
| 🔍 分析元素 | 列出图像中的关键物体与空间布局 | 场景理解、内容审核 |
| 🏷️ 生成标签 | 输出 Danbooru 风格逗号分隔标签 | LoRA/Textual Inversion 自动打标 |
| 📄 OCR 文本 | 提取图像中所有可见文字 | 截图转文本、文档数字化 |
| 🎨 艺术风格 | 识别媒介(油画/水彩)、艺术家风格、笔触技巧 | 艺术分析、风格迁移参考 |
| ❓ 视觉问答 | 回答自定义问题(如“衣服是什么颜色?”) | 交互式图像探索 |
所有预设均可通过下拉菜单直接选择,无需编写提示词。
安装指南
推荐方式:通过 ComfyUI Manager 安装
- 打开 ComfyUI Manager
- 搜索 “ComfyUI Youtu-VL”(发布者:1038lab)
- 点击 安装 → 自动处理依赖与模型下载
手动安装
cd ComfyUI/custom_nodes/
git clone https://github.com/1038lab/ComfyUI-Youtu-VL.git
cd ComfyUI-Youtu-VL
pip install -r requirements.txt
启用 GGUF 支持(可选但推荐)
若需使用 GGUF 版本以获得更低显存占用和更快速度,请安装对应 CUDA 版本的 llama-cpp-python:
# 示例:CUDA 12.1
pip install llama-cpp-python --extra-index-url https://abetlen.github.io/llama-cpp-python/whl/cu121
# 其他版本替换 cu121 为 cu118(CUDA 11.8)或 metal(macOS)
节点选择建议
| 场景 | 推荐节点 | 理由 |
|---|---|---|
| LoRA 自动打标、SD 提示词生成 | 标准版 | 标签准确性更高 |
| 实时交互、批量处理 | GGUF 版(Q4_K_M) | 速度提升 2–3 倍,显存占用 <5GB |
| 显存 ≤6GB | GGUF 版 + Q4 量化 | 避免 OOM 崩溃 |
| 研究/微调实验 | 标准版 + FlashAttention-2 | 最大化输出质量 |
⚠️ 注意:分割、深度估计、姿态估计等高级功能目前位于
Beta/文件夹,需手动启用实验性节点。
故障排除
- GGUF 节点不显示? → 确认
llama-cpp-python已正确安装(检查 CUDA 版本匹配)。 - 显存不足? → 切换至 GGUF 节点,选择 Q4 或 Q5 量化模型。
- 首次加载慢? → 模型正在后台下载(约 2–4 GB),完成后将缓存至本地。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











