TTS-Audio-Suite 是一款为 ComfyUI 深度定制的多引擎文本转语音(TTS)与语音转换(VC)扩展工具,脱胎于原始 ChatterBox Voice 项目。它不是简单的“语音插件”,而是一个模块化、可扩展、支持生产级工作流的音频生成系统。
无论你是制作有声内容、动画配音、多语言播客,还是需要从无声视频提取语音时间轴,TTS-Audio-Suite 都能为你提供灵活、高效、高度可控的解决方案。
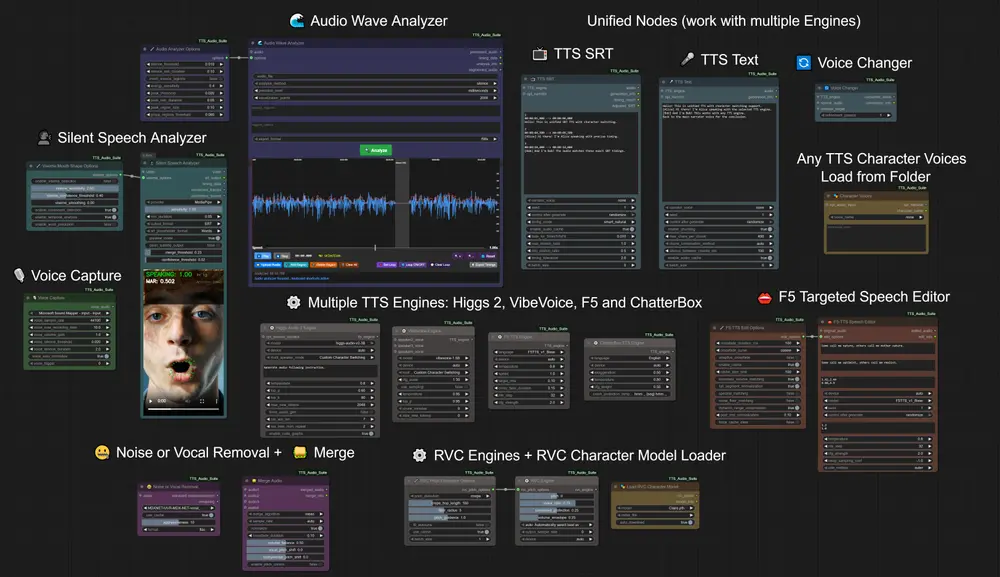
核心能力概览
- 多引擎支持:集成 ChatterBox TTS、F5-TTS、Higgs Audio 2、Microsoft VibeVoice、RVC 等主流语音引擎。
- 统一架构:所有引擎共享同一套节点接口,切换无需重构工作流。
- 角色与语言切换:支持 [角色名]、[语言:角色] 语法,实现多角色对话与多语种混合输出。
- 长文本处理:智能分块 + 缓存机制,支持无限长度文本生成。
- 音频后期处理:降噪、回声消除、波形分析、SRT 时间同步、静音检测等一应俱全。
- 实验性功能:从无声视频中提取嘴部运动,生成基础 SRT 时间轴(MediaPipe 驱动)。
主要引擎与功能详解
1. ChatterBox 官方 23 语言引擎(v4.8+)
- 原生支持 23 种语言:包括中、英、日、韩、德、法、俄、阿拉伯语等。
- 单一模型,参数切换:无需加载多个模型,通过语言参数即时切换。
- 零样本语音克隆:仅需几秒参考音频,即可在任意语言中克隆声音。
- MIT 开源协议:可商用,无版权顾虑。
- 完整兼容现有功能:角色切换、暂停标签、SRT 同步、语音转换均无缝支持。
✅ 推荐用于:多语言内容制作、全球化项目、高质量语音克隆。
2. F5-TTS
- 参考音频 + 文本驱动:上传语音样本,生成风格一致的语音。
- 支持语言:英语、德语、西班牙语、法语、日语、印地语等。
- 集成音频波形分析器:可视化编辑语音时间轴,精准控制节奏。
✅ 推荐用于:角色语音定制、播客旁白、动画配音。
3. Higgs Audio 2(v4.5+)
- 高保真语音克隆:30 秒以上参考音频即可克隆任意人声。
- 多角色对话原生支持:使用 [角色名] 标签自动切换声音。
- 实时生成:低延迟输出,适合交互式内容。
✅ 推荐用于:有声书、角色对话剧、AI 主播。
4. Microsoft VibeVoice(v4.6+)
- 单次生成最长 90 分钟:突破传统 TTS 长度限制。
- 双模式多角色支持:
- 自定义角色切换(推荐):使用 [Alice]、[Bob] 标签 + 语音文件。
- 原生多角色模式:自动识别“Speaker 1:”格式,最多支持 4 人。
- 官方模型支持:1.5B / 7B 参数版本可选,质量对标商业级产品。
✅ 推荐用于:长篇旁白、教学视频、播客系列、企业级语音内容。
5. RVC 实时语音转换(v4.1+)
- 加载 .pth 模型:支持社区训练的角色语音模型。
- 迭代优化:1–30 次转换,逐步逼近目标音色。
- 智能缓存:切换优化次数无需重算,实验效率高。
- 自动下载索引文件:提升音色相似度。
✅ 推荐用于:变声处理、角色配音、语音风格迁移。
高级功能:让语音更智能、更可控
角色与语言无缝切换
- 使用
[Alice] 你好!或[fr:Alice] Bonjour!语法,自动切换语音与语言模型。 - 支持别名映射(如用 [Alice] 代替 [female_01]),提升可读性。
- 与 SRT 字幕时间轴完全兼容,角色语音精确对齐画面。
暂停标签系统
在任意位置插入自然停顿:
欢迎收听。[pause:1.5s] 今天的内容非常重要。
[Alice] 我同意![wait:800ms] 我们开始吧。
- 支持秒(s)与毫秒(ms)单位。
- 别名支持:pause / wait / stop 功能相同。
- 更改暂停时间不触发全文重生成,提升迭代效率。
SRT 时间同步(v4.x+)
- 输入 SRT 字幕文件,输出精确对齐的语音。
- 支持
smart_natural时间模式:自动避让重叠,确保语音流畅。 - 输出
Adjusted_SRT:包含实际生成时间,便于后期剪辑。 - 段级缓存:仅重生成修改段落,大幅提升长内容处理效率。
无声视频语音分析器(实验性,v4.4+)
从无声音频的视频中提取嘴部运动,生成基础 SRT 时间轴:
- MediaPipe 驱动,帧级嘴型检测。
- 实验性视素分类(元音/辅音近似识别)。
- 基于 CMU 词典预测单词,生成语音占位符。
- 输出可编辑的 SRT 文件,作为人工配音或 TTS 生成的时间模板。
⚠️ 注意:此功能为实验性质,生成内容需人工校对,不建议直接用于生产。
技术架构亮点
- 模块化设计:新增引擎只需实现适配器,无需重构核心。
- 并行处理支持:通过
batch_size参数配置,但实测batch_size=0(顺序处理)性能最优。 - 智能缓存系统:基于参数变化自动失效,避免冗余计算。
- 模型自动管理:首次使用自动下载,本地优先,支持离线运行。
- 统一节点接口:所有引擎共享 TTS Text / TTS SRT / Voice Converter 节点,降低学习成本。
多语言支持总览
| 引擎 | 支持语言 |
|---|---|
| ChatterBox 官方 23-Lang | 中、英、日、韩、德、法、俄、阿、西、葡、意、荷、希伯来、印地、马来、挪威、波兰、瑞典、斯瓦希里、土耳其等 23 种 |
| ChatterBox 社区模型 | 英、德(3种变体)、法、意、俄、日、韩、挪、亚美尼亚、格鲁吉亚 |
| F5-TTS | 英、德、西、法、日、泰、葡、印地 |
| Higgs Audio 2 | 英(主测),可能支持中、韩、德、西 |
| VibeVoice | 依赖模型,官方支持多语种 |
使用建议
- 新手入门:从 ChatterBox 官方 23 语言引擎开始,功能全面、文档完善。
- 追求音质:Higgs Audio 2 或 VibeVoice 7B 模型。
- 长内容生成:优先选择 VibeVoice,支持 90 分钟连续输出。
- 角色对话:使用 [角色名] 标签 + 语音文件夹管理,结构清晰。
- 视频配音:结合 SRT 节点 + 暂停标签,实现精准对口型。
项目最新动态(截至 v4.8.6)
- 正式集成 ChatterBox 官方 23 语言引擎,取代旧版社区模型成为主力。
- 优化 SRT 时间处理逻辑,提升长内容生成稳定性。
- 增强 缓存失效机制,确保参数修改后输出实时更新。
- 修复多语言混合场景下的 采样率不一致问题。
- 提升 内存管理效率,减少模型切换时的显存溢出风险。
近期更新
TTS Audio Suite 近期一系列重要更新。从 v4.3.0 到 v4.9.0,本次迭代聚焦于三大核心方向:
- ✅ 更自然的语音节奏控制
- ✅ 真正的多语言无缝切换
- ✅ 可精细调控的情感表达
这些更新不仅提升了语音合成的质量与灵活性,也进一步强化了其在对话系统、播客制作、影视配音等复杂场景中的实用性。
以下是本次版本演进的核心亮点汇总。
⏸️ 智能暂停标签系统:让语音“呼吸”更自然
发布时间:v4.6.x
适用节点:ChatterBox、F5-TTS、SRT 等所有 TTS 节点
长久以来,语音合成中的停顿往往依赖固定延迟或手动切片。现在,TTS Audio Suite 引入了全新的 智能暂停标签系统,让你在文本中直接定义语义级停顿。
支持语法(别名通用):
[pause:1.5] # 秒
[wait:2s] # 明确单位
[stop:500ms] # 毫秒
支持别名:pause, wait, stop(功能完全一致)
核心特性:
| 特性 | 说明 |
|---|---|
| 自然切分 | 在语义间隙插入停顿,避免打断词语或句子 |
| 字符继承 | 暂停期间保留当前说话人身份与音色 |
| 智能缓存 | 修改某一处暂停时间,仅重新生成受影响段落 |
| 零配置启用 | 无需额外参数,直接在文本中添加即可 |
📌 示例:
欢迎来到我们的节目! [pause:1s] 今天我们将讨论激动人心的话题。
[Alice] 我真的很兴奋! [wait:500ms] 这会很棒。
[stop:2] 让我们开始主要内容。
📌 提示:结合 SRT 时间轴使用时,系统自动对齐音频时机,支持重叠与非重叠模式。
🌍 多语言支持双轨并行:社区模型 + 官方统一模型
路线一:社区微调模型(v4.6.29 起)
ChatterBox 正式支持 11 种语言,由全球开发者贡献并持续优化:
| 语言 | 特点 |
|---|---|
| 🇩🇪 德语 | 提供标准、高质量混合、富有表现力三种变体 |
| 🇮🇹 意大利语 | 双语模型,支持 [it] 前缀切换 |
| 🇫🇷 法语 | 基于 1,400 小时 Emilia 数据集,支持零样本克隆 |
| 🇷🇺 俄语 / 🇦🇲 亚美尼亚语 / 🇬🇪 格鲁吉亚语 | 完整独立训练模型 |
| 🇯🇵 日语 / 🇰🇷 韩语 | 共享英语组件实现基础支持 |
| 🇳🇴 挪威语 | 社区专用模型 |
✅ 使用方式:
- 下拉菜单选择语言
- 首次使用自动下载模型(约 1GB)
- 后续调用本地缓存,支持离线运行
- 支持 Safetensors 格式,安全高效
路线二:官方多语言模型(v4.8.0 新增)
ResembleAI 推出首个生产级开源多语言 TTS 模型 —— ChatterBox 多语言 TTS(23 语言版),标志着原始 ChatterBox 的正式演进。
主要优势对比:
| 特性 | 社区模型 | 官方 23 语言模型 |
|---|---|---|
| 语言数量 | 11 种 | 23 种原生支持 |
| 模型架构 | 多个独立模型 | 单一统一模型 |
| 切换方式 | 加载不同模型 | 参数级语言切换 |
| 语音克隆 | 单语言内克隆 | 跨语言零样本克隆 |
| 维护方 | 社区驱动 | ResembleAI 官方维护 |
| 商业许可 | MIT 开源 | ✅ 支持商业用途 |
支持语言(23种):
阿拉伯语、丹麦语、德语、希腊语、英语、西班牙语、芬兰语、法语、希伯来语、印地语、意大利语、日语、韩语、马来语、荷兰语、挪威语、波兰语、葡萄牙语、俄语、瑞典语、斯瓦希里语、土耳其语、中文
完整功能集成:
- ✅ 字符标签
[Character]与语音引用绑定 - ✅ 语言切换
[language:char]实现跨语种角色对话 - ✅ 暂停标签无缝继承上下文
- ✅ SRT 高级字幕时机处理
- ✅ 内置 VC(Voice Conversion)引擎
- ✅ 情感控制(通过夸张参数调节表现力)
- ✅ 缓存失效机制,响应式更新
📌 多语言示例:
[En:Alice] 大家好! [De:Hans] Guten Tag! [Es:Maria] ¡Hola! [pause:2s]
[En:Alice] 那是非常惊人的多语言切换!
所有角色在同一模型下完成切换,语音自然连贯,无加载延迟。
⚙️ 通用流式架构重构(v4.3.0)
为应对日益复杂的 TTS 引擎生态,项目已完成底层架构大修,引入 通用流式处理系统。
核心改进:
| 改进点 | 说明 |
|---|---|
| 统一流程 | 抽象出通用处理管道,消除各引擎间的重复逻辑 |
| 并行能力 | 支持 batch_size > 1 的工作者并行处理(适用于 CPU 密集型前处理) |
| 线程安全 | 采用无状态包装器设计,防止状态污染 |
| 易扩展性 | 新增 TTS 引擎只需实现适配器接口即可接入 |
📌 性能建议:
- 推荐使用
batch_size=0(顺序处理),以获得最佳 GPU 推理效率 - 并行模式适用于长文本预处理阶段,但受限于 GPU 推理串行特性,通常不提速
该架构为未来集成更多 TTS 引擎(如 VITS、YourTTS 等)打下坚实基础。
🌈 IndexTTS-2:情感可控的下一代语音合成(v4.9.0)
最令人期待的功能来了 —— IndexTTS-2 正式发布,带来前所未有的 情感控制精度 与 上下文感知能力。
核心能力概览:
| 功能 | 描述 |
|---|---|
| 统一情感输入 | 所有情感方法汇聚于 emotion_control 字段 |
| 情感优先级系统 | 字符级 > 全局设定,智能覆盖 |
| 动态情感分析 | 结合 QwenEmotion 模型,分析 {seg} 上下文片段的情感倾向 |
| 音频情感引用 | 任意音频文件作为情感参考,实现“像这个人一样说话” |
| Character Voice 集成 | 自动提取 opt_narrator 输出作为情感源 |
| 8维情感向量 | 手动调节 Happy、Angry、Sad、Surprised、Afraid、Disgusted、Calm、Melancholic |
| Alpha 强度控制 | 0.0(中性)到 2.0(戏剧化),自由调节表达强度 |
使用语法示例:
[Alice:happy_sarah] 我很兴奋能来到这里!
[Bob:angry_narrator] 那完全是不可接受的行为。
或配合动态模板:
{seg} 的语气应该是担忧的父母:"孩子,你真的考虑清楚了吗?"
系统将自动调用 QwenEmotion 分析上下文,并生成匹配情感的语音。
适用场景:
- 多角色对话中个体情绪差异化表达
- 叙事类内容根据情节自动调整语气
- 影视/游戏配音中精确控制表演张力
- 心理咨询、教育等需要情感共鸣的应用
缓存优化:
引入稳定音频内容哈希机制,确保相同输入+参数组合始终命中缓存,提升多轮生成一致性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











