VibeVoice-ComfyUI 是一款文本转语音(TTS)插件,将微软最新的 VibeVoice 语音合成模型深度集成至 ComfyUI 工作流中。
它不仅支持自然流畅的单人语音生成,更实现了 多说话者对话合成、语音克隆、长文本分块处理 等关键功能,并原生支持 Apple Silicon GPU 加速与低显存量化模型,让高质量语音生成真正融入视觉创作流程。
无论你是制作播客、动画配音、AI角色对话,还是构建自动化叙事系统,现在都可以在一个统一的工作流中完成“文 → 图 → 声”的全链路生成。
核心能力:不只是“朗读文字”
单人语音合成 + 可选语音克隆
输入一段文本,即可生成高度拟人化的语音输出。
支持从音频样本中提取声纹特征,实现个性化语音克隆(需30秒以上清晰语音)。
适用于:
- 角色旁白
- 教学录音
- AI主播生成
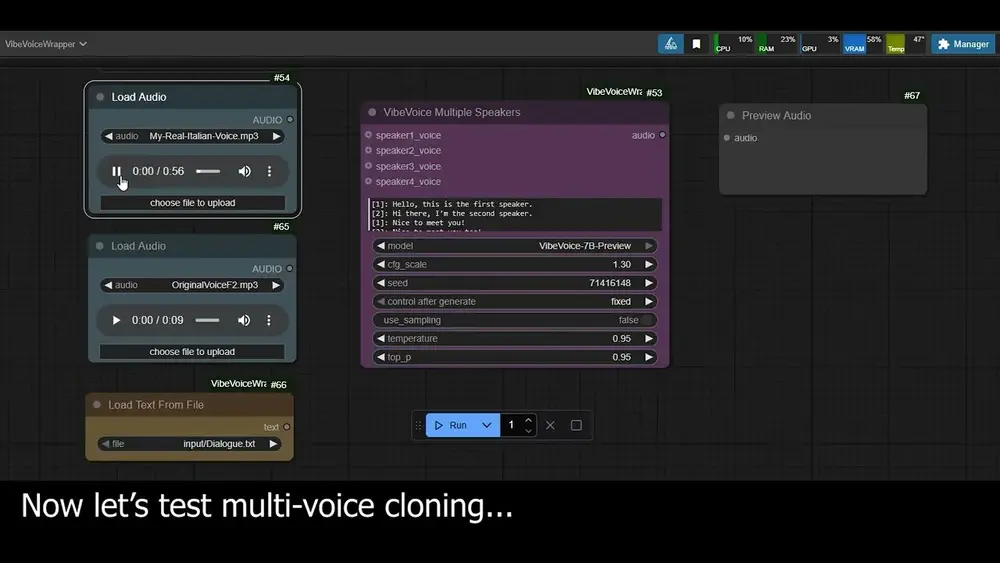
多说话者对话合成(最多4人)
这是本插件最具实用价值的功能之一。
通过简单的标签语法 [1]:、[2]:,即可定义不同角色发言:
[1]: 你看到最新的AI进展了吗?
[2]: 是的,非常令人印象深刻!
[1]: 我认为语音合成已经取得了很大进步。
每个角色可独立绑定语音样本,确保声音特征一致且易于区分。非常适合:
- 动画对白
- 虚拟会议模拟
- 多角色故事叙述
推荐使用
VibeVoice-Large模型以获得最佳多说话者表现
长文本自动分块 + 自定义暂停控制
传统TTS模型常受限于上下文长度,难以处理长脚本。VibeVoice-ComfyUI 提供两项关键优化:
✅ 自动文本分块:可配置每段最大字数(默认250词),无缝拼接输出
✅ 自定义静音标签:支持 [pause](1秒)和 [pause:ms](如 [pause:2000] 表示2秒)
⚠️ 注意:暂停会打断上下文连续性,建议在句尾或段落间使用
节点化工作流:与ComfyUI生态无缝协同
所有功能均以标准节点形式提供,支持:
- 文本文件加载(.txt)
- 多个 TTS 节点串联
- 音频输出连接至保存、播放或其他处理模块
三种模型选择:速度、质量、资源自由平衡
| 模型 | 显存需求 | 特点 | 适用场景 |
|---|---|---|---|
| VibeVoice-1.5B | ~8GB | 快速推理,低资源占用 | 快速原型、单人任务 |
| VibeVoice-Large | ~17GB | 最高质量,最佳多说话者表现 | 生产级输出 |
| VibeVoice-Large-Quant-4Bit | ~7GB | 4位量化,质量损失小 | 低显存设备部署 |
所有模型首次使用时自动下载并缓存至 ComfyUI/models/vibevoice/,后续运行无需重复下载。
性能与兼容性:跨平台高效运行
✅ 支持多种后端加速
- CUDA(NVIDIA GPU)
- MPS(Apple M1/M2/M3 芯片原生支持)
- CPU(无GPU也可运行)
✅ 内存管理精细可控
- 生成后自动清理显存(可关闭)
- 提供专用 “释放内存”节点,用于复杂工作流中的手动资源回收
✅ 兼容主流环境
- Python 3.8+ / PyTorch 2.0+
- Transformers ≥ v4.51.3
- Windows、Linux、macOS 全平台支持
安装与使用指南
安装步骤(推荐方式)
cd ComfyUI/custom_nodes
git clone https://github.com/Enemyx-net/VibeVoice-ComfyUI
重启 ComfyUI,首次使用时自动安装依赖包。
主要节点说明
| 节点名称 | 功能 |
|---|---|
VibeVoice文本文件加载 | 从 .txt 文件读取文本内容 |
VibeVoice单人语音 | 单角色语音合成,支持语音克隆 |
VibeVoice多说话者 | 支持最多4个角色的对话合成 |
VibeVoice释放内存 | 手动卸载模型以释放资源 |
参数调优建议
- 扩散步数(diffusion_steps):默认20,提升可改善音质但增加耗时
- 引导尺度 cfg_scale:1.0–2.0,推荐1.3,控制语音表现力
- 种子 seed:固定种子可复现相同语音结果,便于调试
⚠️ 当前限制:
- 多说话者最多支持4人
- 中英文效果最佳,其他语言可能不稳定
- 不支持背景音乐叠加或音效控制
更新历史
版本 1.6.0
重大变更:移除了从 HuggingFace 自动下载模型的功能
- 模型现在必须手动下载并放置在
ComfyUI/models/vibevoice/目录下 - 动态模型下拉菜单,每次浏览器刷新时都会扫描可用模型
- 支持自定义文件夹名称和 HuggingFace 缓存结构
- 从配置文件自动检测量化模型
- 用户对模型管理有更好的控制权
- 消除了私有 HuggingFace 仓库的认证问题
改进的日志系统:
- 优化日志记录以减少控制台杂乱信息
- 更清晰的输出,提供更好的用户体验
版本 1.5.0
- 新增语音速度控制功能,用于调整语速
- 在单说话人和多说话人节点中均新增
voice_speed_factor参数 - 对参考音频应用时间拉伸以影响输出语速
- 范围:0.8 至 1.2,步长为 0.01
- 推荐范围:0.95 至 1.05,以获得自然效果
- 使用 20 秒以上的参考音频可获得最佳效果
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











