
微软近期开源了一款全新文本到语音(TTS)框架——VibeVoice-1.5B,其核心突破在于打破传统TTS系统的局限:能同时生成包含4个不同说话者、最长60分钟的连贯对话音频,且在长序列处理效率、说话者一致性与对话自然度上均有显著提升,为播客、多角色对话等长篇语音生成场景提供了新方案。
- 项目主页:https://microsoft.github.io/VibeVoice
- GitHub:https://github.com/microsoft/VibeVoice
- 模型:https://huggingface.co/microsoft/VibeVoice-1.5B
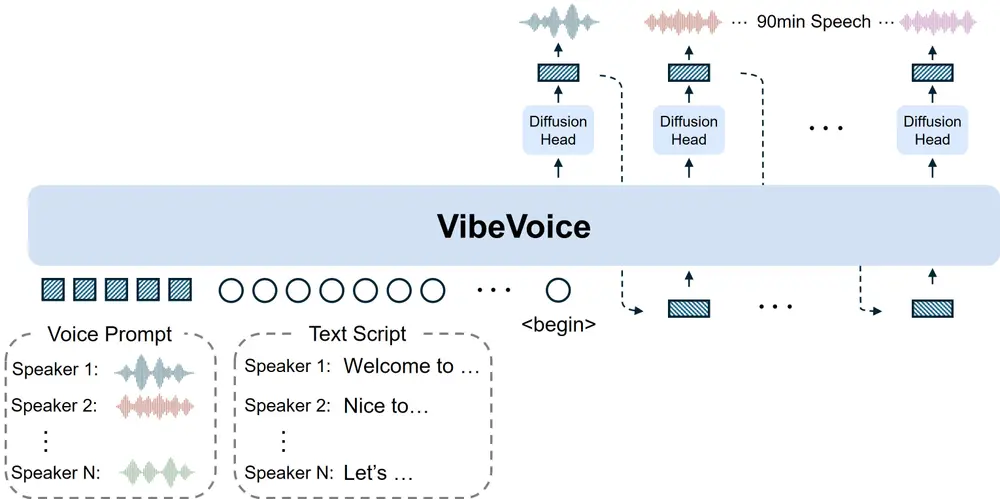
VibeVoice-1.5B核心优势:解决传统TTS三大痛点
传统TTS系统在处理长篇多说话者对话时,常面临“可扩展性差(难支持多说话者)”“说话者特征不稳定”“对话轮流不自然”等问题,而VibeVoice-1.5B通过技术创新,针对性解决了这些痛点:
- 支持多说话者长篇生成
突破多数TTS模型仅支持1-2个说话者的限制,可同时生成4个不同说话者的语音;且最长能合成90分钟的音频(实际推荐使用60分钟,兼顾效果与效率),满足播客、有声剧、多角色对话脚本等长篇场景需求。 - 高效处理长序列,兼顾保真度
采用“连续语音分词器”(包含声学与语义两种分词器),以7.5Hz的超低帧率运行——这一设计大幅降低了长序列处理的计算量,同时通过优化的编码解码结构,有效保留音频保真度,避免因效率提升导致音质下降。 - 对话自然度与上下文理解强
基于“下一标记扩散框架”构建:借助大型语言模型(LLM)理解文本上下文与对话流程(比如判断说话者轮流逻辑),再通过扩散头生成高保真声学细节,让多说话者对话的“轮流衔接”更自然,减少机械感。
VibeVoice-1.5B技术拆解:从模型架构到训练流程
VibeVoice-1.5B的性能依赖于“LLM+双分词器+扩散头”的协同设计,其训练细节与技术模块可清晰拆解为以下部分:
(1)核心技术模块:四大组件各司其职
| 技术模块 | 具体配置与功能 |
|---|---|
| 基础LLM | 采用Qwen2.5-1.5B模型,负责理解文本上下文、对话逻辑与说话者角色分配,是实现多说话者连贯对话的核心“大脑”。 |
| 声学分词器 | 基于LatentLM提出的σ-VAE变体,采用镜像对称编码器-解码器结构(各含7个修改版Transformer块);可将24kHz输入音频实现3200倍下采样,大幅压缩数据量,同时保留声学特征;编码器/解码器各约3.4亿参数。 |
| 语义分词器 | 架构与声学分词器镜像(不含变分自编码器组件),通过自动语音识别(ASR)代理任务训练,负责从文本中提取语义信息,确保语音生成与文本含义对齐。 |
| 扩散头 | 轻量级模块(4层结构,约1.23亿参数),以LLM输出的隐藏状态为条件;基于去噪扩散概率模型(DDPM)预测声学变分自编码器特征,推理时结合无分类器引导(CFG)与DPM-Solver(及变体)提升生成音质。 |
(2)训练策略:分阶段+课程学习,突破长序列限制
VibeVoice-1.5B的训练分为“分词器预训练”与“框架整体训练”两阶段,且通过课程学习攻克长序列处理难题:
- 分词器预训练:先单独预训练声学分词器与语义分词器,确保两者能精准提取声学、语义特征,为后续整体训练打下基础。
- VibeVoice整体训练:冻结预训练完成的双分词器参数,仅训练LLM与扩散头;针对长序列处理,采用“课程学习法”逐步提升输入序列长度——从4k标记开始,依次过渡到16k、32k,最终支持65,536个标记的最大上下文长度,避免直接训练长序列导致的模型不稳定。
- 数据处理:文本输入依赖Qwen2.5自带的分词器处理,音频输入则通过预训练的声学分词器与语义分词器完成“语音分词”,实现文本与音频特征的匹配。

VibeVoice-1.5B使用边界:明确用途与限制
微软对VibeVoice-1.5B的使用场景进行了严格界定,既明确了研究导向的核心用途,也列出了禁止或不支持的场景,避免技术滥用:
(1)仅支持研究用途
当前版本的VibeVoice-1.5B仅限用于研究目的,核心是探索“高逼真度多说话者对话音频生成”技术(具体可参考官方论文链接),不建议直接用于商业或现实世界应用。
(2)超出范围的用途(禁止或不支持)
- 违法违规使用:违反适用法律、贸易合规法规,或违反MIT许可证的使用方式;
- 声音模仿滥用:未经明确记录同意,克隆真实个人声音用于讽刺、广告、赎金、社交工程或认证绕过;
- 虚假信息传播:创建伪装成真实人物、真实事件的音频,用于冒充或传播虚假信息;
- 实时低延迟场景:不支持电话、视频会议等“实时深度伪造”语音转换;
- 非支持语言:仅在英语、中文数据上训练,其他语言输出可能无法理解或存在冒犯性;
- 非语音音频生成:仅限合成语音,无法生成背景环境音、拟音或音乐。
VibeVoice-1.5B风险与应对:从技术防护到使用建议
尽管经过多轮优化,VibeVoice-1.5B仍存在潜在风险,微软也针对性提出了防护措施与使用建议:
(1)主要风险与限制
- 输出不确定性:可能产生意外、偏见或不准确的音频,且继承了基础模型(Qwen2.5-1.5B)的偏见、错误;
- 深度伪造风险:高质量合成语音可能被用于冒充、欺诈、传播虚假信息;
- 语言与音频类型局限:仅支持英语、中文,不处理非语音音频;
- 对话场景缺失:当前模型不支持生成对话中的重叠语音片段。
(2)风险防护措施
为降低滥用风险,微软在技术层面加入三重防护:
- 可听免责声明:自动在每个合成音频文件中嵌入“此片段由AI生成”的可听提示;
- 不可察觉水印:在音频中添加第三方可验证的隐形水印,用于追溯VibeVoice生成的来源;
- 滥用检测:记录推理请求的哈希值,用于检测异常滥用模式,并每季度发布聚合统计数据。
(3)使用建议
- 不建议未经进一步测试开发,将其用于商业或现实场景,仅限研究;
- 生成内容需确保转录可靠、内容准确,避免误导性使用;
- 分享AI生成音频时,需主动披露“由AI生成”的事实;
- 使用数据集前,需合法获取权利或进行匿名化处理,重视数据隐私。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











