文本到音频(TTA)技术已能生成高质量短音频片段,但面对“雨中追逐场景”“视频配音旁白”这类需要时间连贯性、情感一致性的长篇叙事需求时,传统模型常出现“声音断层”“氛围割裂”等问题。
为此,中国科学院大学人工智能学院、腾讯PCG ARC实验室、中国科学院自动化研究所联合提出长篇叙事音频生成模型AudioStory。它通过“大语言模型(LLM)+TTA系统”的统一框架,将复杂叙事指令拆解为结构化子任务,既保证单段音频的高保真,又实现长篇序列的连贯衔接,还配套构建了AudioStory-10K基准数据集,推动长篇音频生成技术落地。
核心痛点:为什么传统TTA模型做不好“长篇叙事”?
传统TTA模型的优势在于“生成单段短音频”(如10秒的雨声、5秒的汽车鸣笛),但生成长篇叙事音频(通常超过30秒,包含多场景、多声音元素)时,会暴露三大核心问题:
- 时间连贯性差:不同段落的声音衔接生硬,比如“脚步声”突然中断、“雷声”毫无预兆出现,缺乏自然的过渡;
- 情感基调割裂:无法维持统一的情感氛围,比如“紧张追逐场景”中突然混入轻松的鸟鸣,破坏叙事逻辑;
- 组合推理弱:难以协调多声音元素的互动关系,比如“脚步声溅起水花”“汽车打滑”“门砰地关上”这些声音,无法按真实场景的时序和强度搭配(如汽车打滑声应在脚步声之后,门关上后声音逐渐减弱)。
AudioStory的设计核心,正是通过“LLM的叙事规划能力+TTA的音频生成能力”协同,从根本上解决这些问题。
核心能力:三大场景,覆盖长篇音频生成需求
AudioStory不仅能生成长篇连贯音频,还能适配不同输入模态与应用场景,直接满足视频创作、音频节目制作等实际需求:
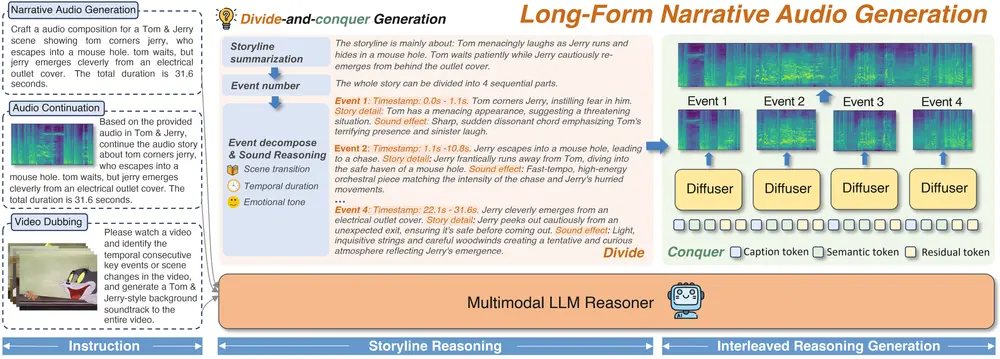
1. 长篇叙事音频合成:从文本指令到完整音频
输入复杂的文本叙事指令,模型能自动拆解并生成连贯的长篇音频序列:
- 例:输入指令“在雨中紧张的追逐:开头是轻柔的雨声,随后传来急促的脚步声(伴随水花溅起),10秒后加入低沉的雷声,接着是汽车急刹打滑的声音,最后以‘砰’的关门声结束,全程保持紧张氛围”;
- 生成效果:音频时长约40秒,各声音元素按指令时序出现,且强度随场景变化(如脚步声随追逐推进逐渐变响,关门声后雨声和雷声缓慢减弱),无断层或突兀感;
- 适用场景:有声小说制作、音频剧创作、游戏场景音效生成。
2. 视频配音:匹配画面的音频生成
输入视频片段(或视频画面描述)+配音需求,模型能生成与画面节奏、情感匹配的音频:
- 例:输入“一段1分钟的动画片段:前30秒是主角在森林中漫步(画面有树叶飘动、小鸟跳跃),后30秒主角遇到小松鼠(画面有松鼠啃坚果、主角笑声)”;
- 生成效果:音频前30秒以轻柔的风声、树叶摩擦声、远处鸟鸣为主,节奏舒缓;后30秒加入清脆的坚果碎裂声、温暖的笑声,情感转为活泼,且音频时长与视频完全同步;
- 适用场景:短视频配音、动画后期音效制作、纪录片背景音生成。
3. 音频续接:扩展已有音频的叙事
输入一段现有音频+续接需求,模型能无缝延续音频的风格、情感和叙事逻辑:
- 例:输入“一段20秒的‘篝火旁聊天’音频(包含柴火噼啪声、两人低声交谈)”+续接指令“继续生成30秒,加入远处的狗叫声,交谈声逐渐变弱,最后以柴火熄灭的‘滋滋’声收尾”;
- 生成效果:续接的30秒音频与原音频音色、音量一致,狗叫声从远到近自然出现,交谈声按指令逐渐减弱,无“拼接感”;
- 适用场景:音频节目续更、直播背景音扩展、会议录音补全。
技术创新:两大核心设计,支撑“连贯+高保真”
AudioStory的性能突破,源于“解耦桥接机制”和“端到端训练”两大关键技术,让LLM的叙事能力与TTA的生成能力深度协同:
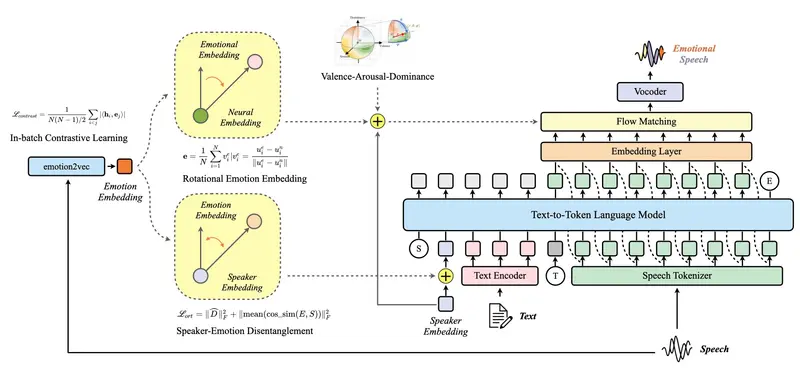
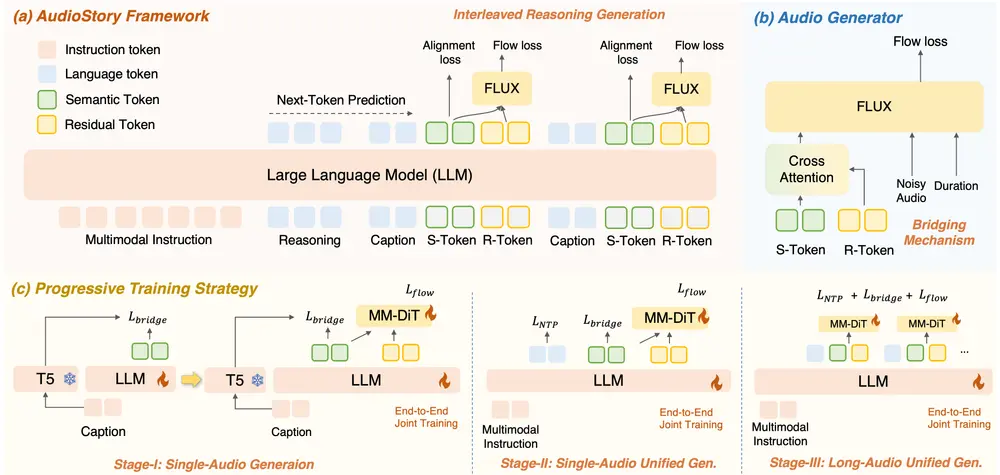
1. 解耦桥接机制:让LLM与音频生成器“分工明确、协同高效”
传统模型中,LLM与音频生成器的协作常出现“信息混淆”(如LLM输出的语义指令与音频生成器的细节需求不匹配)。AudioStory通过“双令牌”设计,将两者协作解耦:
- 语义令牌:由LLM生成,捕捉音频的高层语义信息(如“紧张氛围”“脚步声+雨声”“时序顺序”),确保音频符合叙事逻辑;
- 残差令牌:同样由LLM生成,记录音频的低层细节特征(如脚步声的频率、雨声的音色、音量变化曲线),确保音频生成的高保真;
- 工作流程:两种令牌被同步传递到扩散模型(DiT,音频生成核心),DiT根据语义令牌确定“生成什么”,根据残差令牌确定“怎么生成”,避免信息冲突。
2. 端到端训练:消除模块割裂,增强协同性
传统TTA模型常采用“先训练LLM指令理解模块,再训练音频生成模块”的分阶段方式,导致两模块协同性差。AudioStory则将“指令理解”与“音频生成”统一在单一框架内端到端训练:
- 训练过程:模型直接以“完整叙事指令→最终长篇音频”为训练目标,无需拆分模块;训练中,LLM与音频生成器实时交互调整(如音频生成器反馈“某段细节失真”,LLM会优化对应的令牌输出);
- 优势:避免模块间的“信息损耗”,让LLM的叙事规划与音频生成器的细节还原更匹配,同时减少训练流程的复杂度(无需单独调试模块接口)。
工作原理:四步实现从“指令”到“长篇音频”的转化
AudioStory的工作流程清晰,从输入指令到输出音频可分为四个核心步骤,全程围绕“连贯叙事”展开:
- 指令分解:LLM接收文本/视频/音频输入(及对应的生成需求),将复杂指令拆解为有序的“子任务”——每个子任务包含“声音元素、出现时间、情感基调”等信息(如子任务1:0-10秒,雨声,轻柔,紧张基调;子任务2:10-20秒,脚步声+水花声,急促,紧张基调);
- 桥接查询生成:针对每个子任务,LLM生成“语义令牌+残差令牌”组成的桥接查询,作为音频生成器的“精准指令”;
- 分段音频生成:扩散模型(DiT)接收桥接查询和“子任务持续时间”,生成对应的单段音频(如10秒的雨声、10秒的脚步声+水花声);
- 连贯整合与优化:模型对所有单段音频进行“平滑过渡处理”(如调整相邻音频的音量衔接、补充过渡音效),同时检查整体情感一致性,最终输出完整的长篇音频。
测试表现:多维度领先,配套基准推动行业进步
为验证AudioStory的性能,研究团队进行了全面测试,并构建了行业首个长篇叙事音频基准数据集AudioStory-10K:
1. 定量评估:AudioStory-10K基准上的“全指标第一”
AudioStory-10K包含10000个长篇叙事音频样本,涵盖“动画音景”“自然声音叙事”“人类活动场景”等多个领域,评估指标包括“指令遵循度、时间连贯性、情感一致性、音频保真度”:
- 结果显示,AudioStory在所有指标上均排名第一,其中“时间连贯性”得分比传统TTA模型(如TangoFlux、AudioLDM2)高23%-35%,“情感一致性”得分高18%-28%。
2. 单音频生成:超越现有TTA模型
在传统的“单段短音频生成”任务中,AudioStory同样表现出色:
- 在“音频保真度”(如声音与文本描述的匹配度)、“音色自然度”指标上,超越TangoFlux、AudioLDM2等主流模型,其中“音色自然度”得分高12%-15%,避免了传统模型常见的“机械感”声音。
3. 用户研究:认可度显著高于其他模型
针对200名受试者(含音频创作者、普通用户)的偏好测试显示:
- 在“指令遵循度”“连贯性”“整体质量”“情感匹配度”四项维度上,选择AudioStory的用户占比分别为76.5%、81.2%、78.8%、83.5%,均显著高于其他模型(第二名最高占比仅52.3%)。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











