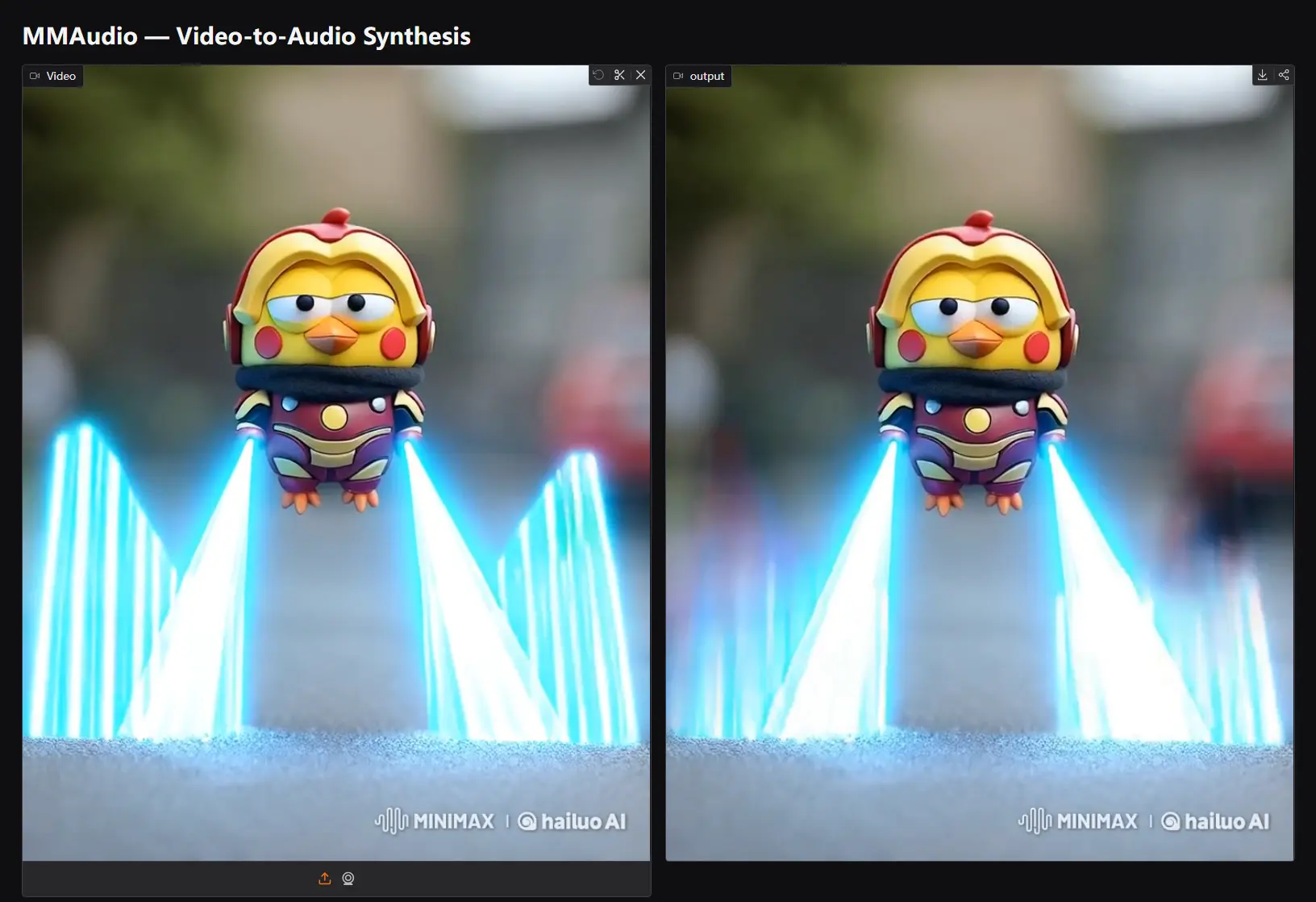
近年来,多模态生成模型在图像、视频和文本等领域取得了显著进展,但将视觉和文本信息与音频生成结合的任务仍然具有挑战性。传统的音频生成方法通常依赖于单一模态(如仅基于文本或仅基于视频),难以实现高质量的音频-视觉或音频-文本同步。为了解决这一问题,伊利诺伊大学厄巴纳-香槟分校、索尼AI和索尼集团的研究人员推出了 MMAudio,这是一个能够根据视频和/或文本输入生成同步音频的系统。
- 项目主页:https://hkchengrex.com/MMAudio
- GitHub:https://github.com/hkchengrex/MMAudio
- Demo:https://huggingface.co/spaces/hkchengrex/MMAudio
- ComfyUI插件:https://github.com/kijai/ComfyUI-MMAudio
MMAudio 的关键创新在于 多模态联合训练,这使得系统可以在广泛的音频-视觉和音频-文本数据集上进行训练,从而更好地捕捉不同模态之间的关联。此外,MMAudio 引入了一个 同步模块,确保生成的音频与视频帧对齐,实现出色的时空一致性。
核心技术与创新点
1. 多模态联合训练
MMAudio 的核心优势在于其 多模态联合训练 框架,该框架允许系统同时从音频-视觉和音频-文本数据中学习。具体来说:
- 音频-视觉数据:系统可以从包含视频和对应音频的大型数据集中学习,理解视频中的动作、场景和物体与相应声音之间的关系。
- 音频-文本数据:系统还可以从包含文本描述和对应音频的数据集中学习,理解文本描述与音频内容之间的映射关系。
通过这种方式,MMAudio 能够在多种输入条件下生成高质量的音频,无论是基于视频输入还是文本输入,甚至是两者的组合。多模态联合训练使得系统能够更好地捕捉不同模态之间的复杂交互,生成更加自然和一致的音频。
2. 同步模块
为了确保生成的音频与视频帧对齐,MMAudio 引入了一个 同步模块。该模块的主要功能是:
- 时空一致性:同步模块通过对生成的音频进行时间对齐,确保音频与视频中的动作、事件和场景变化同步。例如,当视频中的人物说话时,生成的音频应准确反映其语音;当视频中出现某种动作(如敲门、关门等),生成的音频应与该动作的时间点精确匹配。
- 动态调整:同步模块可以根据视频内容的复杂性动态调整音频生成的速度和节奏。例如,在快节奏的动作场景中,生成的音频应更加紧凑和快速;而在缓慢的对话场景中,生成的音频应更加平缓和自然。
通过同步模块,MMAudio 实现了音频与视频的高度同步,确保生成的音频不仅在内容上符合视频场景,而且在时间上也保持一致,提供更加沉浸式的视听体验。
3. 灵活的输入模式
MMAudio 支持多种输入模式,包括:
- 纯视频输入:给定一段没有音频的视频,MMAudio 可以根据视频内容生成相应的音频,使其成为有声视频。
- 纯文本输入:给定一段文本描述,MMAudio 可以根据文本内容生成相应的音频,适用于文本到语音(TTS)任务。
- 视频+文本输入:给定一段视频和相应的文本描述,MMAudio 可以结合两者的信息生成更加丰富和准确的音频,适用于电影配音、解说词生成等场景。
这种灵活性使得 MMAudio 可以应用于多种实际场景,如电影制作、视频编辑、虚拟主播、游戏开发等。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...