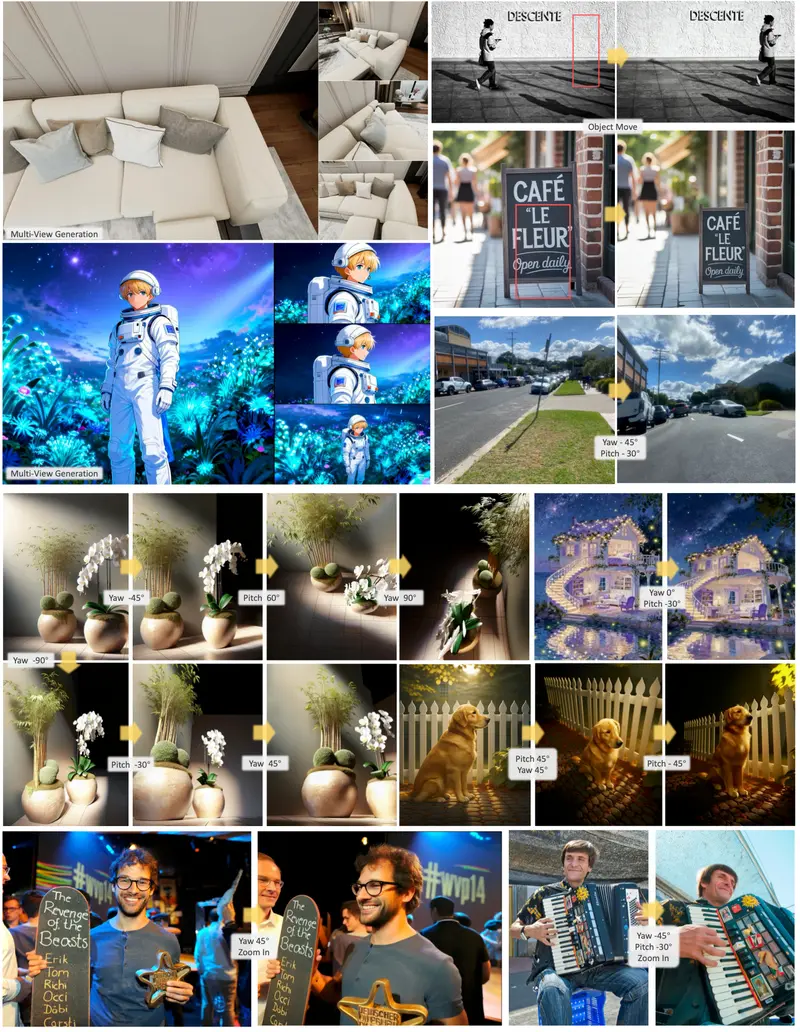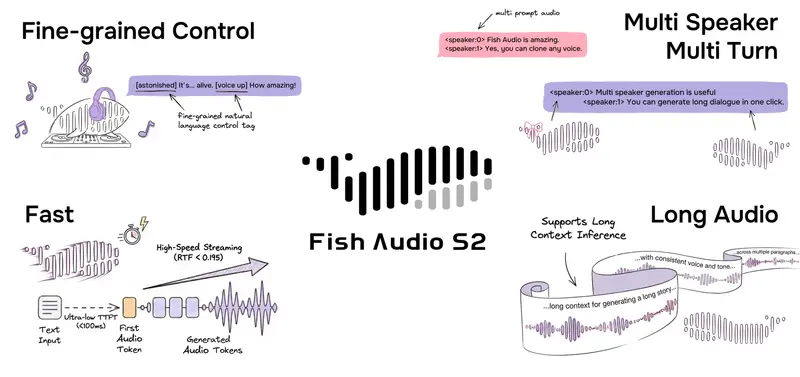
在口语语言建模(Speech Language Modeling)领域,我们长期面临着一个两难选择:是要高压缩率以降低计算成本,还是要高保真度以确保音质清晰?传统的神经音频编解码器往往难以兼得,且常常需要依赖复杂的外部声码器(Vocoder)来重建波形。
MioCodec 带来了突破性的解决方案。其最新发布的 v2 版本 不仅实现了在极低比特率(341 bps)下重建 44.1 kHz 的高保真音频,更通过巧妙的架构设计,让现有的 24kHz TTS 模型能够零成本升级至 44.1kHz 音质。
- GitHub:https://github.com/Aratako/MioCodec
- 模型:https://huggingface.co/Aratako/MioCodec-25Hz-44.1kHz-v2
核心突破:v2 版本的三大杀手锏
MioCodec-25Hz-44.1kHz-v2 并非简单的参数调整,而是一次架构层面的进化。
1. 44.1 kHz 高保真输出
相比基础的 24 kHz 模型,v2 版本将采样率提升至 CD 级标准的 44.1 kHz。这意味着它能还原更丰富的高频细节,让人声和音乐更加自然、通透,彻底摆脱了低采样率带来的“闷罐感”。
2. 集成波形解码器:端到端的高效推理
旧版模型依赖外部声码器(如 MioVocoder)进行波形合成,增加了推理延迟和系统复杂度。
- v2 革新:直接将基于 iSTFTHead 的波形解码器集成到模型内部。
- 优势:无需外部依赖,推理速度更快,部署更轻量,真正实现了从离散令牌到波形的端到端生成。
3. 令牌兼容性:TTS 模型的“免费”音质升级
这是 v2 版本最令人兴奋的特性。
- 原理:在微调过程中,模型的内容分支(Content Branch)被完全冻结。
- 结果:v2 模型生成的离散令牌(Tokens)与 24kHz 版本(MioCodec-25Hz-24kHz)完全一致。
- 应用:任何已经在 24kHz 令牌上训练好的 TTS 模型,无需重新训练,只需在推理阶段将编解码器替换为 v2 版本,即可直接输出 44.1 kHz 的高品质音频。这简直是 TTS 开发者的“免费午餐”。
技术揭秘:UpsamplerBlock + SnakeBeta
如何实现从低分辨率令牌到高分辨率波形的跨越?MioCodec v2 借鉴并改进了 Inworld TTS-1 的架构:
- UpsamplerBlock:负责将标准的 25 Hz 令牌流上采样,恢复出高频信息。
- SnakeBeta 激活函数:这是一种周期性激活函数,特别擅长捕捉音频信号中的高频振荡特征。
- 协同效应:两者的结合使得解码器能够从较低分辨率的输入中,精准预测并生成清晰的高频分量,从而实现完美的 44.1 kHz 重建。
模型家族对比
| 模型版本 | 采样率 | 比特率 | 声码器 | 核心优势 | 推荐场景 |
|---|---|---|---|---|---|
| MioCodec-v2 (推荐) | 44.1 kHz | 341 bps | 内置 (iSTFT) | 音质最佳、无需外置声码器、兼容 24k 令牌 | 生产环境、高音质 TTS |
| MioCodec-Lite | 24 kHz | 341 bps | 内置 (iSTFT) | 轻量级、推理极快 | 移动端、实时交互 |
| MioCodec-Old | 44.1 kHz | 341 bps | 外部 (MioVocoder) | 旧版架构,需额外部署 | 不推荐新项目使用 |
| Kanade 系列 | 24 kHz | 171-341 bps | 外部 (Vocos/HiFT) | 原始基准模型 | 学术研究对比 |
快速上手:安装与推理
安装
推荐使用 uv 进行快速安装(支持 FlashAttention 加速):
# 创建虚拟环境并安装
uv add git+https://github.com/Aratako/MioCodec
# 若需极致性能,建议安装 FlashAttention (需 NVIDIA GPU 和 ninja)
uv pip install flash-attn --no-build-isolation
推理示例:一键合成 44.1kHz 音频
from miocodec import MioCodecModel, load_audio
import soundfile as sf
# 1. 加载模型 (自动下载 44.1kHz v2 版本)
model = MioCodecModel.from_pretrained("Aratako/MioCodec-25Hz-44.1kHz-v2")
model = model.eval().cuda()
# 2. 加载音频
waveform = load_audio("input.wav", sample_rate=model.config.sample_rate).cuda()
# 3. 编码为离散令牌
features = model.encode(waveform)
# 4. 解码为高保真波形 (无需外部声码器)
resynth = model.decode(
content_token_indices=features.content_token_indices,
global_embedding=features.global_embedding,
)
# 5. 保存结果
sf.write("output_44k.wav", resynth.cpu().numpy(), model.config.sample_rate)
进阶玩法:语音转换 (Voice Conversion)
利用 MioCodec 将语音解耦为内容令牌和全局嵌入(说话人特征),轻松实现变声:
# 源音频 (提供内容)
source = load_audio("source.wav", sample_rate=model.config.sample_rate).cuda()
# 参考音频 (提供音色)
reference = load_audio("reference.wav", sample_rate=model.config.sample_rate).cuda()
# 执行转换:源的内容 + 参考的音色
vc_wave = model.voice_conversion(source, reference)
sf.write("converted.wav", vc_wave.cpu().numpy(), samplerate=model.config.sample_rate)© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...