在实时语音处理领域,准确性与低延迟往往难以兼得。传统的开源模型(如 Whisper)虽然精度高,但通常需要收集完整音频片段后才能开始转写,导致显著的延迟,无法满足实时字幕或即时语音助手的需求。
- 模型:https://huggingface.co/mistralai/Voxtral-Mini-4B-Realtime-2602
近日,Mistral AI 正式发布了 Voxtral-Mini-4B-Realtime-2602,一款专为实时流式处理设计的开源语音模型。它仅有 40 亿参数,却能在保持离线级高精度的同时,将延迟控制在 500 毫秒以下,并原生支持中文在内的 13 种语言。
核心突破:真正的“边听边写”
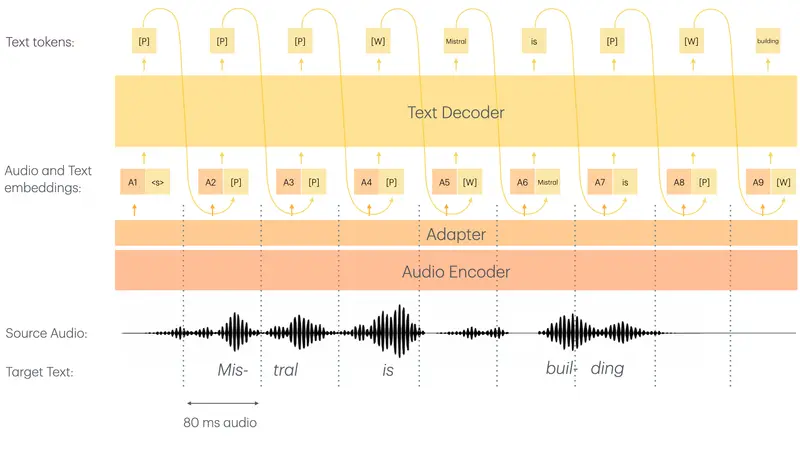
Voxtral-Mini 的最大亮点在于其原生流式架构。与 Whisper 等“先录后转”的模型不同,Voxtral 采用了自定义的因果音频编码器(Causal Audio Encoder)和滑动窗口注意力机制,使其能够像人类一样,听到声音的同时即刻输出文字。
- 超低延迟:在默认配置下,延迟仅为 480 毫秒,用户几乎感觉不到滞后。
- 可配置平衡:开发者可根据场景需求,在
80ms到2400ms之间灵活调整延迟,以平衡极致速度与最高准确率。 - 无限流式传输:得益于滑动窗口设计,模型理论上支持无限时长的连续对话转录,无需担心上下文溢出。
不止于转写:多模态语音理解
Voxtral-Mini 不仅仅是一个语音转文字(ASR)工具,它是一个真正的多模态语音理解模型。在同一个模型中,它集成了以下能力:
- 实时转录:高精度将语音转为文本。
- 语义理解:直接理解语音内容的含义,而非仅仅识别音节。
- 即时摘要与问答:可在会议进行中实时生成摘要或回答基于语音内容的问题。
- 实时翻译:支持跨语言的语音互译。
这意味着,未来的语音助手不再需要“转写 -> 文本理解 -> 回答”的复杂链路,而是可以直接通过 Voxtral 实现端到端的智能交互。
性能表现:小身材,大能量
尽管参数量仅为 4B(其中语言模型约 3.4B,音频编码器约 0.97B),Voxtral-Mini 在基准测试中表现惊人:
- 精度对标离线模型:在 480ms 延迟下,其转录准确率与领先的离线开源模型及商业实时 API 相当。
- 超越现有实时方案:在同等延迟条件下,显著优于其他开源实时基线模型。
- 高效吞吐:在设备端运行时,吞吐量超过 12.5 tokens/秒,确保流畅的实时体验。
部署友好:消费级显卡即可运行
Voxtral-Mini 专为边缘计算和设备端部署优化:
- 硬件门槛低:仅需 16GB 显存 的 GPU(如 RTX 4080/4090 或专业卡 A10/A100 的低配版)即可流畅运行。
- 开源许可:采用 Apache-2.0 许可证,允许自由的商业使用和二次开发。
- 格式灵活:提供 BF16 格式权重,便于量化和集成到 vLLM 等推理框架中。
部署最佳实践
为了获得最佳体验,Mistral AI 官方推荐以下配置:
- 温度设置:始终将
temperature设置为 0.0,以确保转录的确定性和准确性。 - 上下文长度:
- 1 个文本 token 约对应 80ms 音频。
- 若要录制 1 小时会议,理论需
max-model-len >= 45,000。 - 建议直接使用 vLLM 默认实例化,它会自动设置最大长度为 131,072,足以支撑超长对话。
- 通信协议:强烈建议使用 WebSockets 建立音频流会话,以实现最低延迟的数据传输。
- 延迟调整:
- 默认推荐 480ms(性能与延迟的最佳平衡点)。
- 如需调整,可修改配置文件
tekken.json中的"transcription_delay_ms"参数(支持 80-1200ms 间 80 的倍数,以及 2400ms)。
应用场景
Voxtral-Mini 的发布将极大地降低实时语音应用的门槛:
- 实时会议字幕:为在线会议、直播提供低延迟、高准确的多语言字幕。
- 智能语音助手:打造反应迅速、能理解上下文的本地化 AI 助手。
- 隐私敏感场景:由于模型可完全本地部署,适用于医疗、法律等对数据隐私要求极高的转录场景。
- 实时翻译机:构建便携式的跨语言交流设备。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











