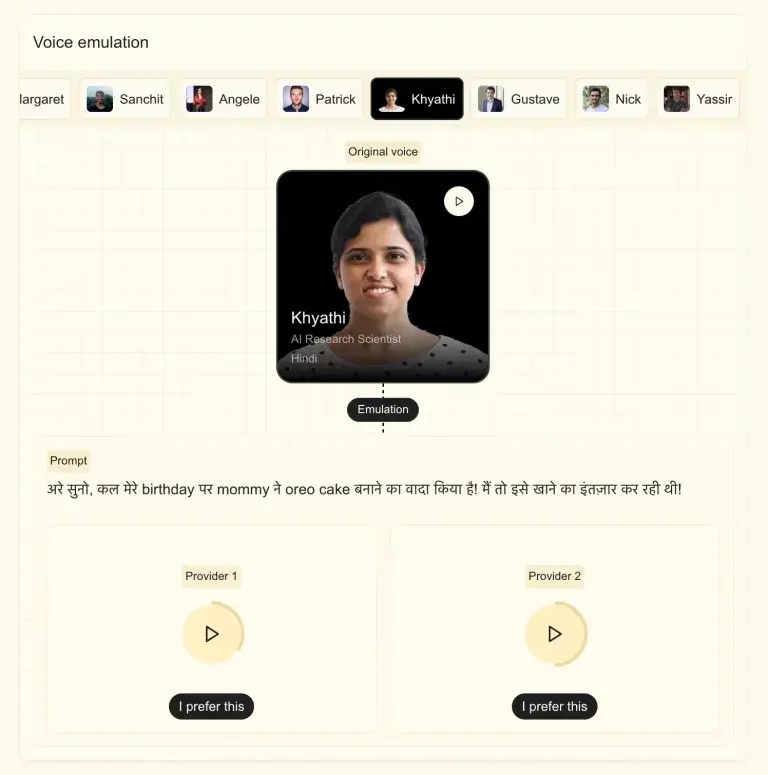
月之暗面开源了一款名为 Kimi-Audio 的通用音频模型。这款模型以其统一的框架和强大的多功能性,在音频处理领域引起了广泛关注。Kimi-Audio 不仅能够处理语音识别、音频问答、字幕生成等任务,还能实现情感识别、声音事件分类以及端到端的语音对话。无论是智能助手应用还是复杂的音频分析场景,Kimi-Audio 都展现出了极高的实用性和灵活性。
例如,你正在使用一个智能助手应用,你对它说:“播放一首轻松的音乐。” Kimi-Audio 可以理解你的指令,识别出“播放”和“轻松的音乐”这两个关键信息,然后从其音频数据库中找到合适的音乐并播放。同时,它还可以实时地将你的语音指令转换为文本,以便更好地理解你的需求。
核心功能:覆盖音频处理全流程
Kimi-Audio 是一个端到端的语音对话模型,支持多种音频相关任务,包括但不限于以下功能:
自动语音识别 (ASR):将输入的语音实时转换为文本,适用于语音转文字的场景。 智能音频问答 (AQA):基于音频内容回答用户提出的问题,例如从一段录音中提取关键信息。 自动音频字幕生成 (AAC):为音频内容自动生成描述性字幕,广泛应用于视频制作和无障碍服务。 精准语音情感识别 (SER):分析语音中的情感特征,帮助理解说话者的情绪状态。 声音事件/场景分类 (SEC/ASC):识别音频中的特定声音事件或背景场景,例如鸟鸣、汽车鸣笛或音乐会现场。 端到端语音对话:实现从语音输入到语音输出的完整对话流程,适用于智能助手、客服机器人等场景。
系统架构:模块化设计,高效协同
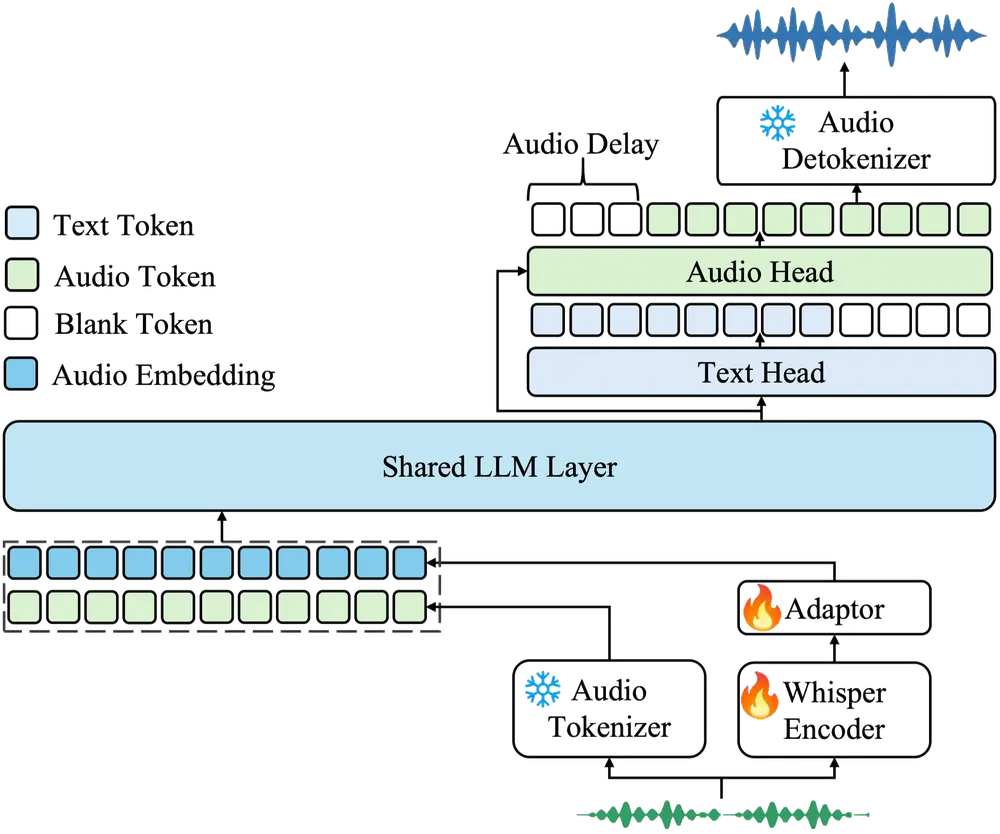
Kimi-Audio 的架构遵循模块化设计原则,由三个主要组件协同工作,以实现高效的音频输入处理和高质量的输出生成。
1. 音频标记器 (Audio Tokenizer)
音频标记器负责将原始音频输入转化为两种类型的特征:
离散语义标记:通过向量量化生成,捕捉音频的语义内容,频率为 12.5Hz。 连续声学特征:从 Whisper 编码器导出,捕捉音频的声学特性,同样以 12.5Hz 的频率生成。
这两种表示形式互补,确保了输入音频的语义和声学特征都能被充分捕捉。
2. 音频 LLM (Audio LLM)
音频 LLM 是整个系统的核心,基于 Transformer 架构构建,并从预训练的文本大模型(如 Qwen 2.5 7B)初始化。其主要特点包括:
共享 Transformer 层:用于处理多模态输入(文本和音频)。 并行头结构:支持自回归生成文本标记和音频语义标记。 温度控制采样:灵活调节生成过程中的随机性,确保输出的多样性和准确性。
3. 音频解标记器 (Audio Detokenizer)
音频解标记器负责将离散的语义音频标记还原为高保真波形,具体流程如下:
使用 Flow Matching Model 从语义标记生成声学特征; 利用 BigVGAN 声码器 将声学特征转换为音频波形; 采用分块流式处理机制,结合前瞻技术,实现低延迟生成。
推理流程:高效且灵活
Kimi-Audio 的推理流程分为以下几个步骤:
模型初始化
用户通过指定模型路径初始化KimiAudio类,并选择是否加载音频解标记器。参数配置
设置音频和文本生成的相关参数,例如采样温度(temperature)和 Top-K 采样策略。消息准备
构建包含文本或音频内容的输入消息,供模型处理。生成过程
调用generate方法,根据需求选择输出类型:仅文本输出:输入音频被标记化后由音频 LLM 处理,直接返回文本结果。 文本和音频输出:在上述基础上增加解标记器步骤,生成高质量的音频输出。
技术亮点与优势
Kimi-Audio 的设计和技术实现具备以下亮点:
统一框架:所有音频处理任务均在一个统一的框架内完成,简化了开发流程并提升了效率。 多模态支持:模型能够同时处理文本和音频输入,适应更广泛的场景需求。 高质量生成:通过先进的声码器和流式处理机制,Kimi-Audio 能够生成高保真的音频输出,满足专业级需求。 开源与可扩展性:作为一款开源模型,Kimi-Audio 提供了高度的透明性和可扩展性,开发者可以根据自身需求进行定制。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











