随着AI在企业系统中的深度集成,对灵活性、效率和透明度兼具的模型需求日益增加。然而,当前市场上的解决方案往往难以满足这些要求:开源模型可能缺乏特定领域的能力,而专有系统则可能限制访问或适应性。尤其在语音识别、逻辑推理和检索增强生成(RAG)任务中,技术碎片化和工具链不兼容的问题尤为突出。

为应对这一挑战,IBM 推出了Granite 3.3,这是一组专为企业应用设计的开放基础模型,涵盖语音处理、推理能力和检索机制三大领域的升级。其中,Granite Speech 3.3 8B是 IBM 首个开源的语音转文本(STT)和自动语音翻译(AST)模型,其在自动语音识别(ASR)和自动语音翻译方面的表现尤为出色。
- 模型:https://huggingface.co/collections/ibm-granite/granite-33-language-models-67f65d0cca24bcbd1d3a08e3
Granite Speech 3.3 8B:语音处理的突破
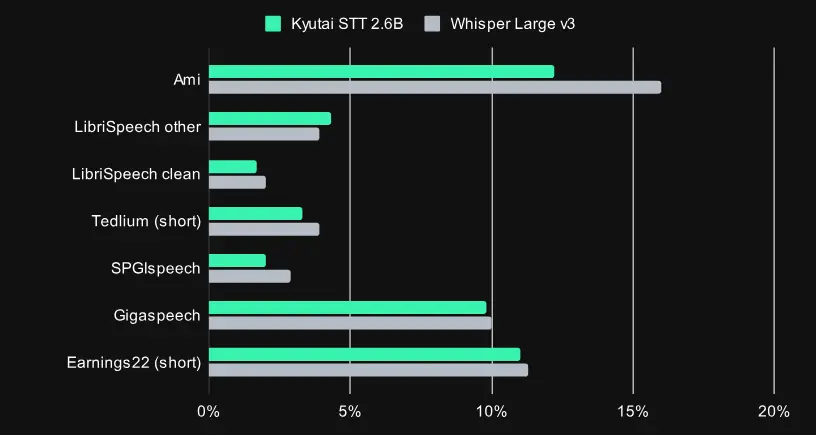
Granite Speech 3.3 8B是 IBM 在语音处理领域的最新成果,旨在解决现有语音模型在长音频序列处理中的瓶颈问题。相比基于 Whisper 的系统,该模型在转录准确性和翻译质量上均实现了显著提升。
模块化架构
Granite Speech 3.3 8B 采用了一种高效的模块化设计,由语音编码器和基于 LoRA(低秩适配器)的音频适配器组成。这种架构允许在特定领域进行高效微调,同时保留基础模型的泛化能力。多语言支持
该模型不仅支持多种语言的语音转文本,还能实现跨语言的自动语音翻译,适用于全球化的应用场景。基准测试表现
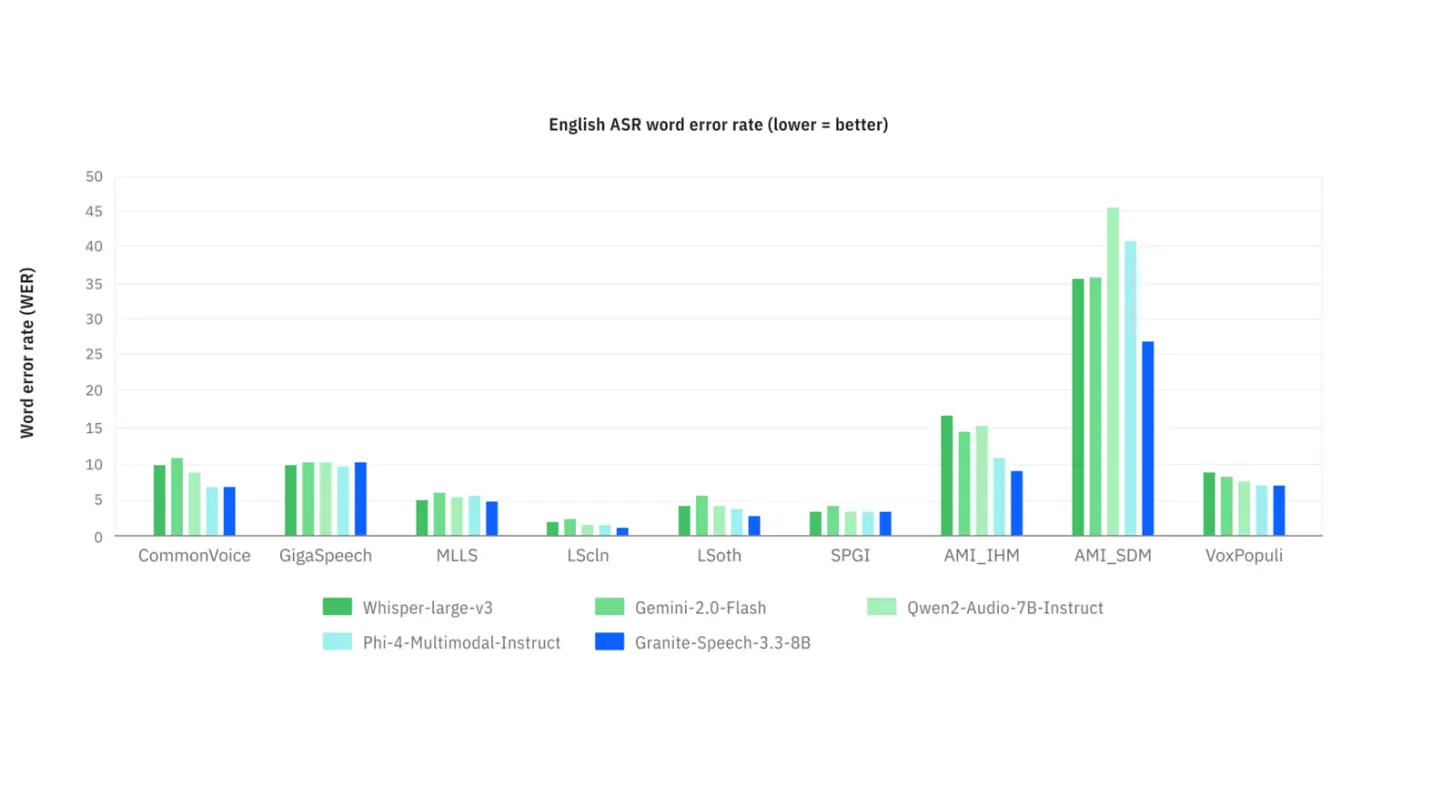
在多种语言的转录和翻译任务中,Granite Speech 3.3 8B 表现出优于基于 Whisper 的基线模型的性能。特别是在扩展的音频输入上,它能够保持连贯性和准确性,避免了常见的漂移问题。
Granite 3.3 Instruct:推理与中间填充的增强
除了语音处理,Granite 3.3 还推出了Granite 3.3 8B Instruct模型,进一步提升了逻辑推理和文档编辑能力。
中间填充(FIM)支持
该模型集成了中间填充(Fill-in-the-Middle, FIM)功能,使其在文档编辑和代码补全等任务中表现出色。例如,用户可以在文档或代码的任意位置插入内容,而模型会根据上下文自动生成合适的补全。符号与数学推理改进
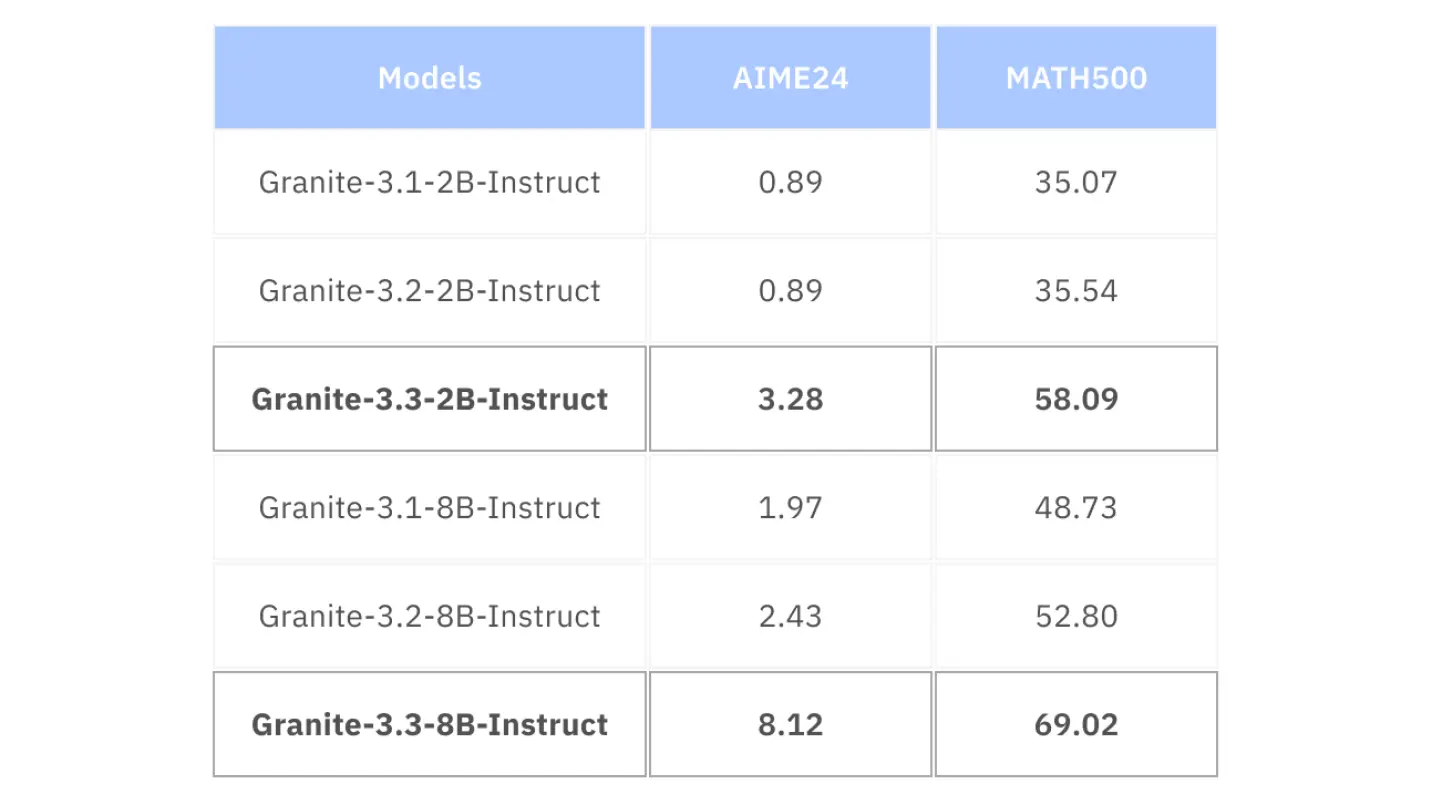
在 MATH500 数据集上的基准测试显示,Granite 3.3 Instruct 在符号推理和数学问题解决方面优于 Llama 3.1 8B 和 Claude 3.5 Haiku 等同类模型。
LoRA 适配器与 aLoRA:优化检索增强生成
Granite 3.3 的另一大亮点是其专门为 RAG 工作流定制的LoRA 适配器和自适应 LoRA(aLoRA)技术。
LoRA 适配器
IBM 推出了五个专为 RAG 定制的 LoRA 适配器,这些适配器能够更好地集成外部知识库,从而提高生成过程中的事实准确性和上下文相关性。aLoRA:内存高效检索
aLoRA 通过在推理会话中重用键值(KV)缓存,显著降低了内存消耗和延迟。这对于流式传输或多跳检索环境尤为重要,帮助企业在动态内容和长上下文查询中实现更高的计算效率。
平台支持与开源发布
IBM 已通过Hugging Face开源并发布了所有 Granite 3.3 模型、LoRA 变体及相关工具。此外,这些模型还支持多种部署选项,包括:
IBM watsonx.ai:IBM 的 AI 平台,提供端到端的企业级解决方案。 第三方平台:Ollama、LMStudio 和 Replicate 等平台也提供了对 Granite 3.3 的支持。
这种广泛的部署选项为企业用户提供了更大的灵活性,同时也鼓励开发者社区参与模型的实验和持续开发。
结论:Granite 3.3 的意义
Granite 3.3的发布标志着 IBM 在开发稳健、模块化和透明的 AI 系统方面迈出了重要一步。通过在语音处理、逻辑推理和检索增强生成领域的技术升级,Granite 3.3 满足了企业在关键任务场景中的需求。
语音处理:Granite Speech 3.3 8B 提供了高准确性的语音转文本和自动语音翻译能力,特别适合需要处理长音频序列的应用场景。 推理能力:Granite 3.3 Instruct 在符号推理和文档编辑任务中的表现优于同类模型。 检索优化:LoRA 适配器和 aLoRA 技术显著提高了检索增强生成的效率和准确性。
通过开源发布,IBM 不仅推动了技术的透明化,还促进了更广泛的 AI 社区参与和创新。Granite 3.3 的推出无疑将为企业应用提供更加可靠的技术选择,并为未来的 AI 发展奠定坚实基础。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











