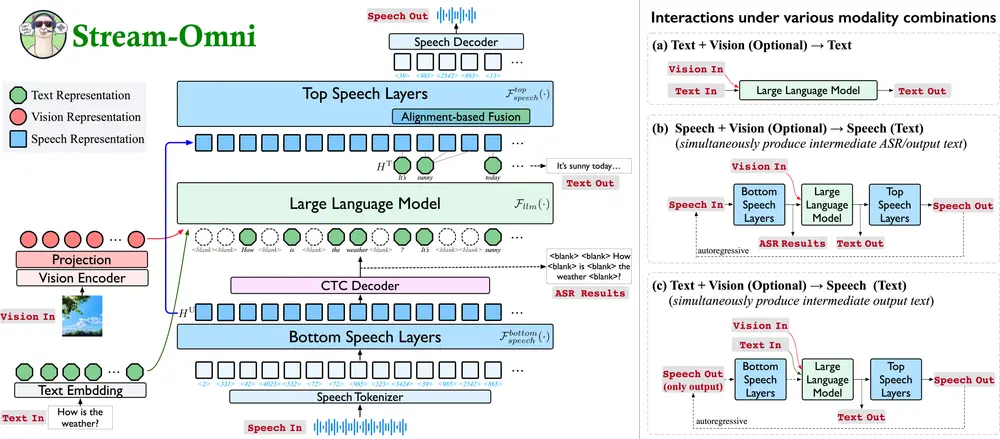
由中国科学院计算技术研究所智能信息处理重点实验室、中国科学院人工智能安全重点实验室以及中国科学院大学联合提出,Stream-Omni 是一种新型的语言-视觉-语音多模态模型。该模型通过高效的模态对齐机制,实现了文本、视觉和语音三类信息的统一理解与生成,支持多种交互方式。
例如,用户可以通过语音提问关于一张图片的内容,Stream-Omni 能够理解图像信息,并以语音形式回答问题,同时提供文字转录,实现真正意义上的“边看边听”。

核心功能概述 💡
Stream-Omni 的设计目标是构建一个能够高效处理多种模态输入并生成对应输出的模型系统。其主要功能包括:
- 全模态交互
- 支持文本、视觉、语音三种模态的组合输入。
- 可输出文本或语音响应,满足多样化应用场景。
- 实时交互体验
- 在语音交互过程中,同步输出中间文字结果(如语音识别转录)和模型响应。
- 类似 GPT-4o 的高级语音服务,提升交互流畅性。
- 训练效率高
- 仅需少量全模态数据即可完成训练,降低数据获取成本。
主要特性解析
1. 多模态交互能力
Stream-Omni 支持多种模态组合的输入与输出,典型场景包括:
- 文本 + 视觉 → 文本(如视觉问答)
- 语音 + 视觉 → 文本/语音(如结合图像的语音指令响应)
- 语音 → 语音(如纯语音对话)
2. 实时响应机制
- 在语音交互过程中,模型可实时生成语音回复,并同步输出文字转录。
- 提升用户在复杂交互中的感知效率和使用体验。
3. 数据高效训练
- 仅使用 23,000 小时语音数据进行训练,显著低于其他模型(如 VITA-1.5 使用 110,000 小时)。
- 在有限资源下实现高质量的跨模态学习。
技术实现原理
Stream-Omni 的核心技术围绕模态对齐和多任务学习展开:
1. 视觉模态处理
- 使用 SigLIP 等视觉编码器提取图像特征。
- 通过序列维度拼接(sequence-dimension concatenation)将视觉特征与文本表示融合,送入大语言模型(LLM)处理。
2. 语音模态处理
- 利用语音编码器将语音信号转化为离散语音单元。
- 基于 CTC 解码器实现语音到文本的层维度映射(layer-dimension mapping),提高对齐效率。
- 该方法可在少量语音数据条件下实现知识迁移。
3. 多任务联合训练
- 将视觉、语音和文本模态联合建模。
- 通过多任务学习方式提升模型在多种模态组合下的泛化能力。
测试表现优异
Stream-Omni 在多个基准测试中展现出良好的性能表现:
1. 视觉理解任务
- 在 VQA-v2、GQA 等视觉问答任务中,平均准确率达 64.7%,接近专用视觉语言模型(如 LLaVA)水平。
2. 语音交互任务
- 在 Llama Questions 和 Web Questions 知识问答任务中:
- 语音到文本(S→T)任务平均准确率为 65.0%
- 语音到语音(S→S)任务平均准确率为 46.3%
3. 视觉引导语音交互
- 在 SpokenVisIT 基准上:
- 视觉+文本→文本任务得分为 3.93
- 视觉+语音→文本任务得分为 3.68
- 视觉+语音→语音任务得分为 2.62
- 表现优于 VITA-1.5 模型
4. 语音识别能力
- 在 LibriSpeech 基准测试中,语音识别词错误率(WER)分别为 3.0% 和 7.2%,优于多个现有语音模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











