
随着大语言模型(LLMs)和音频语言模型的快速发展,AI 在音乐生成领域的能力显著提升,特别是在 歌词到歌曲生成 的方向上取得了突破性进展。
然而,现有方法仍面临两大核心挑战:
- 歌曲结构复杂,难以同时控制人声与伴奏的协调;
- 高质量训练数据稀缺,导致生成音质、歌词对齐度和风格可控性不足。
为解决这些问题,来自清华大学深圳国际研究生院、腾讯 AI 实验室、武汉大学、香港中文大学(深圳)、上海交通大学 X-LANCE 实验室和南京大学智能科学与技术学院的研究团队提出了一种全新框架 —— LeVo(Lyric-to-Song with Language Model and Music Codec),一个融合语言建模与音乐编解码器的端到端高质量歌曲生成系统。
- 项目主页:https://levo-demo.github.io
- GitHub:https://github.com/tencent-ailab/songgeneration
- 模型:https://huggingface.co/tencent/SongGeneration
- Demo:https://huggingface.co/spaces/waytan22/SongGeneration-LeVo
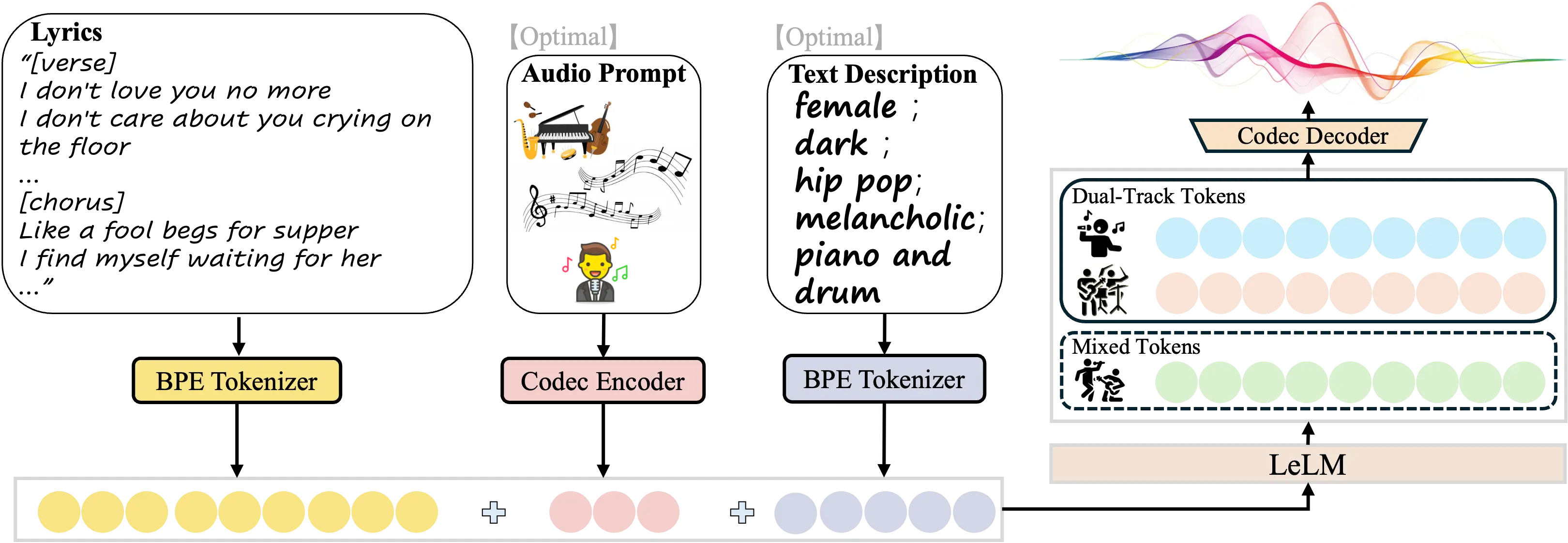
LeVo 架构概览
LeVo 包含两个核心组件:
- 语言模型 LeLM
同时建模两种类型的令牌(token):- 混合令牌(Mixed Tokens):用于捕捉整体旋律、节奏与人声-伴奏关系;
- 双轨道令牌(Dual-track Tokens):分别编码人声与伴奏,以提升音质和音乐性。
- 高效音乐编解码器
- 编码器将原始音频转化为上述两类令牌;
- 解码器将生成的令牌还原为高保真音频。
此外,LeVo 还引入了 模块化扩展训练策略,通过多阶段训练逐步提升模型性能,防止不同类型令牌之间的干扰。
多偏好对齐:提升可控性与音乐性
为了增强模型对指令的理解与执行能力,LeVo 引入了一种基于 直接偏好优化(DPO) 的 多偏好对齐方法。
该方法通过半自动构建多样化偏好数据集,并利用 DPO 微调模型,使其能够更好地满足人类对于:
- 歌词与旋律的一致性;
- 风格描述的匹配度;
- 整体音乐性的审美要求。
这一机制显著提升了 LeVo 在风格控制、歌词对齐和音质方面的表现。
功能亮点
1. 歌词到歌曲生成
输入一段歌词,如:
“I don't love you no more, I don't care about you crying on the floor...”
即可生成完整的歌曲,包括人声与伴奏。
2. 多模态提示控制
支持通过以下方式精细控制输出风格:
- 文本描述:例如“女性声音,黑暗风格,嘻哈流行,忧郁,钢琴和鼓”;
- 音频参考:上传一段旋律作为风格引导。
3. 高质量音频输出
生成的歌曲具有接近专业水准的音质,可用于实际音乐制作场景。
4. 多偏好对齐机制
确保生成结果在歌词对齐、风格匹配和音乐性之间达到最佳平衡。
训练流程详解
LeVo 的训练分为三个主要阶段:
- 预训练阶段:使用大规模未标注音乐数据进行基础建模;
- 模块扩展训练:加入自回归解码器,独立训练双轨令牌生成能力;
- 多偏好对齐训练:基于 DPO 方法优化模型对多样偏好目标的响应能力。
这种渐进式训练策略有效提升了模型的泛化能力和控制精度。
实验评估结果
客观指标表现优异:
| 指标 | LeVo 表现 |
|---|---|
| FAD(音质) | 2.68 |
| PER(歌词对齐) | 7.2% |
| MuQ-T(文本提示匹配) | 0.34 |
| MuQ-A(音频提示匹配) | 0.83 |
| Audiobox-Aesthetic(音乐性/内容享受/生产质量) | CE: 7.78 / CU: 7.90 / PQ: 8.46 |
主观评价全面领先:
在由专业音乐人打分的六个维度中,LeVo 均优于当前开源方法,并与行业领先系统 Suno V4.5 相当甚至更优,具体如下:
- 整体质量(OVL)
- 人声音色吸引力(MEL)
- 人声与伴奏和谐度(HAM)
- 歌曲结构清晰度(SSC)
- 音频音质(AQ)
- 歌词对齐准确性(LYC)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











