Liquid AI 正式推出 LFM2-Audio-1.5B ——一款专为实时交互设计的端到端多模态基础模型,支持音频与文本的任意输入输出组合。
- GitHub:https://github.com/Liquid4All/liquid-audio
- 模型:https://huggingface.co/LiquidAI/LFM2-Audio-1.5B
- API:https://playground.liquid.ai/talk
它仅用 15 亿参数,就能在低延迟条件下实现高质量语音对话、转录、合成与理解任务,适用于边缘设备和资源受限环境。
这不是多个模型拼接的流水线,而是一个统一架构下的原生多模态系统,标志着音频 AI 向“小型化、高效化、一体化”迈出关键一步。

核心能力一览
| 特性 | 说明 |
|---|---|
| 模型规模 | 1.5B 参数(LFM2 系列扩展) |
| 支持模态 | 文本 ↔ 音频(双向自由切换) |
| 输入形式 | 原始波形(无 tokenizer)、文本 token |
| 输出形式 | 离散音频 token、文本 token |
| 端到端延迟 | 平均 <100ms(从输入到首声输出) |
| 推理速度 | 比同类模型快 10 倍以上 |
| 应用场景 | 对话聊天、ASR、TTS、分类、翻译等 |
为什么需要一个新的音频模型?
当前大多数语音 AI 系统依赖复杂管道:
麦克风 → ASR 模型 → LLM → TTS 模型 → 扬声器
这种分步处理带来多重问题:
- 延迟叠加,难以实现实时响应
- 错误传播:前一环节出错,后续无法纠正
- 部署成本高,需维护多个模型和服务
LFM2-Audio 的目标是打破这一链条:用一个模型完成从听懂语音到生成语音的全过程。
架构设计:真正端到端的音频-文本建模
LFM2-Audio 基于 LFM2-1.2B 语言模型扩展而来,但做了关键升级:将音频视为与文本平等的一级模态。
整个模型以“下一令牌预测”为核心机制,在共享语义空间中统一处理两种模态。

双向多模态支持
支持所有六种输入-输出组合:
| 输入 \ 输出 | 文本 | 音频 |
|---|---|---|
| 文本 | ✅ 聊天回复 | ✅ 文本转语音 |
| 音频 | ✅ 语音识别 | ✅ 语音对话 |
| 音频+文本 | ✅ 混合指令理解 | ✅ 多模态响应生成 |
这意味着开发者无需为不同任务部署不同模型。
输入端:无 tokenizer 的原始波形处理
传统音频模型通常先将声音切分为离散 token(如 SoundStream、EnCodec),但这会引入量化伪影,损失细节。
LFM2-Audio 采用无 tokenizer 设计:
- 将原始音频按约 80ms 分段
- 直接投影到模型嵌入空间
- 保持连续特征表示,保留更多声学信息
这种方式避免了早期离散化带来的失真,提升理解质量。
输出端:自回归生成离散音频 token
尽管输入是连续的,生成阶段仍使用离散音频 token,原因如下:
- 更适合自回归建模(与文本 token 统一对待)
- 解码器可批量输出,提高效率
- 支持高质量重建
每个音频 token 代表一小段声音(约 40ms)。LFM2-Audio 在每一步最多可生成 8 个 token,相当于一次解码 320ms 的音频流,显著加快整体响应速度。
最终,这些 token 被送入解码器还原为原始波形,形成自然流畅的语音输出。
性能表现:小模型,大能力
在 VoiceBench 上超越更大模型
VoiceBench 是一个包含 9 项音频交互任务的综合评测集,涵盖语音识别、情感识别、意图理解、对话连贯性等多个维度。
| 模型 | 参数量 | VoiceBench 得分 |
|---|---|---|
| LFM2-Audio-1.5B | 1.5B | 56.8 |
| Whisper-large-v3 | ~1.5B | ~54.2 |
| 其他专用 ASR 模型 | >10B | ≤55.0 |
尽管并非专用于 ASR,LFM2-Audio 在词错误率(WER)上仍达到甚至优于 Whisper-large-v3 的水平。
这证明:通用模型可以在不牺牲特定任务性能的前提下,实现多功能集成。

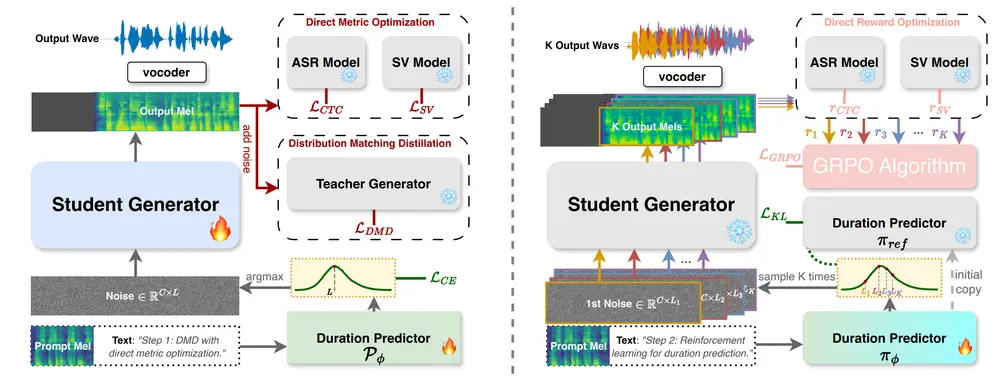
极致低延迟:平均响应时间 <100ms
对于实时语音交互(如车载助手、智能音箱),用户对延迟极为敏感。
测试条件:输入 4 秒语音,测量从结束说话到模型发出第一个声音的时间(TTFS, Time to First Speech)。
| 模型 | 平均延迟 |
|---|---|
| LFM2-Audio-1.5B | <100ms |
| 典型级联系统(ASR+LLM+TTS) | >800ms |
如此低的延迟得益于:
- 端到端架构减少中间环节
- 输入无需预处理编码
- 批量音频 token 解码加速生成
这让对话体验更接近人与人之间的自然交流节奏。

应用场景:从单一功能到统一平台
凭借其灵活性与高效性,LFM2-Audio 可替代传统多模型架构,支撑多种应用:
| 应用 | 实现方式 |
|---|---|
| 实时语音助手 | 输入语音 → 模型直接输出回应语音 |
| 会议转录 | 流式接收音频 → 实时输出文字记录 |
| 多语言翻译 | 接收语音 → 输出目标语言语音或文本 |
| 情感/意图分类 | 分析语音内容并返回标签 |
| RAG 语音助手 | 结合外部知识库,生成带引用的回答 |
| 车载语音控制 | 本地部署,低延迟响应指令 |
尤其适合需要本地运行、数据不出设备、低功耗的场景。
如何开始使用?
Liquid AI 已发布配套 Python 包,包含:
- 模型推理代码
- 实时语音对话应用参考实现
- 音频预处理与后处理工具
开发者可通过该包快速构建基于 LFM2-Audio 的原型系统,并部署至移动端或边缘设备。
意义与展望
LFM2-Audio 不只是一个更快的语音模型,而是提出了一种新的范式:
用一个紧凑模型,统一处理感知与生成任务。
它的出现意味着:
- 更少的模型维护成本
- 更短的响应延迟
- 更高的隐私保障(可在设备端运行)
- 更灵活的应用开发路径
随着硬件推理能力提升,这类轻量级、多功能的基础模型将成为下一代对话 AI 的核心组件。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











