NineNineSix 团队近日推出 KaniTTS ——一个专为低延迟、高保真语音合成设计的开源文本到语音(TTS)系统。
- GitHub:https://github.com/nineninesix-ai/kani-tts
- 模型:https://huggingface.co/nineninesix
- Demo:https://huggingface.co/spaces/nineninesix/KaniTTS
它采用创新的两阶段架构,结合大型语言模型与轻量级声码器,在保持高质量发音的同时,显著降低推理延迟,适用于实时对话 AI、边缘部署和辅助技术等多种场景。
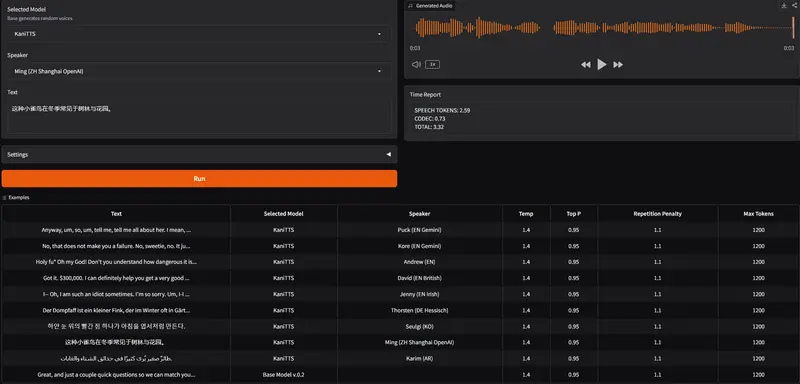
该模型已开源,采用 Apache 2.0 许可证,支持多语言,并已在 GitHub 上线。
核心架构:语义建模 + 高效合成
KaniTTS 采用分步处理流程,将任务解耦为两个关键阶段:
第一阶段:语义与声学令牌生成
骨干模型:LiquidAI LFM2-350M
- 输入:原始文本(含标点及可选韵律标记)
- 功能:分析句法、语义和韵律特征(如重音、停顿、语调),生成压缩的离散音频令牌序列
- 训练数据:约 80,000 小时的多语言语音-文本对(来自 LibriTTS、Common Voice、Emilia 等公共数据集)
- 输出:紧凑的音频令牌流,比原始波形小数个数量级
这一阶段利用预训练语言模型的强大上下文理解能力,实现自然流畅的语音规划。
第二阶段:波形重建
声码器:NVIDIA NanoCodec
- 输入:由第一阶段生成的音频令牌
- 功能:将离散令牌高效解码为连续高保真音频波形
- 特点:轻量级、高度优化,专为实时推理设计
- 输出:采样率为 22kHz 的原始音频(如 WAV 格式)
NanoCodec 的极快解码速度是整体低延迟的关键所在——其合成时间几乎可忽略不计。
为何这种架构更高效?
传统端到端 TTS 模型通常直接从文本生成波形,计算密集且难以并行化。
KaniTTS 的优势在于:
- 第一阶段高度并行:LLM 可一次性生成整段令牌
- 第二阶段极速执行:NanoCodec 接近即时完成波形还原
- 整体延迟可控:主要耗时在令牌生成,后续合成几乎无等待
💡 这种“先思考,再发声”的模式,更接近人类语言输出机制。
性能表现
| 指标 | 数据 |
|---|---|
| 模型参数总量 | 370M |
| 音频采样率 | 22 kHz |
| 自然度 MOS 评分 | 4.3 / 5.0 (主观听感评估) |
| 词错误率(WER) | < 5% (标准测试集) |
| 推理硬件 | NVIDIA RTX 5080 类设备 |
| 15 秒音频生成耗时 | ≈ 1 秒 |
| GPU 显存占用 | ≤ 2GB VRAM |
这意味着 KaniTTS 能够在消费级显卡上实现接近实时的语音输出,非常适合资源受限环境下的部署。
支持语言与适用场景
✅ 支持语言
- 核心训练语言:英语
- 多语言扩展支持:阿拉伯语、中文、德语、韩语、西班牙语
可通过在目标语言数据上继续预训练或微调,进一步提升非英语语音的表现力和口音准确性。
使用技巧与优化建议
- 多语言优化
在目标语言语料上持续预训练 LFM2 骨干模型,并可考虑微调 NanoCodec,以改善发音和语调。 - 批量处理提升吞吐
对于高并发服务,建议使用 batch size 8–16,充分利用 GPU 并行能力,降低单位延迟。 - Blackwell 架构加速
模型可在 NVIDIA Blackwell 架构 GPU 上高效运行,适合大规模实时语音系统部署。
局限性说明
- 对长文本(>2000 token)可能出现节奏不稳定
- 情感表达基础,高级表现力需额外微调
- 基于公共数据训练,可能存在轻微口音或发音偏差
- 当前未内置精细的情感/语气控制接口
负责任使用声明
KaniTTS 严格禁止用于以下行为:
- 生成违法、有害、诽谤或煽动性内容
- 制作虚假信息或未经同意模仿他人声音(deepfake)
- 恶意用途,如钓鱼、诈骗、垃圾信息传播
使用者须遵守所有适用法律法规,并承诺道德使用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...