在生成式 AI 的浪潮中,从文本到图像、视频再到语音,自动化内容创作正变得越来越完整。
ComfyUI-KaniTTS 是一个专为 ComfyUI 设计的自定义节点,集成了 KaniTTS——一种面向实时对话优化的高性能文本转语音(TTS)模型家族。
它让创作者能够在无需离开 ComfyUI 工作流的前提下,直接将脚本转化为自然流畅的语音输出,特别适合用于 AI 动画、虚拟角色、游戏配音和交互式应用开发。
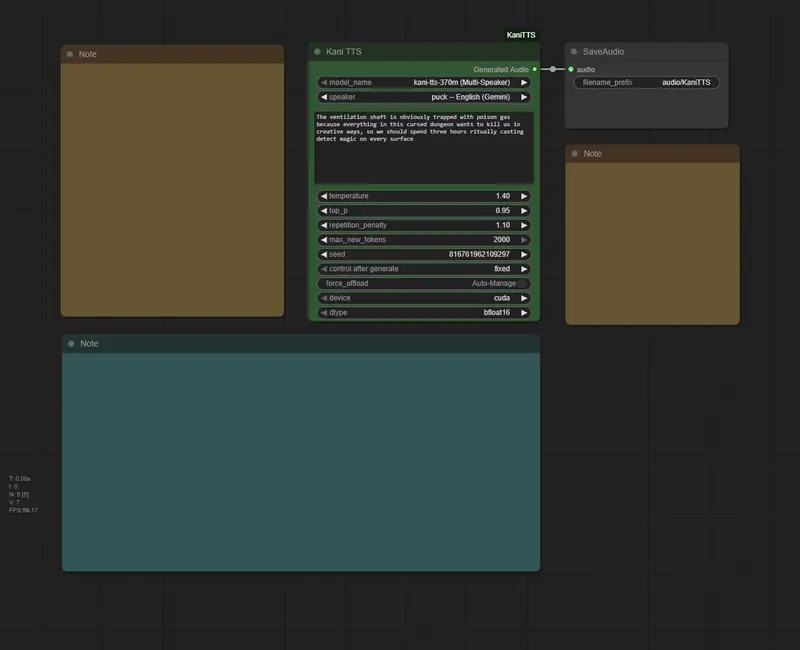
什么是 KaniTTS?
KaniTTS 是一套由九九六科技(nineninesix)研发的先进 TTS 模型系列,其核心目标是实现:
✅ 高保真音质
✅ 极低延迟推理
✅ 多语言、多说话人支持
不同于传统端到端模型,KaniTTS 采用两阶段架构:
- 使用强大的语言模型生成离散语音令牌(Speech Tokens)
- 通过高效的 NeMo 编解码器还原为高质量音频
这一设计使其能在现代 GPU 上以 不到 1 秒的时间生成 15 秒语音,非常适合边缘设备或低成本服务器部署。
核心功能亮点
多说话人支持(kani-tts-370m)
kani-tts-370m 模型内置多种预定义声音,涵盖多国语言与口音,可直接选择使用:
| 声音 | 语言/特征 |
|---|---|
| david | 英语(英国) |
| jenny | 英语(爱尔兰) |
| simon, andrew, katie | 标准英语男性/女性 |
| seulgi | 韩语 |
| thorsten | 德语(黑森地区) |
| maria | 西班牙语 |
| mei | 粤语 |
| ming | 中文(上海口音,OpenAI 训练数据) |
| karim, nur | 阿拉伯语 |
也可留空 speaker=None 实现随机发声。
支持五种主流 KaniTTS 模型
| 模型名称 | 参数量 | 类型 | 特点 |
|---|---|---|---|
kani-tts-370m | 370M | 多说话人 | 支持多语言预设声线,灵活度最高 |
kani-tts-450m-0.1-pt | 450M | 基础版 | 英文预训练,生成通用随机声音 |
kani-tts-450m-0.1-ft | 450M | 微调版(男声) | 固定一致的男性角色音 |
kani-tts-450m-0.2-pt | 450M | 多语言基础版 | 支持 EN/DE/AR/CN/KR/FR/JP/ES |
kani-tts-450m-0.2-ft | 450M | 微调版(女声) | 固定一致的女性角色音 |
所有模型均自动下载并缓存至 ComfyUI/models/tts/ 目录,由节点统一管理。
细粒度语音控制参数
用户可通过调节以下参数精细控制语音风格与稳定性:
| 参数 | 说明 |
|---|---|
temperature | 控制生成随机性。值越高越“有创意”,但可能失真;建议 0.6–1.0 |
top_p | 核采样阈值,过滤低概率词项,影响多样性 |
repetition_penalty | 抑制重复发音,减少机械感 |
max_new_tokens | 限制生成语音长度,防止 OOM |
seed | 设置固定种子可复现结果,-1 表示每次随机 |
高效资源管理
- 自动下载所需模型(包括 NeMo 解码器)
- VRAM 智能加载与卸载(支持
force_offload) - 可指定设备(
cuda,cpu)与精度(bfloat16,float16),推荐现代 GPU 使用bfloat16
快速安装指南
方法一:通过 ComfyUI Manager 安装(推荐)
- 打开 ComfyUI
- 进入 Manager → Custom Nodes
- 搜索
ComfyUI-KaniTTS - 点击「Install」即可完成安装
方法二:手动安装
cd ComfyUI/custom_nodes/
git clone https://github.com/wildminder/ComfyUI-KaniTTS.git
安装依赖
cd ComfyUI-KaniTTS
pip install -r requirements.txt
⚠️ Windows 用户注意:
nemo_toolkit等包需编译 C++ 扩展,在默认环境下常安装失败。
推荐解决方案:使用预编译 .whl 文件
| 包名 | 版本 | Python 版本 | 下载地址 |
|---|---|---|---|
nemo_toolkit | 2.6.0rc0 | 3.12 / 3.13 | nemo_toolkit-2.6.0rc0-py3-none-any.whl |
pynini | 2.1.6.post1 | 3.12 | pynini-2.1.6.post1-cp312-cp312-win_amd64.whl |
pynini | 2.1.7 | 3.13 | pynini-2.1.7-py313.whl |
editdistance | 0.8.1 | 3.13 | editdistance-0.8.1-cp313-cp313-win_amd64.whl |
megatron_core | 0.13.1 | 3.12 | megatron_core-0.13.1-cp312-cp312-win_amd64.whl |
megatron_core | 0.13.1 | 3.13 | megatron_core-0.13.1-cp313-cp313-win_amd64.whl |
texterrors | 1.0.9 | 3.12 | texterrors-1.0.9-cp312-cp312-win_amd64.whl |
texterrors | 1.0.9 | 3.13 | texterrors-1.0.9-cp313-cp313-win_amd64.whl |
安装命令示例:
pip install path/to/downloaded/file.whl
使用步骤
- 启动 ComfyUI
- 在节点菜单中找到 audio/tts → Kani TTS
- 将节点拖入工作区
- 配置输入参数:
model_name: 选择目标模型speaker: (仅 370m 模型可用)选择特定声音text: 输入待合成文本- 其他参数按需调整
- 提交队列,等待生成音频文件
首次运行时会自动下载对应模型,后续无需重复。
如何选择合适的模型?
根据你的使用场景,推荐如下:
场景一:需要多样化角色配音 → 使用 kani-tts-370m
- ✅ 优势:支持多个预设声音,跨语言表现优秀
- 📌 示例:制作多语种动画短片、虚拟主播对话系统
场景二:固定角色设定(如主角男/女声)→ 使用微调模型
kani-tts-450m-0.1-ft:稳定男性声音kani-tts-450m-0.2-ft:稳定女性声音- ✅ 优势:语气一致性高,适合长期角色塑造
场景三:创意实验或声音探索 → 使用基础模型
kani-tts-450m-0.1-pt或0.2-pt- 每次生成不同声音(除非固定 seed)
- ✅ 适合原型设计、A/B 测试、艺术创作
注意事项与限制
❌ 不支持的功能
- 不支持声音克隆:无法从用户上传的音频中提取声纹
- 无情感标签控制:情感表达依赖模型内在能力,不能精确指定“愤怒”“悲伤”等情绪
- 长文本性能下降:输入超过 2000 tokens 时可能出现质量衰减
⚠️ 技术风险
- 模型基于公开数据集训练,可能存在口音或韵律偏差
- 某些依赖项(如
pynini)在 Windows 上安装困难,建议使用 Conda 或专用 Python 环境
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...