昆仑万维旗下 SkyReels 团队 发布了全新音视频生成模型——SkyReals-Audio,一个用于合成高保真、时间一致的“会说话”肖像视频的统一框架。
- 项目主页:https://skyworkai.github.io/skyreels-audio.github.io
- GitHub:https://github.com/SkyworkAI/SkyReels-A2
该模型基于预训练视频扩散变换器(Video Diffusion Transformer),支持通过文本、图像和音频等多模态输入,实现对动态肖像的精细控制与长视频生成,为虚拟人、数字主播、AI 视频创作等领域提供了全新的解决方案。

什么是 SkyReels-Audio?
SkyReels-Audio 是一个音频驱动的肖像视频生成系统,具备以下核心能力:
- 支持任意长度视频生成
- 基于多模态输入条件控制(文本 + 图像 + 音频)
- 实现高保真唇形同步、面部表情与头部动作匹配
- 确保长时间序列下的视觉一致性与自然流畅
这一框架不仅可用于生成新视频,还可用于对已有视频进行编辑与风格迁移。
主要功能亮点
| 功能 | 描述 |
|---|---|
| 高保真动态肖像生成 | 生成与音频高度同步的动态人物形象,涵盖多种表情、口型、头部动作 |
| 无限视频生成 | 支持从单张图片和音频出发,生成任意时长的视频,适用于直播、故事叙述等场景 |
| 多模态条件控制 | 可结合文本描述、参考图像或视频片段,灵活调整生成结果 |
| 音频驱动动画生成 | 利用语音信号自动控制嘴部运动、表情变化,实现自然的视听同步 |
核心技术特点
✅ 多模态融合:不只是听声“动嘴”
SkyReels-Audio 不仅依赖音频驱动,还引入了文本、图像等多种输入形式,实现了更丰富的内容控制:
- 输入一张静态肖像图
- 搭配一段音频(如演讲录音)
- 再加一句描述(如“情绪激动、动作幅度大”)
即可生成一段自然、生动且与音频完美同步的动态视频。
✅ 时间一致性保障:滑动窗口去噪 + 双向潜在融合
为确保长时间视频的视觉连贯性,SkyReels-Audio 引入了两项关键技术:
- 滑动窗口去噪机制
- 将长视频划分为重叠窗口处理
- 在相邻帧之间建立语义联系,避免跳跃感
- 双向潜在空间融合算法
- 融合前后时间段的潜在表示
- 提升时间连续性和画面稳定性
✅ 局部细节增强:面部掩码损失 + 免分类器引导
为了提升关键区域(如嘴唇、眼睛)的表现力,团队引入了:
- 面部区域掩码损失(Facial Mask Loss):加强对局部区域的控制精度
- 音频引导免分类器指导(Audio-Guided CFG):无需额外标签即可实现高质量音频-视觉同步
✅ 混合课程学习策略:逐步对齐音频与面部动作
SkyReels-Audio 使用了一种渐进式训练方法:
- 从短片段开始训练,逐步过渡到长序列
- 使模型逐步掌握音频与面部动作之间的复杂映射关系
这种策略显著提升了模型在复杂语境和多样化表达中的泛化能力。
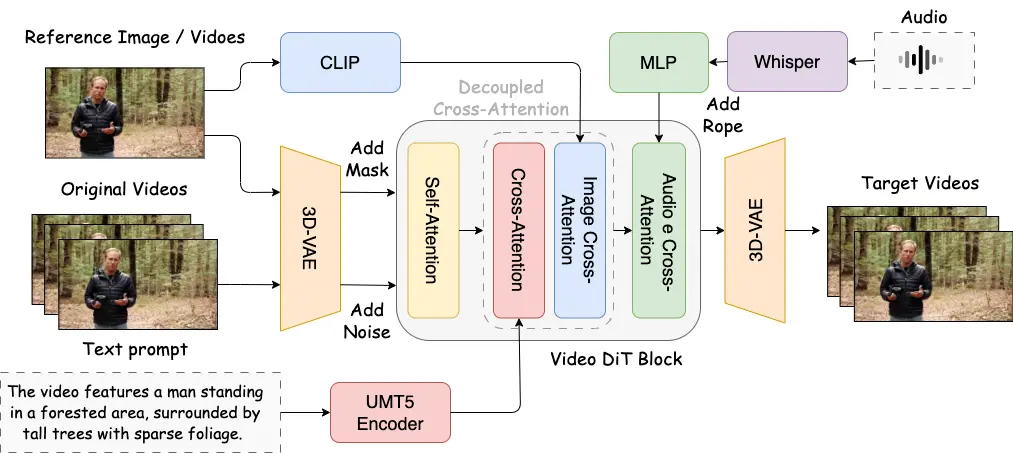
工作原理简析
SkyReels-Audio 的核心流程如下:
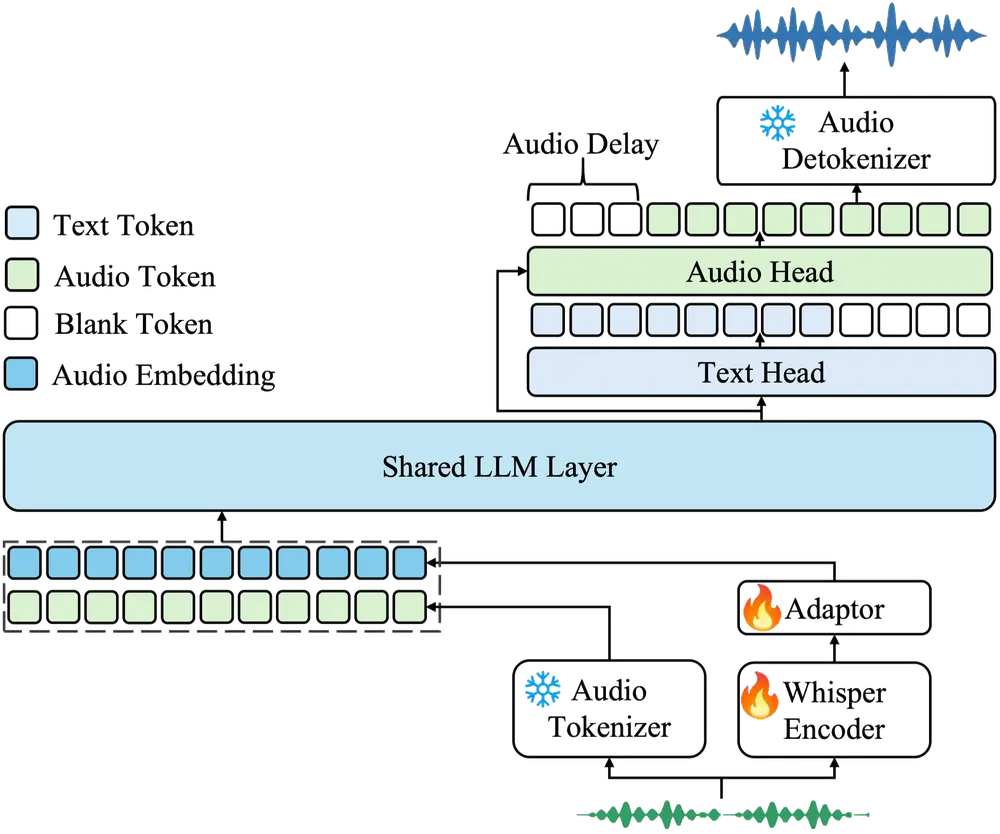
1. 多模态输入处理
- 音频特征提取:使用 Whisper 编码器提取音频嵌入
- 图像/视频编码:通过 3D VAE 提取视觉特征,并与噪声拼接
- 文本描述解析:UMT5 编码器将文本指令转换为上下文嵌入
2. 条件融合与扩散建模
- 所有模态信息通过交叉注意力机制融合
- 利用扩散变换器逐步去噪,生成高质量视频帧
3. 时间一致性优化
- 滑动窗口机制确保帧间过渡自然
- 双向潜在融合保持长时间一致性
实测性能优异
在 HDTF 数据集上的测试结果显示,SkyReels-Audio 表现出明显优于现有开源模型的性能:
| 指标 | SkyReels-Audio 表现 |
|---|---|
| FID(图像质量) | 38.32(越低越好) |
| FVD(视频动态质量) | 364.71(越低越好) |
| Sync-C(音频同步准确性) | 6.06(越高越好) |
| Sync-D(唇形同步准确率) | 9.12% 错误率 |
此外,在用户调研中,SkyReels-Audio 在身份一致性、表情自然度和唇形同步方面均获得好评。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...