
在自动音乐生成领域,生成一首具备完整结构、风格统一、人声与伴奏和谐融合的全长歌曲,依然是极具挑战性的任务。
现有方法——无论是基于语言模型的自回归生成,还是基于扩散模型的音频合成——往往面临两难困境:
- 要么局部细节丰富但整体结构松散,
- 要么结构清晰但音质粗糙或歌词错位。
为突破这一瓶颈,来自香港中文大学(深圳)、腾讯AI实验室、南京大学 与 深圳市大数据研究院 的研究团队联合提出 SongBloom —— 一种全新的全长度歌曲生成框架。该模型通过“自回归草图 + 扩散精修”的交错生成范式,有效平衡了全局连贯性与局部保真度,在主客观评估中均显著优于现有开源方案,并达到与当前商业顶尖平台(如 Suno-v4.5)相媲美的表现。
- 项目主页:https://cypress-yang.github.io/SongBloom_demo/
- GitHub:https://github.com/Cypress-Yang/SongBloom
- 模型:https://huggingface.co/CypressYang/SongBloom
- ComfyUI插件:https://github.com/fredconex/ComfyUI-SongBloom
核心目标:生成真正“像歌”的音乐
SongBloom 的设计目标明确:
不只是生成一段旋律或哼唱,而是创作出具有主歌-副歌结构、器乐过渡段落、语义对齐歌词和风格一致编曲的完整歌曲。
例如:
给定一段歌词和一个10秒的参考音频片段(可为人声或纯音乐),SongBloom 可自动生成长达 150秒 的完整歌曲,涵盖人声演唱、和声、节奏、配器等多维度内容,且保持整体结构合理、情绪递进自然。
主要功能
| 功能 | 说明 |
|---|---|
| ✅ 全长度歌曲生成 | 支持从歌词生成包含多个段落(Verse, Chorus, Bridge 等)的完整歌曲 |
| ✅ 高保真音频输出 | 生成具有丰富细节、清晰人声与自然伴奏的高质量音频 |
| ✅ 语义对齐 | 确保歌声内容与输入歌词一致,减少错词、漏词 |
| ✅ 风格一致性 | 基于参考音频片段,保持旋律走向、节奏型与音色风格统一 |
关键技术特点
1. 交错生成范式(Sketch-and-Refine with Interleaving)
SongBloom 创新性地采用 “草图绘制 → 细节精修 → 循环交错” 的生成流程:
- 第一阶段:自回归草图生成
使用 Transformer 解码器逐步生成粗粒度的语义标记(如歌词对齐的音素序列、节奏轮廓),形成音乐“骨架”。 - 第二阶段:非自回归扩散精修
基于 DiT(Diffusion Transformer)架构,并行预测每个时间块的声学潜变量,恢复高保真波形细节。 - 关键机制:交错执行
将语义与声学序列划分为固定长度块,交替生成。每一步都可利用前序块的语义与声学上下文,实现双向信息流动。
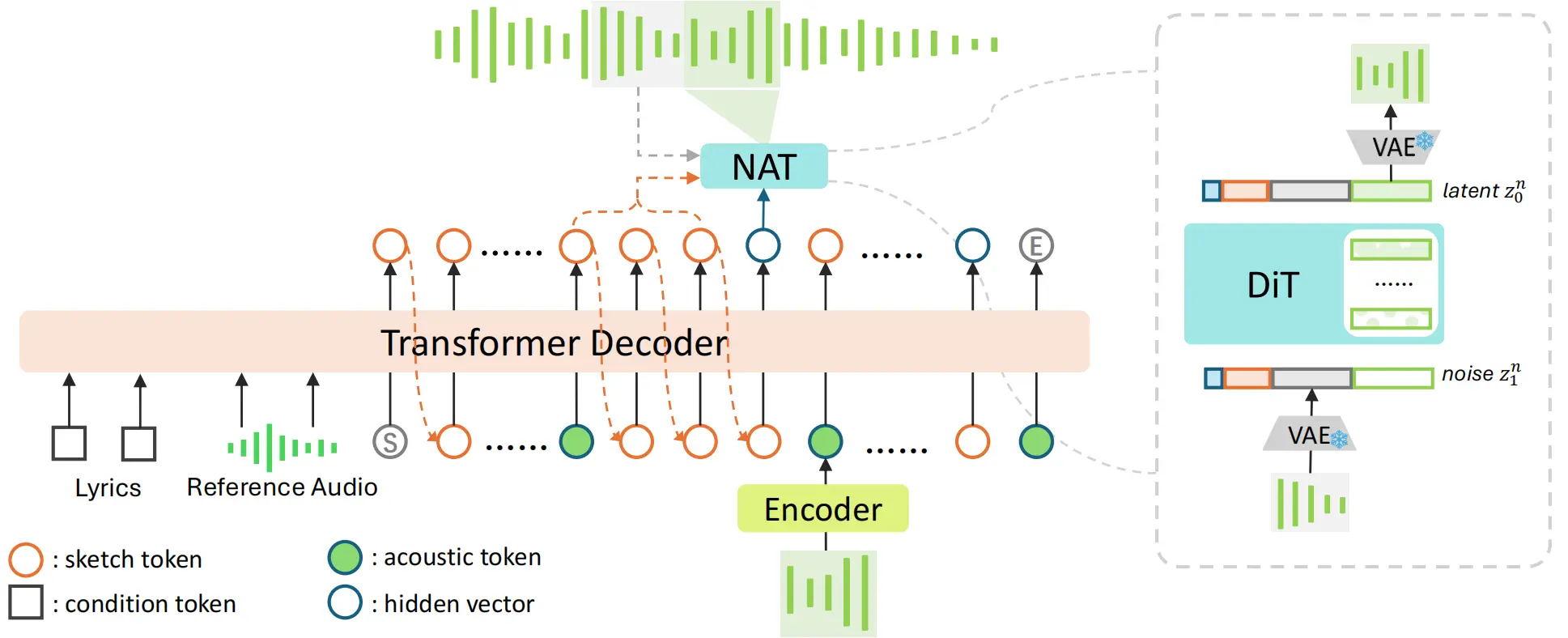
🔄 这种设计既保留了自回归模型的长程结构建模能力,又发挥了扩散模型在音质还原上的优势。
2. 自回归扩散混合架构
不同于传统纯自回归或纯扩散路线,SongBloom 构建了一个统一的自回归扩散框架:
- 适用于连续值模态(如音频潜变量)
- 支持长序列建模(>100秒)
- 可扩展性强,便于引入多模态条件(歌词、参考音频、风格标签)
训练目标采用 Rectified Flow Matching(RFM),提升收敛效率与生成稳定性。
3. 双向上下文融合机制
通过将语义流与声学流分块交错处理,模型在生成当前块时:
- 可访问已生成的语义草图(指导歌词与节奏)
- 同时感知前序声学细节(保持音色与动态连贯)
这种机制显著提升了段落间过渡的自然度,避免“拼接感”。
4. 参数共享与联合优化
草图与精修阶段共享部分模型参数,在统一框架下进行端到端训练:
- 减少模块间误差累积
- 提升生成一致性
- 降低部署复杂度
性能表现:媲美商业级水准
SongBloom 在多个主客观指标上进行了全面评估,结果表明其综合性能处于领先水平。
客观指标对比(vs. 开源基线 & Suno-v4.5)
| 指标 | 含义 | SongBloom 表现 |
|---|---|---|
| PER(Phoneme Error Rate) | 歌词发音准确率 | 显著优于基线 |
| MCC(MuLan Cycle Consistency) | 音频-语义一致性 | 接近 Suno-v4.5 |
| FAD(Fréchet Audio Distance) | 音质与真实度 | 优于多数开源模型 |
| SER(Structural Error Rate) | 结构合理性 | 明显降低 |
💡 在结构连贯性与语义对齐方面,SongBloom 显著优于传统自回归模型。
主观听力测试(MOS)
通过 Mean Opinion Score(MOS)测试,邀请听众对以下维度打分(5分制):
| 维度 | SongBloom | Suno-v4.5 | 基线模型 |
|---|---|---|---|
| 音乐性(MUS) | 4.21 | 4.28 | 3.65 |
| 音质(QLT) | 4.15 | 4.20 | 3.58 |
| 歌词正确性(CRR) | 4.30 | 4.25 | 3.72 |
| 一致性(CST) | 4.18 | 4.22 | 3.60 |
✅ 结果显示:SongBloom 在各项指标上均接近甚至部分超越 Suno-v4.5,显著优于其他开源方案。
为什么 SongBloom 更进一步?
| 维度 | 传统方法局限 | SongBloom 改进 |
|---|---|---|
| 结构连贯性 | 自回归易遗忘早期上下文 | 分块交错 + 全局注意力 |
| 生成质量 | 扩散模型难控语义 | 草图引导,语义先行 |
| 推理效率 | 自回归逐token生成慢 | 扩散阶段并行解码,RTF更低 |
| 多模态对齐 | 歌词与音频脱节 | 双向上下文融合机制 |
⚙️ 实测:在相同硬件条件下,SongBloom 的实时因子(RTF)低于典型自回归模型,更适合实际应用部署。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











