在零样本文本到语音(TTS)领域,基于扩散模型的系统近年来取得了显著进展。然而,大多数方法仍难以实现对整个生成流程的端到端感知质量优化——尤其是时长预测这一关键组件,长期依赖自监督训练,未能与语音生成部分协同优化。
为解决这一问题,哥伦比亚大学与 NewsBreak 联合推出 DMOSpeech 2,这是 DMOSpeech 系列的升级版本,首次将度量驱动的强化学习引入时长预测器训练,构建了一个更完整、更高效的多组件联合优化 TTS 框架。
为什么时长预测如此重要?
在语音合成中,时长预测决定了每个音素或字词的发音持续时间。它直接影响语音的节奏、自然度和可理解性。
传统方法通常将时长预测作为独立模块进行训练,导致其输出无法根据最终语音质量动态调整。例如:
在合成“戴帽子的人”这句话时,若“帽子”部分过短或与“人”粘连,会导致语义模糊,影响听感。
DMOSpeech 2 的核心突破,正是通过强化学习直接优化时长预测器,使其能够以提升整体语音质量为目标进行决策。
核心创新点
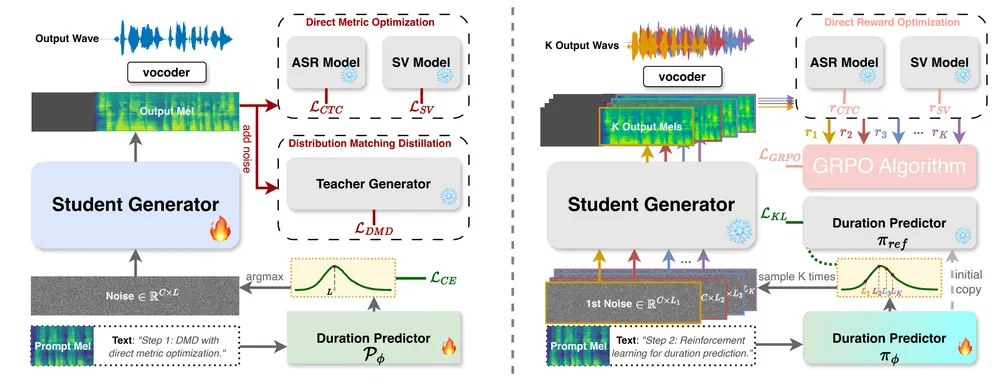
1. 基于强化学习的时长优化框架
DMOSpeech 2 引入了一种新颖的时长策略框架,使用 群体相对偏好优化(Group Relative Policy Optimization, GRPO) 算法,通过以下两个关键指标作为奖励信号:
- 说话者相似度(Speaker Similarity, SIM)
- 词错误率(Word Error Rate, WER)
该框架允许模型在推理过程中采样多种时长配置,评估其对应的语音质量,并反向更新时长预测策略,从而逐步逼近最优解。
这标志着从“分离式训练”向“端到端感知优化”的重要转变。
2. 教师引导采样(Teacher-Guided Sampling)
为了兼顾生成效率与多样性,DMOSpeech 2 提出了 教师引导采样 技术:
- 前 N 步:使用预训练的教师模型进行去噪,快速建立语音的基本韵律结构
- 后续步骤:切换至学生模型(即 DMOSpeech 2 自身),完成细节细化
实验表明,在仅使用 8 步教师引导 + 3 步学生去噪 的设置下,即可生成高质量语音,总采样步数减少一半以上,且未出现质量下降。
更重要的是,该方法有效恢复了音高多样性(CVf0 达 0.5932),接近教师模型水平(0.6659),解决了扩散模型常有的“单调化”问题。
模型架构演进
| 组件 | DMOSpeech (原始) | DMOSpeech 2 |
|---|---|---|
| 时长预测器训练方式 | 自监督,独立训练 | 强化学习(GRPO),联合优化 |
| 优化目标 | 仅语音生成模块 | 全流程端到端优化 |
| 采样策略 | 标准扩散采样 | 教师引导采样 |
| 关键奖励信号 | —— | SIM + WER |
图注:DMOSpeech 2 实现了从“局部优化”到“全局优化”的跨越。
主要功能
- ✅ 精准时长控制:通过强化学习优化时长预测,提升语音自然度与语义清晰度
- ✅ 多目标联合优化:同时优化说话者相似度与识别准确率
- ✅ 高效生成:教师引导采样大幅降低推理延迟
- ✅ 零样本合成能力:仅需短音频参考即可合成新说话人语音
- ✅ 多语言支持:适用于跨语言语音合成任务
工作原理简述
- 时长预测器
基于编码器-解码器 Transformer 架构,接收文本输入,输出音素级持续时间。 - 强化学习训练
- 采样多个不同持续时间方案
- 生成对应语音并提取 SIM 和 WER
- 使用 GRPO 更新策略网络,最大化综合奖励
- 语音生成
- 利用优化后的时长信息生成 Mel 频谱图
- 使用预训练 Vocos 声码器转换为波形
- 教师引导机制
- 初期依赖教师模型稳定去噪方向
- 后期由学生模型完成个性化表达
测试结果:全面超越基线
客观评估(英语测试集)
| 指标 | DMOSpeech 2 | F5-TTS | 提升情况 |
|---|---|---|---|
| WER | 1.752 | 1.947 | ↓ 10% |
| SIM | 0.698 | 0.662 | ↑ 5.4% |
| RTF | 0.032 | 0.167 | ⬇️ 快 5 倍以上 |
| CVf0 | 0.5932 | — | 接近教师模型 |
RTF(Real-Time Factor)越低,生成速度越快。
主观评估(CMOS 分数)
| 项目 | DMOSpeech 2 vs. F5-TTS |
|---|---|
| 自然度(CMOS-N) | -0.43(显著更优) |
| 相似度(CMOS-S) | -0.48(显著更优) |
更令人印象深刻的是,在与真实录音的对比中:
- 自然度方面:与真人无显著差异
- 相似度方面:甚至优于部分真实录音
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











