Soul AI Lab(中国)联合吉利汽车研究院、天津大学及西北工业大学,共同发布了一款高保真、零样本歌声合成模型——SoulX-Singer。这款模型的核心优势的是,无需对未见歌手进行任何微调,就能生成高度逼真的专属歌声,同时支持两种灵活的控制方式,可精准匹配音高、节奏与情感表现力,适配专业音乐制作与各类个性化场景。
- 项目主页:https://soul-ailab.github.io/soulx-singer
- GitHub:https://github.com/Soul-AILab/SoulX-Singer
- 模型:https://huggingface.co/Soul-AILab/SoulX-Singer
- MIDI Editor:https://huggingface.co/spaces/Soul-AILab/SoulX-Singer-Midi-Editor
- SoulX-Singer:https://huggingface.co/spaces/Soul-AILab/SoulX-Singer
具体来说,SoulX-Singer 支持旋律条件(F0 基频轮廓)和乐谱条件(MIDI 音符)双重控制:前者可基于参考音频的旋律,实现翻唱、音色迁移等需求;后者可直接通过 MIDI 乐谱输入,实现从零开始的歌曲创作,彻底打破传统歌声合成的场景局限。
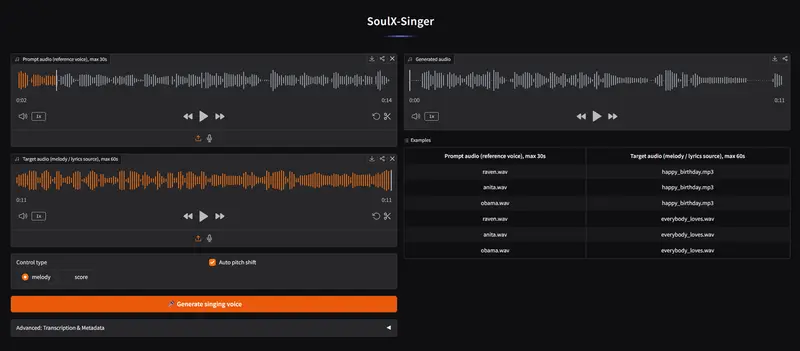
模型核心特性(快速读懂优势)
SoulX-Singer 作为面向工业部署的高质量开源歌声合成系统,核心围绕“零样本生成”展开,同时兼顾实用性与泛化能力,关键特性如下:
- 零样本歌唱:无需对新歌手进行任何微调,仅需少量参考音频,就能生成该歌手的高保真歌声,解决传统模型“只能合成训练过的歌手”的痛点。
- 灵活的控制模式:同时支持旋律(F0 基频轮廓)和乐谱(MIDI 音符)控制,既能满足翻唱、音色迁移的需求,也能支持从零开始的原创歌曲生成,适配不同使用场景。
- 大规模数据集支撑:依托 42,000+ 小时的对齐人声、歌词、音符数据训练,涵盖普通话、英语、粤语三种语言,数据规模比现有同类研究高 10-100 倍,为高泛化能力奠定基础。
- 高保真音色克隆:实现跨语言、跨风格、跨编辑歌词的音色保留,无论修改歌词、切换语言还是调整曲风,都能精准还原目标歌手的音色特征。
- 便捷的歌声编辑:可在不改变原有旋律、音色的前提下,自由修改歌词,同时保持歌声的自然韵律,无需重新生成整体音频。
- 高效跨语言合成:通过技术创新将音色与内容解耦,即便目标语言与参考音频语言不同,也能生成高保真、发音标准的歌声,避免语言泄漏问题。
行业痛点与 SoulX-Singer 的解决方案
在实际音乐制作、内容创作过程中,传统歌声合成模型始终存在诸多局限,尤其对于专业从业者而言,这些痛点严重影响工作效率与创作自由度。我们结合音乐制作人的实际需求,对比现有方法与 SoulX-Singer 的解决方案,让优势更直观:
现有方法的核心局限
- 早期方法(如 DiffSinger):局限性极强,只能合成训练过程中见过的歌手音色,无法实现新歌手的音色克隆,无法满足个性化创作需求。
- 近期零样本方法(如 StyleSinger、TCSinger):虽支持零样本生成,但训练数据仅为数百小时,数据量不足导致泛化能力有限,音色还原度不高,合成歌声容易出现“机械感”“走音”等问题。
- 大规模方法(如 Vevo2、YingMusic-Singer):训练数据提升至数千小时,音色保真度有所提升,但仅支持旋律驱动,无法直接从 MIDI 乐谱生成歌声,带来两大核心问题:一是只能基于现有歌曲提取旋律,无法实现从零创作;二是缺乏明确的音符时长控制,合成歌声与伴奏容易出现时间错位,无法直接用于混音制作。
SoulX-Singer 的针对性解决方案
- 双模式控制突破场景局限:同时支持 MIDI 乐谱输入和旋律输入,既可以通过 MIDI 乐谱实现从零创作,也能通过旋律提取实现翻唱、音色迁移,完美适配专业创作与个性化需求。
- 超大规模数据提升泛化能力:42,000+ 小时的训练数据,涵盖三种语言,数据规模比现有同类研究高一个数量级,大幅提升模型的鲁棒性和泛化能力,即便面对完全未见的歌手,也能生成高保真歌声。
- 工业级质量达标专业需求:在音准精度、发音清晰度、音色相似度三个核心维度均达到行业领先水平(SOTA),合成歌声可直接用于专业音乐制作、影视配乐等工业级场景,无需额外后期调整。
模型主要功能详解(附适用场景)
SoulX-Singer 的所有功能均围绕“实用化、专业化”设计,覆盖从原创、翻唱到编辑、评估的全流程,具体功能模块及适用场景如下表所示,清晰易懂:
| 功能模块 | 详细说明 | 适用场景 |
|---|---|---|
| 乐谱控制生成(Score-control) | 输入 MIDI 乐谱 + 歌词,直接生成对应歌声,可精确控制音符时长、音高 | 原创歌曲创作、精确控制旋律的专业制作 |
| 旋律控制生成(Melody-control) | 输入参考音频的 F0 旋律 + 歌词,实现音色迁移、翻唱 | 歌手翻唱、个性化音色演绎、老歌改编 |
| 零样本音色克隆 | 仅需 3-10 秒参考音频,即可克隆任意歌手的音色,保留核心音色特征 | 个性化创作、虚拟歌手定制、音色复刻 |
| 歌词编辑 | 保持原有旋律、音色不变,自由修改歌词,维持歌声自然韵律 | 歌词修改、多版本歌词演绎、语言转换(如中文改英文) |
| 多语言支持 | 支持中文普通话、英文、粤语三种语言,发音标准,无语言泄漏 | 多语言翻唱、跨境内容创作、方言歌曲传播 |
| 歌声质量评估 | 配套 SoulX-Singer-Eval 基准测试集,包含 50 位未见歌手,可精准评估歌声质量 | 专业测试、模型优化、质量校验 |
四、模型核心特点(技术优势拆解)
SoulX-Singer 之所以能实现“零样本高保真”和“工业级部署”,核心源于六大技术特点,兼顾性能与效率,打破传统模型的技术瓶颈:
1. 超大规模数据集(42,000 小时,行业领先)
数据集是模型泛化能力的核心支撑,SoulX-Singer 的训练数据规模达到 42,000+ 小时,具体分布为:中文约 20,000 小时、英文约 20,000 小时、粤语约 2,000 小时。相较于现有同类研究(通常仅数百至数千小时),数据规模提升 10-100 倍,可覆盖更多歌手音色、曲风、语言场景,大幅提升模型的鲁棒性和泛化能力。
2. 完整的自动化数据处理流水线
为确保训练数据的高质量,SoulX-Singer 搭建了从原始歌曲到训练数据的端到端自动化处理流水线,无需人工干预,大幅提升数据处理效率和一致性,具体流程如下:
- 人声分离:采用 Mel-Band Roformer 技术,精准提取主唱声音,去除和声、伴奏等干扰因素;
- 去混响处理:消除录音室混响、环境噪声,获得干净的干声音频,提升音色还原度;
- 歌词转写:结合 SenseVoice 语言识别、Paraformer/Parakeet ASR 技术,精准转写三种语言的歌词,确保歌词与音频对齐;
- 音符转录:通过 ROSVOT 模型,生成音符级 MIDI 标注,精准对应音高、时长、歌词,为乐谱控制模式奠定基础。
3. 双模式统一架构(灵活切换,兼顾效率)
SoulX-Singer 创新采用双模式统一架构,旋律控制与乐谱控制共享同一模型,通过门控机制(gating mechanism)实现灵活切换,无需单独训练两个模型,既节省资源,又提升使用便捷性。两种模式的核心区别如下表:
| 模式类型 | 输入内容 | 核心优势 | 适用场景 |
|---|---|---|---|
| Score-control(乐谱控制) | MIDI 音符 + 歌词 | 精确控制音符时长、音高,无旋律依赖 | 原创歌曲、专业音乐制作 |
| Melody-control(旋律控制) | F0 旋律曲线 + 歌词 | 保留原唱细腻技巧,适配翻唱需求 | 翻唱、音色迁移、老歌改编 |
在训练阶段,模型会随机 dropout 音高或 F0 信息,强制模型从单一模态学习,提升单模式的稳定性;在推理阶段,会根据用户输入类型,自动启用对应门控,实现两种模式的无缝切换。
4. 非自回归流匹配(Flow Matching)架构
SoulX-Singer 采用基于 Diffusion Transformer(DiT)解码器的非自回归流匹配架构,相较于传统模型,具备两大核心优势:一是生成速度更快,无需逐帧生成,可高效处理长音频;二是推理效率更高,支持单步/少步推理,兼顾速度与质量,完全满足工业级实时生成需求。
5. 两阶段训练策略(兼顾鲁棒性与长程依赖)
为进一步提升模型性能,SoulX-Singer 采用两阶段训练策略,分步骤优化模型的鲁棒性和长音频处理能力:
- 阶段1:针对 2-16 秒的短音频训练,prompt 从非相邻段采样,重点增强模型的鲁棒性,避免对特定片段的依赖;
- 阶段2:针对 30-90 秒的长音频训练,prompt 从相邻段采样,重点让模型学习长程依赖,确保长音频合成的连贯性和一致性。
6. 严格的零样本评估基准(确保结果可信)
为验证模型的零样本泛化能力,SoulX-Singer 搭建了严格的 SoulX-Singer-Eval 零样本评估基准,包含 50 位完全未见的歌手(25 位中文、25 位英文),所有评估数据均经过手动精细标注音符级旋律,确保训练数据与测试数据严格分离,避免数据泄漏,让评估结果更具可信度和参考价值。
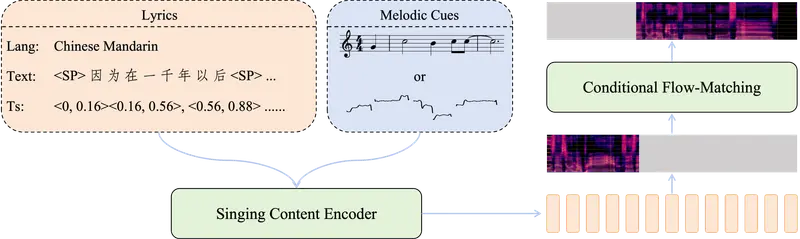
模型工作原理(通俗拆解)
SoulX-Singer 的工作原理可分为四大核心环节,从输入到输出形成完整流水线,兼顾专业性与易懂性,具体流程如下(无需专业背景也能看懂):
1. 整体架构流程
输入:
├── 乐谱控制模式:MIDI(音高序列 + 音符时长)+ 歌词
└── 旋律控制模式:F0 曲线(从参考音频提取)+ 歌词
↓
Singing Content Encoder(歌声内容编码器)
├── 文本编码:将歌词转换为拼音/音素嵌入,让模型识别发音
├── 音高编码:将 MIDI 音高转换为离散嵌入,精准控制音高
├── F0 编码:将参考音频的 F0 曲线转换为连续嵌入(带门控)
└── 长度规整器(Length Regulator):按音符时长扩展特征,实现音词对齐
↓
条件向量(与目标 mel-spectrogram 长度对齐,整合所有输入信息)
↓
Conditional Flow-Matching Decoder(条件流匹配解码器)
├── Diffusion Transformer(DiT)主干:核心计算模块,生成 mel 频谱
└── 预测 mel-spectrogram(音频频谱,为后续生成波形做准备)
↓
Neural Vocoder(神经声码器)→ 输出最终可播放的歌声波形
2. 关键技术细节(重点拆解)
- 文本表示:针对不同语言做针对性优化——中文/粤语采用字符级拼音 + 语言标签(如 zh- 代表中文、yue- 代表粤语),确保发音精准;英文采用音素 + 词边界标记(/),避免发音混淆。
- 旋律表示:同时支持离散和连续两种旋律表示——离散为 MIDI 音高(0-127 范围),适配乐谱控制;连续为 F0 曲线(对数频率),适配旋律控制;通过 g_pitch 和 g_f0 两个门控,控制两种模态的贡献,实现无缝切换。
- 长度规整器(Length Regulator):核心作用是“音词对齐”,将音符级的特征按时长扩展到帧级(与后续生成的 mel 频谱时间分辨率一致),确保歌词发音与音符时长精准匹配,避免出现“唱快”“唱慢”“音词错位”的问题。
- 流匹配训练目标:采用专业的流匹配损失函数,确保生成的歌声与目标音色、旋律高度一致,损失函数公式如下(无需深究公式,了解核心作用即可):
测试结果(用数据证明优势)
为验证 SoulX-Singer 的性能,团队分别在开源基准、零样本基准、跨语言场景、歌声编辑场景中进行了全面测试,对比当前行业主流模型,所有数据均证明 SoulX-Singer 达到行业领先水平(SOTA),以下是核心测试结果拆解:
1. GMO-SVS 开源基准测试(表1)
GMO-SVS 是行业常用的开源歌声合成基准测试集,可全面评估模型的音准、发音、音色等核心指标,测试结果如下(↓表示数值越低越好,↑表示数值越高越好):
| 模型 | 控制模式 | 中文 WER↓ | 中文 SIM↑ | 中文 FFE↓ | 中文 SingMOS↑ | 英文 WER↓ | 英文 SIM↑ | 英文 FFE↓ | 英文 SingMOS↑ |
|---|---|---|---|---|---|---|---|---|---|
| StyleSinger | Score | 0.367 | 0.817 | 0.363 | 3.938 | - | - | - | - |
| TCSinger | Score | 0.270 | 0.855 | 0.315 | 3.977 | 0.410 | 0.879 | 0.211 | 3.662 |
| YingMusic-Singer | Melody | 0.099 | 0.902 | 0.132 | 4.145 | - | - | - | - |
| Vevosing | Melody | 0.233 | 0.899 | 0.112 | 4.355 | 0.239 | 0.922 | 0.088 | 4.321 |
| SoulX-Singer | Melody | 0.065 | 0.897 | 0.044 | 4.458 | 0.151 | 0.918 | 0.036 | 4.323 |
| SoulX-Singer | Score | 0.069 | 0.905 | 0.122 | 4.445 | 0.149 | 0.926 | 0.164 | 4.303 |
关键结论:
- 旋律模式下,SoulX-Singer 的 FFE(音准误差)显著低于其他模型(中文 0.044 vs Vevosing 0.112),证明 F0 条件控制能有效提升音准精度;
- 乐谱模式下,SoulX-Singer 的 WER(词错误率)最低(中文 0.069),说明 MIDI 输入能大幅提升发音清晰度;
- 音色相似度(SIM)和歌唱质量(SingMOS)均达到行业领先,证明模型的高保真特性。
2. 歌声编辑场景测试(修改歌词,表1下半部分)
歌声编辑是实际使用中的高频需求,测试核心是“修改歌词后,歌声的自然度和发音精度是否受影响”,结果如下:
| 模型 | 中文 WER | 英文 WER |
|---|---|---|
| YingMusic-Singer | 0.146 | - |
| Vevosing | 0.308 | 0.484 |
| SoulX-Singer (Melody) | 0.212 | 0.444 |
| SoulX-Singer (Score) | 0.089 | 0.213 |
关键发现:
- 传统旋律驱动方法(如 Vevosing)在修改歌词后,WER 显著上升(从 0.233 升至 0.308),核心原因是原旋律与原歌词强相关,修改歌词后容易出现音词错位;
- SoulX-Singer 的乐谱驱动方法几乎不受影响(WER 从 0.069 升至 0.089),证明 MIDI 输入的鲁棒性更强,更适合歌词编辑场景。
3. SoulX-Singer-Eval 零样本基准测试(表2)
该测试针对“完全未见歌手”展开,核心验证模型的零样本泛化能力,结果如下:
| 模型 | 控制模式 | 中文 WER↓ | 中文 SIM↑ | 中文 SingMOS↑ | 英文 WER↓ | 英文 SIM↑ | 英文 SingMOS↑ |
|---|---|---|---|---|---|---|---|
| StyleSinger | Score | 0.388 | 0.808 | 3.892 | - | - | - |
| TCSinger | Score | 0.227 | 0.822 | 3.939 | 0.460 | 0.729 | 3.652 |
| YingMusic-Singer | Melody | 0.117 | 0.913 | 4.068 | - | - | - |
| Vevosing | Melody | 0.233 | 0.908 | 4.265 | 0.256 | 0.888 | 4.184 |
| SoulX-Singer | Melody | 0.069 | 0.902 | 4.394 | 0.155 | 0.870 | 4.223 |
| SoulX-Singer | Score | 0.069 | 0.922 | 4.370 | 0.129 | 0.914 | 4.255 |
关键结论:
- 即便面对完全未见的歌手,SoulX-Singer 仍保持行业领先水平,未出现性能大幅下降的情况;
- 乐谱模式的音色相似度(SIM)最高(中文 0.922,英文 0.914),证明 MIDI 控制能更好地保留歌手音色特征;
- 大规模数据训练的优势凸显,让模型具备极强的泛化能力,无需微调即可适配新歌手。
4. 跨语言合成测试(表3)
跨语言合成的核心难点是“保留目标音色的同时,确保发音标准,避免语言泄漏”,测试结果如下:
| 模型 | 控制模式 | WER↓ | SIM↑ | SingMOS↑ |
|---|---|---|---|---|
| TCSinger | Score | 0.333 | 0.789 | 3.817 |
| Vevosing | Melody | 0.717 | 0.877 | 4.133 |
| SoulX-Singer | Melody | 0.122 | 0.866 | 4.342 |
| SoulX-Singer | Score | 0.110 | 0.898 | 4.337 |
关键发现:
- 传统模型(如 Vevosing)在跨语言合成时,WER 高达 0.717,出现严重的语言泄漏问题——参考音频的语言模式会污染输出歌声,导致发音不标准;
- SoulX-Singer 凭借“音色与内容解耦”的技术优势,保持低 WER(最低 0.110)和高 SIM(最高 0.898),既保留目标音色,又确保发音标准,完美解决跨语言合成的核心痛点。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











