LMMs-Lab 推出了一款紧凑型音频模型 Aero-1-Audio,专为多种音频任务设计,包括语音识别(ASR)、音频理解和音频指令跟随。作为 Aero-1 系列的第一代产品,Aero-1-Audio 展现了在性能和参数效率之间的出色平衡,并计划未来扩展到更多模态。
- GitHub:https://github.com/EvolvingLMMs-Lab/Aero-1
- 模型:https://huggingface.co/lmms-lab/Aero-1-Audio
- Demo:https://huggingface.co/spaces/lmms-lab/Aero-1-Audio-Demo
核心亮点:轻量高效,性能卓越
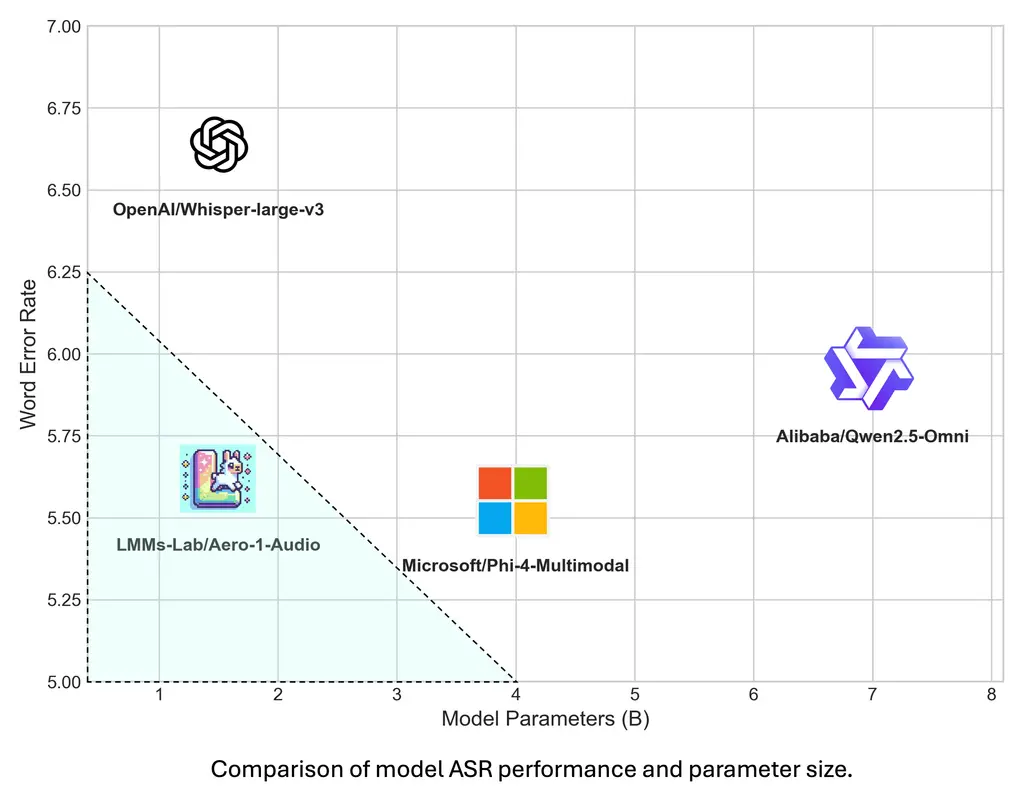
Aero-1-Audio 基于 Qwen-2.5-1.5B 语言模型构建,尽管参数规模较小,但在多个音频基准测试中表现出色,甚至超越了许多更大规模的先进模型和商业服务(如 Whisper、Qwen-2-Audio 和 ElevenLabs/Scribe)。
训练效率:仅用5万小时数据
Aero-1-Audio 的训练数据集包含约 50亿个 tokens,相当于 5万小时音频,远小于 Qwen-Omni 和 Phi-4 等模型的数据需求(小100倍以上)。通过使用高质量的过滤数据,Aero-1-Audio 实现了样本高效性,仅需 16个H100 GPU 即可在一天内完成训练。
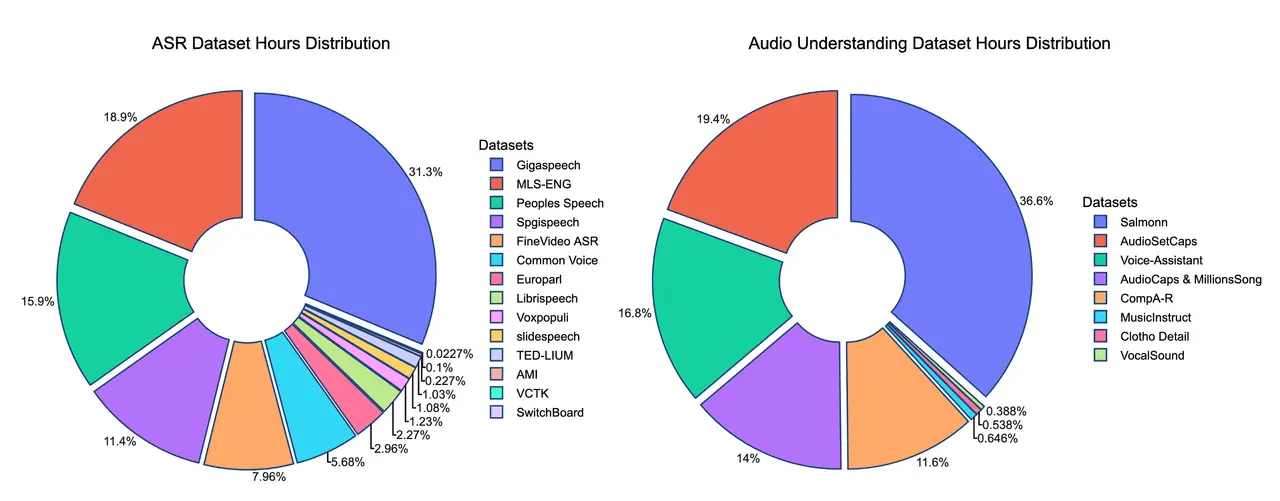
长语音处理能力
与其他模型相比,Aero-1-Audio 在处理长达 15分钟连续音频输入 的任务中表现尤为突出。当前大多数模型对长语音 ASR 的处理方式是将音频分割成小块后逐段处理,但这种方式容易导致上下文丢失和性能下降。Aero-1-Audio 则能够连续处理长音频序列,展示了强大的长上下文理解能力。
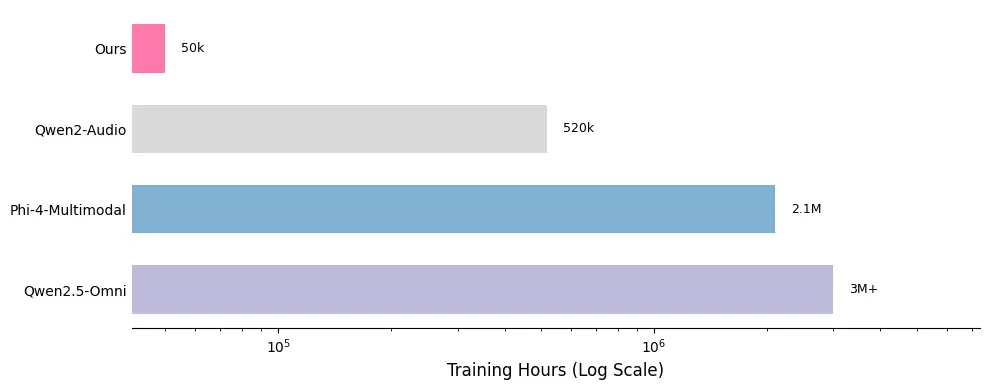
性能评估:全面领先
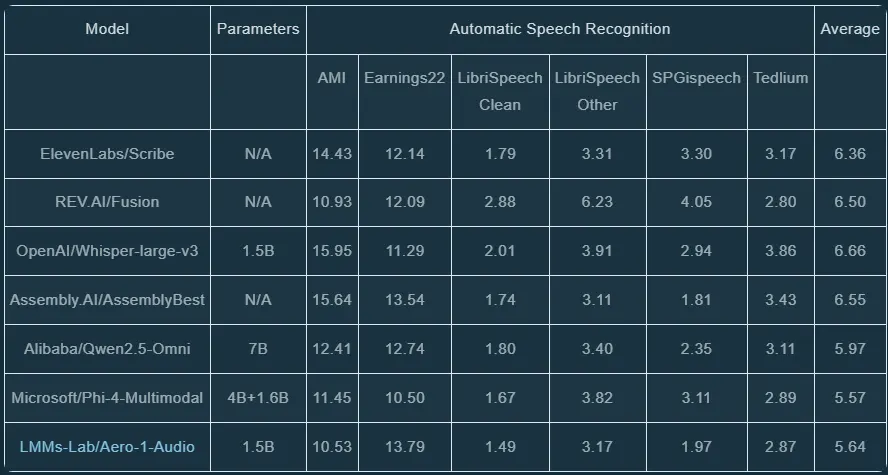
语音识别(ASR)任务
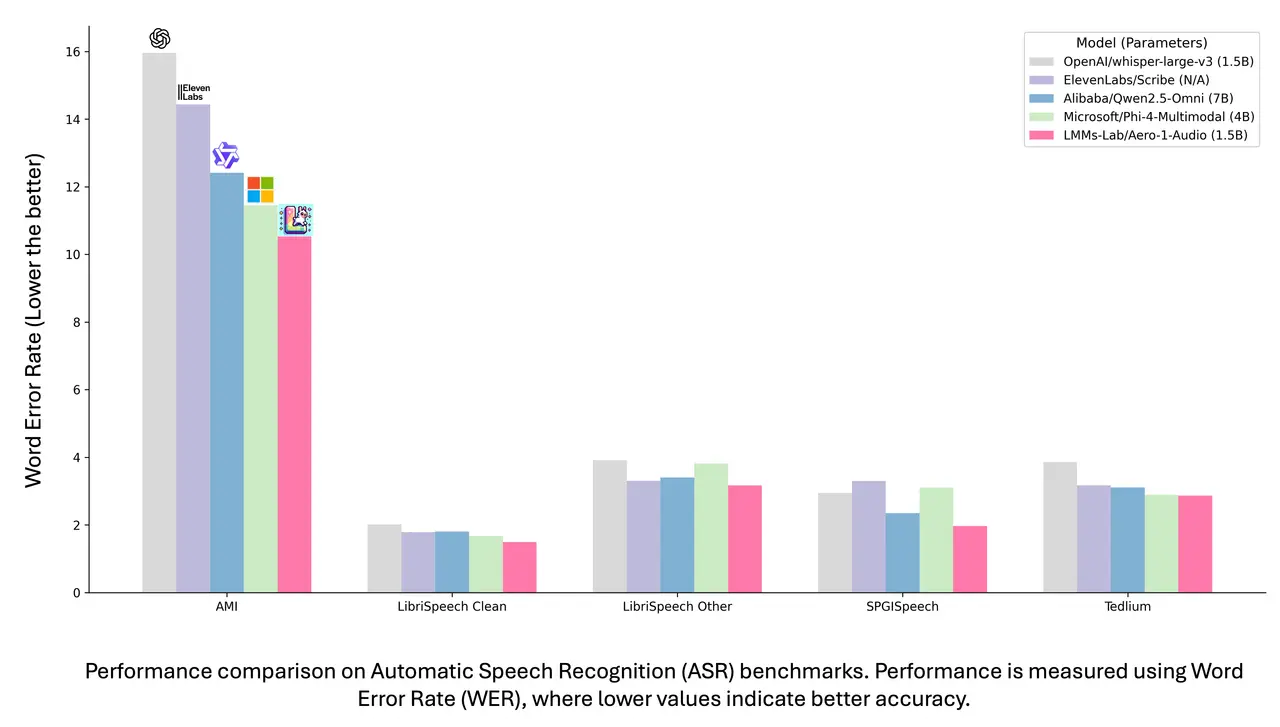
Aero-1-Audio 在多个 ASR 数据集上取得了优异成绩:
AMI、LibriSpeech 和 SPGISpeech 数据集上的词错误率(WER)最低。 在长语音 ASR 测试中,Aero-1-Audio 的性能下降幅度最小,展现出对长音频输入的强大适应性。
音频理解任务
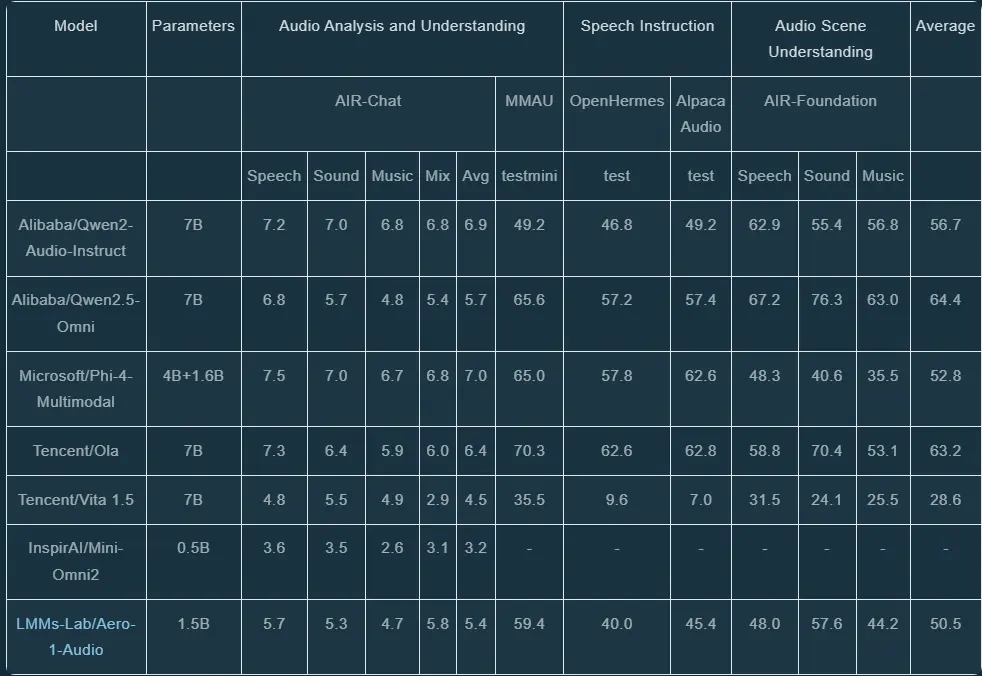
从三个维度评估 Aero-1-Audio 的音频理解能力:
音频分析与理解
在 AIR-Bench-Chat 和 MMAU 基准测试中,Aero-1-Audio 平均得分为 5.35,优于 Mini-Omni2 和 Vita。语音指令跟随
在 OpenHermes 和 Alpaca-Audio 上进行的 AudioBench 测试中,Aero-1-Audio 表现出强大的指令理解和响应能力。音频场景理解
在 AIR-Bench-Foundation 上的测试显示,Aero-1-Audio 在声音和音乐维度上优于 Phi-4-Multimodal,展现了对复杂音频场景的理解能力。

技术优势:训练方法优化
动态批大小
Aero-1-Audio 使用了一种基于 token 长度的动态批处理策略。传统固定批大小方法常因内存不足(OOM)问题而限制效率,而动态批处理通过将样本分组到预定义 token 长度阈值内,显著提高了计算资源利用率。
序列打包
为了进一步优化动态批处理,Aero-1-Audio 对音频编码器和语言模型实现了 序列打包 技术,并结合 Liger 内核融合,显著提升了吞吐量并降低了内存使用率。启用序列打包后,平均模型 FLOP 利用率(MFU)从 0.03 提升至 0.34,训练效率大幅提高。
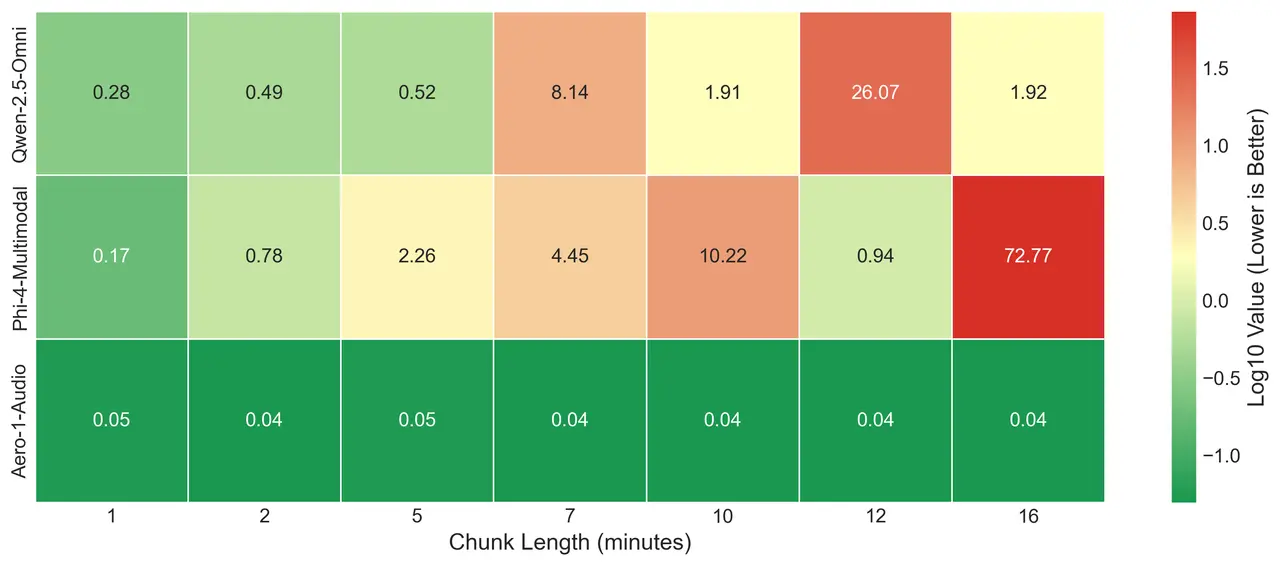
关键洞察:长语音ASR的重要性
随着大型语言模型(LLM)的发展,长上下文理解成为关键挑战之一。LMMs-Lab 强调,模型连续处理长音频序列的能力对于有效的音频理解至关重要。为此,Aero-1-Audio 在 NVIDIA 会议音频数据上进行了长语音 ASR 测试,并与 YouTube 自动生成字幕对比,结果显示其性能稳定且具有竞争力。
下图展示了不同模型在不同音频长度上的 ASR 性能热力图比较:
Qwen-Omni 和 Phi-4 在不同长度上表现出不稳定性,输出结果波动较大。 Aero-1-Audio 则在各种长度下保持稳定性能,尤其在长音频任务中表现优异。
未来展望
Aero-1-Audio 是 LMMs-Lab 在轻量级多模态模型领域的一次重要尝试。通过高效的训练方法和强大的性能表现,Aero-1-Audio 不仅为语音识别和音频理解提供了新的解决方案,也为未来多模态任务的扩展奠定了基础。
随着模型的持续优化和应用场景的拓展,Aero-1-Audio 或将在教育、医疗、娱乐等多个领域发挥重要作用。例如:
教育:自动生成讲座笔记和课堂内容摘要。 医疗:辅助医生记录患者病历或分析医疗对话。 娱乐:实时生成视频字幕或分析音效。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











