英伟达推出的 Parakeet-TDT-0.6B-v2 是一款拥有 6 亿参数的自动语音识别(ASR)模型,专为高质量英语语音转录设计。该模型支持标点符号、大写和精准的时间戳预测,能够处理长达 24 分钟的音频片段,并在 HF-Open-ASR 排行榜上表现出色(RTFx=3380)。它基于 FastConformer-TDT 架构,结合了强大的解码器和全注意力训练方法,适用于多种语音转文本的应用场景。
- 模型:https://huggingface.co/nvidia/parakeet-tdt-0.6b-v2
- Demo:https://huggingface.co/spaces/nvidia/parakeet-tdt-0.6b-v2
关键特性
精准的单词级时间戳预测 提供每个单词对应的时间戳,便于生成字幕或对齐语音与文本。
自动标点和大写 转录结果包含自然语言中的标点符号和大小写,无需额外后处理。
强大的性能 在口述数字、歌词转录等复杂场景中表现优异。 对噪声和电话音频具有鲁棒性。
高效的长音频处理 支持一次性转录长达 24 分钟的音频片段,适合会议记录、讲座转录等场景。
高性能推理 在 NVIDIA GPU 加速系统上运行时,能够实现更快的推理速度(RTFx=3380)。
模型架构
输入
格式:单声道音频文件(.wav 或 .flac) 采样率:16kHz 输入参数:一维音频信号
输出
格式:字符串 内容:包含标点符号和大写的文本 附加功能:提供单词级时间戳
架构细节
编码器:基于 FastConformer [1] 的 XL 变体 解码器:集成了 TDT 解码器 [2] 参数规模:6 亿参数 训练方式:全注意力机制,支持长音频片段的一次性转录
训练与评估数据集
训练数据集
模型在 Granary 数据集 上训练,包含约 12 万小时的英语语音数据:
人工转录音频(1 万小时): LibriSpeech(960 小时) Fisher Corpus National Speech Corpus Part 1 VCTK VoxPopuli(英语) Europarl-ASR(英语) MLS 英语(2000 小时子集) Mozilla Common Voice(v7.0) AMI
伪标注数据(11 万小时): YTC(YouTube-Commons)数据集 YODAS 数据集 Librilight
所有转录均保留标点符号和大写,确保输出的自然语言质量。
评估数据集
使用 Huggingface Open ASR Leaderboard 数据集 进行性能评估,涵盖多种基准测试场景。
性能指标
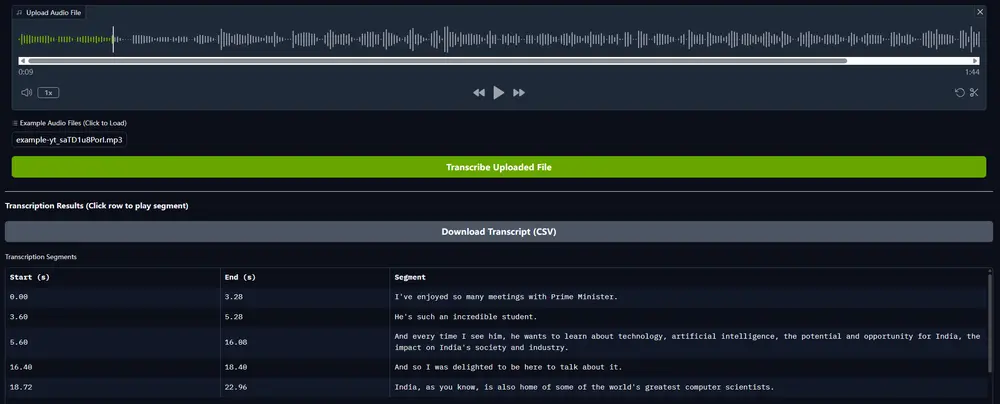
词错误率(WER)
模型在跨多个领域的大型多样化数据集上训练,因此在不同类型的音频中表现出更强的鲁棒性和准确性。以下为部分基准测试结果:
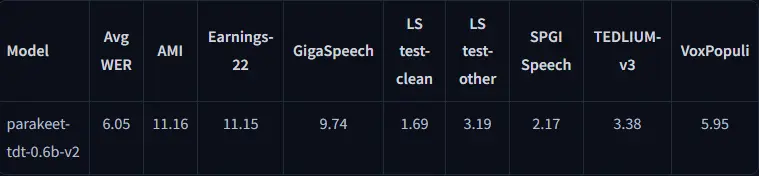
抗噪性能
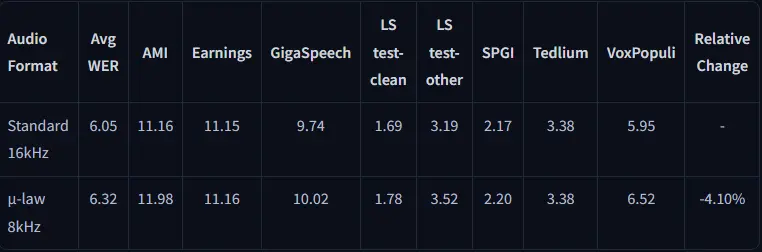
模型在不同信噪比(SNR)下的表现稳定,尤其是在背景音乐和噪声干扰的情况下仍能保持较高的转录准确率。
电话音频性能
通过模拟电话音频(μ-law 编码,16kHz→8kHz→16kHz 转换),模型在低质量音频中依然表现出色。
软件集成与硬件要求
运行时引擎
NeMo 2.2
支持的硬件
微架构兼容性: NVIDIA Ampere NVIDIA Blackwell NVIDIA Hopper NVIDIA Volta
操作系统:Linux 内存要求:至少需要 2GB RAM 以加载模型;更大的 RAM 支持更长的音频输入。
优化
利用 NVIDIA GPU 和 CUDA 库加速,相比仅使用 CPU 的解决方案,训练和推理速度显著提升。
使用场景
Parakeet-TDT-0.6B-v2 适用于广泛的语音转文本应用,包括但不限于:
对话式 AI:为智能助手提供高质量语音转录能力。 转录服务:快速生成会议记录、讲座笔记或采访内容。 字幕生成:自动生成视频字幕,支持精准时间戳。 语音分析平台:用于情感分析、关键词提取等任务。 文化遗产保护:转录音频档案,保存历史资料。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











