阿里通义实验室语音团队今日正式宣布,推出两款支持 FreeStyle 指令生成 的突破性模型:Fun-CosyVoice3.5 与 Fun-AudioGen-VD。
- 官方文档:https://help.aliyun.com/zh/model-studio/text-to-speech?spm=a2c4g.11186623.help-menu-2400256.d_0_3_2_0.d5536a31V2tEJP
这两款模型标志着 AI 音频生成从“固定参数调节”迈向了“自然语言自由控制”的新阶段。用户无需调整复杂的滑块或标签,只需通过一句自然的语言指令,即可精细控制声音的表达方式,甚至从零设计全新的音色与沉浸式听觉场景。

Fun-CosyVoice3.5:多语种复刻与精细化表达控制
作为 Instruct-TTS 方向的升级版,Fun-CosyVoice3.5 核心在于让语音生成像对话一样自然。它支持 FreeStyle 指令控制,用户可以直接用自然语言描述想要的声音效果。
核心亮点
- 一句话自由生成:
- 用户只需输入:“语气坚定一点”、“稍微压低音调,语速慢一点”或“带一点情绪起伏”,模型即可精准理解并生成符合描述的语音。
- 彻底告别繁琐的参数面板,让声音调控变得直观简单。
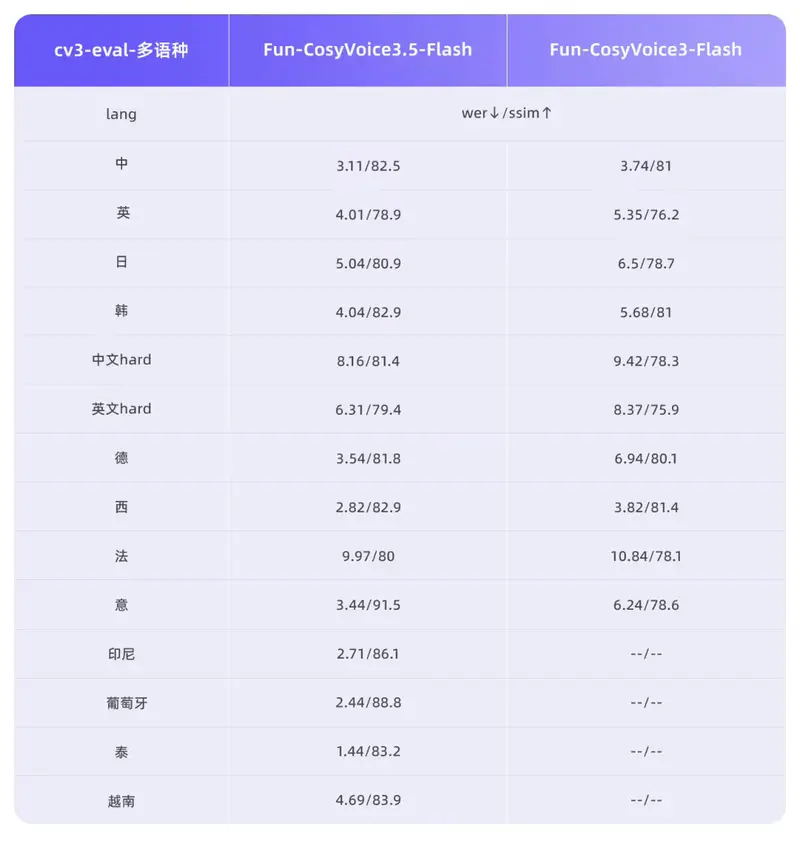
- 多语种能力扩容:
- 新增支持 泰语、印尼语、葡萄牙语、越南语。
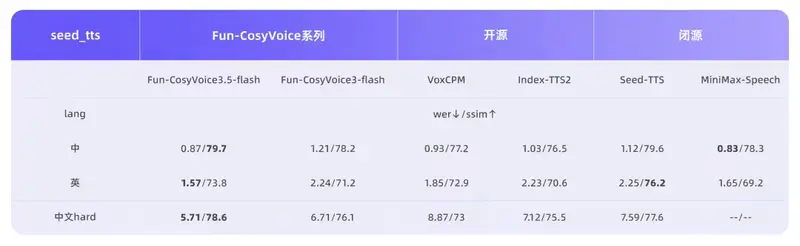
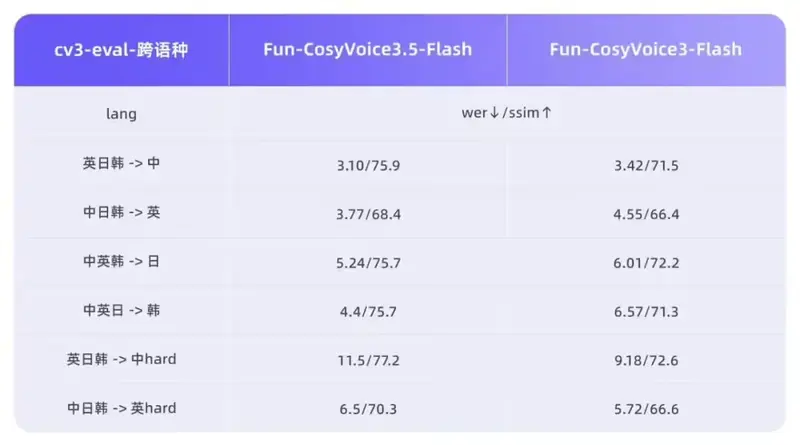
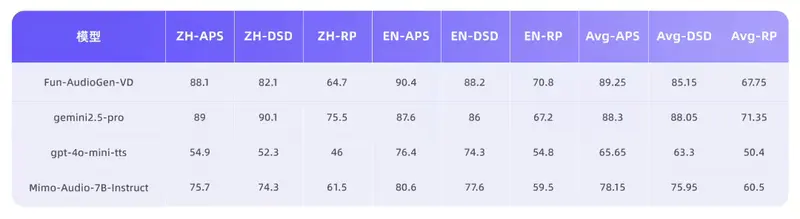
- 在包括中文、英语在内的 13 种语言 中,其字错率(WER)和说话人相似度(SpkSim)等客观指标均保持 业内领先。
- 稳定性大幅提升:
- 针对生僻字和复杂语句进行了专项优化,生僻字读错率从 15.2% 骤降至 5.3%。
- 长文本朗读更加流畅稳定,不再出现断句错误或语调怪异的情况。
- 听感与性能双重升级:
- 利用 强化学习技术 进行专项调优,使语音听感更自然,情感表达更有层次。
- Tokenizer 帧率减半,首包延迟降低 35%,在实时交互场景(如数字人对话、实时翻译)中响应更快,体验更丝滑。
Fun-AudioGen-VD:声音设计与场景化音频生成
如果说 CosyVoice 是完美的“配音演员”,那么 Fun-AudioGen-VD 就是一位全能的“声音导演”。它不仅生成人声,还能构建完整的听觉世界,实现 “人物 + 场景” 的一体化生成。
核心能力
- 全方位角色定制:
- 基础属性:自由定义性别、年龄、口音、音高、语速。
- 音质特征:轻松生成沙哑、清亮、低沉、磁性等特定音色。
- 情绪表达:精准控制愤怒、悲伤、兴奋、坚定等情绪,甚至支持 复杂心理状态(如“表面镇定但内心颤抖”)。
- 角色模拟:一键扮演客服、老兵、孩童、AI 助手、播音员等各类角色。
- 沉浸式场景构建:
- 背景环境音:自动叠加城市喧嚣、咖啡馆嘈杂、战场轰鸣等环境音效,让人声不再“干瘪”。
- 空间混响效果:模拟大教堂的空灵、金属牢房的压抑、水下的沉闷等真实空间回声。
- 设备听感滤镜:还原老式广播的电流声、对讲机的窄带质感、呼吸面罩的闷响等特殊音质。
- 动态环境互动:支持风噪断续、回声随位置变化、嘶哑效果随情绪波动等实时动态互动,打造电影级的听觉体验。
应用场景与未来展望
这两款模型的发布,将极大降低高质量音频内容的创作门槛:
- 有声书与广播剧:作者可直接通过指令调整角色情绪和场景氛围,无需专业录音棚。
- 游戏与影视制作:快速生成带有特定环境音和角色状态的测试音频,加速前期制作流程。
- 智能客服与虚拟人:更低延迟、更自然的情感表达,让机器交互更具温度。
- 多语种内容本地化:轻松将内容转换为多种语言,并保持原有的情感色彩和表达风格。
阿里通义实验室此次推出的 Fun-CosyVoice3.5 与 Fun-AudioGen-VD,不仅展示了其在语音合成与音频生成领域的深厚积累,更通过 FreeStyle 指令生成 这一创新交互方式,让每个人都能成为自己声音世界的导演。未来,随着模型的进一步迭代,我们有理由期待一个更加多元、生动且充满创意的音频生态。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











