
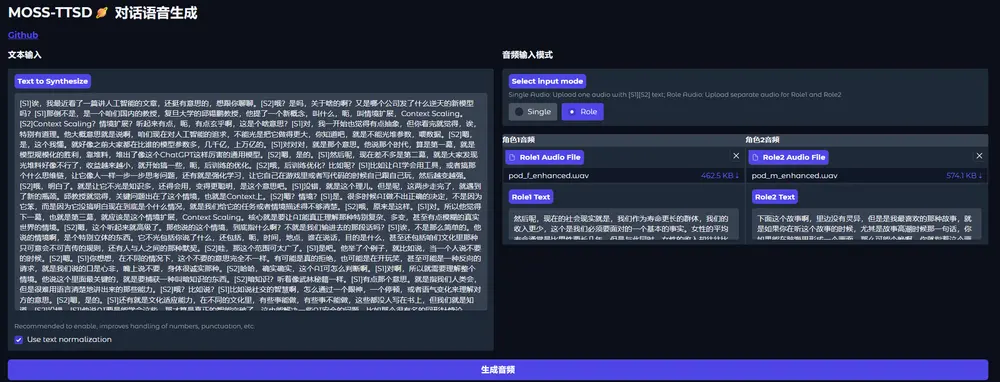
复旦大学 OpenMOSS 团队正式发布了全新语音生成模型 MOSS-TTSD(Text to Spoken Dialogue),这是目前首个能够直接从对话文本生成自然、富有表现力对话语音的大规模模型。
- 项目主页:https://www.open-moss.com/cn/moss-ttsd
- GitHub:https://github.com/OpenMOSS/MOSS-TTSD
- 模型:https://huggingface.co/fnlp/MOSS-TTSD-v0
- Demo:https://huggingface.co/spaces/fnlp/MOSS-TTSD
该模型支持:
- 中英双语高表现力语音合成
- 零样本多说话人音色克隆
- 声音事件控制
- 超长语音生成(最长可达 960 秒)
MOSS-TTSD 的发布,标志着 TTS 技术正从“单句朗读”迈向“真实对话”的新阶段。
为什么需要对话语音生成?
在现实世界中,语音交互最常见于对话场景,如播客、访谈、新闻播报、电商直播等。这些情境下的语音不仅包含语义内容,还带有丰富的韵律、节奏、情感和角色切换特征。
然而,现有 TTS 模型大多专注于单句语音生成,缺乏对上下文语境建模能力,导致在生成对话语音时常常显得生硬、不连贯。

为了解决这一问题,MOSS-TTSD 应运而生 —— 它不仅能理解对话中的角色关系,还能生成符合上下文语气和情绪的语音,实现更自然、更具沉浸感的语音交互体验。
🔍 MOSS-TTSD 的核心功能
| 功能 | 描述 |
|---|---|
| 中英双语支持 | 支持中文与英文的高质量语音合成 |
| 零样本音色克隆 | 仅需一段音频即可克隆说话人声音,无需额外训练 |
| 声音事件控制 | 可控制语音中的停顿、语速、重音等细节 |
| 长语音生成 | 支持一次性生成长达 960 秒的连续语音,避免拼接带来的不自然过渡 |
🏗️ 技术架构与创新点
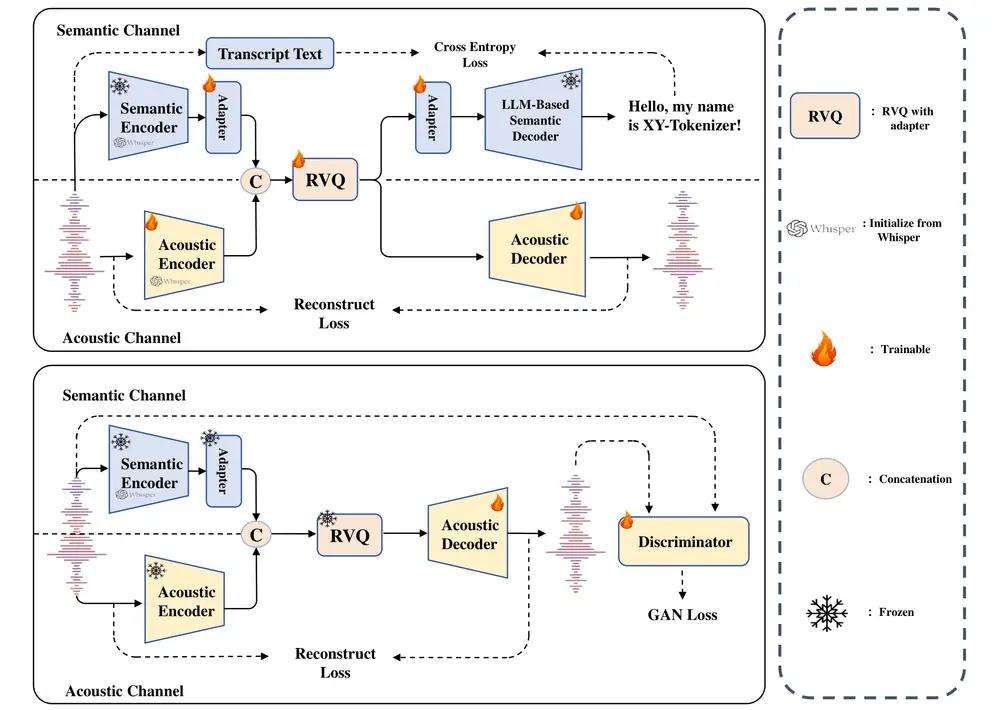
1. XY-Tokenizer:低比特率语音离散化编码器
- 基于 Whisper Encoder 构建,8 层 RVQ 结构
- 实现 1kbps 的比特率与 12.5Hz 的帧率
- 同时编码语义与声学信息,提升 LLM 对语音 token 的建模能力
- 使用 10 万小时带文本语音 + 50 万小时无文本语音进行训练,增强复杂音频处理能力
2. 基于 Qwen3-1.7B 的自回归建模
- 在 XY-Tokenizer 编码基础上,采用自回归加多头 Delay 的方式生成语音 token
- 继续预训练于约 100 万小时单人语音 + 40 万小时对话语音数据
- 支持双人音色建模与自然切换
3. 大规模高质量数据工程
- 利用内部说话人分离模型(优于 pyannoteAI)
- DNSMOS 分数筛选高质量语音片段(≥2.8)
- 自动构建粗粒度对话片段,并结合 Whisper-d 进行细粒度标注
- 最终形成 10 万小时中文 + 27 万小时英文对话数据
- 合成 4 万小时中英文对话用于说话人切换训练
📊 模型训练与评估结果
TTS 预训练阶段
- 使用 110 万小时中英文 TTS 数据
- 性能与 Seed-TTS 相当,具备良好的零样本音色克隆能力
TTSD 后训练阶段
- 引入 WSD Scheduler 训练策略
- 通过人工评估挑选最优检查点
- 支持标点感知与语气建模优化
样本对比测试
- 中文 vs MoonCast:MOSS-TTSD 更自然、稳定、富有表现力
- 中文 vs 豆包播客 TTS:MOSS-TTSD 在保持相同表现力的同时,支持零样本音色克隆和更高文本定制性
🎙️ 实际应用场景展示:AI 播客生成
我们基于 AI 热点新闻生成了多个播客样例,与商业模型豆包进行了对比:
| 维度 | MOSS-TTSD | 豆包播客 TTS |
|---|---|---|
| 情感丰富度 | ✅ 接近真人表达 | ✅ 表达自然 |
| 语气自然度 | ✅ 有抑扬顿挫 | ✅ 整体流畅 |
| 表现力 | ✅ 支持情绪变化 | ✅ 稳定输出 |
| 可定制性 | ✅ 支持文本微调 | ❌ 商业封闭接口 |
| 音色克隆 | ✅ 零样本克隆 | ❌ 不开放 |
结果显示:MOSS-TTSD 已具备与主流商业模型相当的表现力水平,且具备更强的开放性和可定制性。
🚀 未来展望
MOSS-TTSD 是迈向真正“拟人化”语音生成的重要一步。接下来,我们将继续优化以下几个方向:
- 多人对话建模:扩展至三人及以上场景
- 跨语言混合对话:支持中英混说等复杂语境
- 实时语音生成系统:降低延迟,提升部署效率
- 更多可控参数开放:如情绪标签、语速调节等
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











