近日,Kyutai 实验室发布了一款全新的流式语音转文本(Speech-to-Text)模型——Kyutai STT,专为实时语音交互场景设计,在延迟与准确性之间实现了出色平衡,非常适合如语音助手、在线会议系统等需要即时响应的应用。
目前,Kyutai STT 已开源两个版本:
- kyutai/stt-1b-en_fr:支持英语和法语的小型低延迟模型,内置语义语音活动检测器。
- kyutai/stt-2.6b-en:更大的仅英语模型,专注于最高准确率。
这两个模型均已开放使用,开发者可在 GitHub 获取完整实现代码。
- GitHub:https://github.com/kyutai-labs/delayed-streams-modeling
- stt-2.6b-en:https://huggingface.co/kyutai/stt-2.6b-en
- stt-1b-en_fr:https://huggingface.co/kyutai/stt-1b-en_fr
为什么选择 Kyutai STT?
传统语音识别模型通常采用“非流式”方式处理整段音频,虽然准确率高,但延迟较大,不适合实时交互。
而 Kyutai STT 是一个真正的端到端流式模型,能够边接收音频边生成转录结果,非常适合以下应用场景:
- 实时字幕生成
- 虚拟助手对话系统(如 Unmute)
- 多用户语音聊天
- 智能客服平台
它不仅能输出带有标点符号的规范文本,还提供单词级时间戳,便于后续处理与同步。
核心特性解析
✅ 1. 流式处理 + 高准确性
Kyutai STT 的流式架构使其能够在接收到部分音频时就开始转录,而不是等待整段音频上传完成。
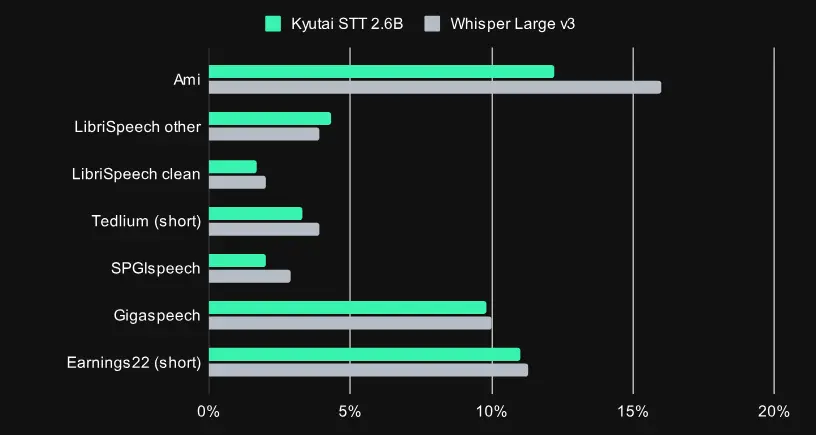
在多个测试中,其准确率接近甚至媲美主流非流式模型(如 Whisper),但在实时性方面具有显著优势。
✅ 2. 内置语义语音活动检测器(Voice Activity Detection)
传统的语音活动检测方法依赖固定阈值或简单规则,容易误判长时间停顿或语速变化。
Kyutai STT 则通过语义层面的判断,动态预测用户是否已经说完话,从而更准确地决定何时结束转录。
这项功能已在 Kyutai 的 Rust 实现中上线,并已用于生产环境(如 Unmute 平台)。
✅ 3. 极低延迟 + 高吞吐量
- kyutai/stt-1b-en_fr 延迟控制在 500ms 内,适合对响应速度要求高的场景;
- kyutai/stt-2.6b-en 延迟稍长(约 2.5s),但准确率更高。
更令人惊喜的是,该模型在单块 H100 GPU 上即可并发处理400个实时语音流,非常适合大规模部署。
相比之下,Whisper 等通用模型若要实现流式能力,往往需要复杂的二次开发,且不支持高效批量处理。
技术创新:延迟流建模(Delayed Streaming Modeling)
Kyutai STT 的核心技术是其独有的 延迟流建模(Delayed Streaming Modeling) 方法,首次在 Moshi 模型中提出。
不同于传统的自回归解码方式,Kyutai STT 将语音和文本视为并行的时间序列流,通过填充机制保证两者在时间上的对齐。
训练过程中,模型学习在听到部分音频后预测对应的文本片段;推理阶段则保持音频流固定,实时输入新数据并持续更新文本输出。
这种方法不仅提升了模型的实时响应能力,也为未来构建双向语音-文本模型(如 TTS)提供了统一框架。
多平台支持:从研究到落地全覆盖
Kyutai 提供了多种实现方式,适配不同使用场景:
| 实现方式 | 使用场景 |
|---|---|
| PyTorch | 适用于研究与实验 |
| Rust | 生产部署首选,Unmute 正在使用 |
| MLX(Apple) | 支持 Mac 和 iPhone 上的本地推理 |
其中,Rust 实现的服务器可通过 WebSocket 接口提供高效的流式服务,在 L40S GPU 上即可实现3倍实时速度运行,同时支持64个并发连接。
实际优化技巧:如何进一步压缩响应延迟?
在 Kyutai 的实际部署中(如 Unmute),他们采用了一个称为“刷新技巧(Flush Trick)”的技术:
当语音活动检测器判断用户已说完话时,STT 模型会以超实时速度(约 4x)处理剩余音频,将原本需等待的 500ms 缩短至 125ms。
这一策略大幅提升了用户体验,尤其在高频语音交互场景中效果显著。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











