实时语音翻译的核心挑战在于如何在翻译质量与系统延迟之间取得最佳平衡。传统方法通常需要大量精细标注的词级对齐数据来指导模型何时开始翻译,这不仅成本高昂,也极大地限制了模型向新语言的扩展能力。
为彻底解决这一问题,Kyutai 实验室发布了 Hibiki-Zero——一个拥有 30 亿参数的同步语音到语音翻译模型。它通过一种创新的训练范式,完全摒弃了对词级对齐数据的依赖,仅使用粗略的句子级对齐,就能实现高质量、低延迟的实时翻译,并原生支持跨语言音色迁移。
架构与核心技术
Hibiki-Zero 基于其前身 Hibiki 的多流 RQ-Transformer 架构,是一个仅解码器模型。它利用流式神经音频编解码器 Mimi,以 12.5 Hz 的恒定帧率,联合建模源音频、目标音频以及一个用于内部推理的“内心独白”文本流。这种设计使其能够持续处理输入语音流,并同步输出连续的翻译音频和带时间戳的文本。
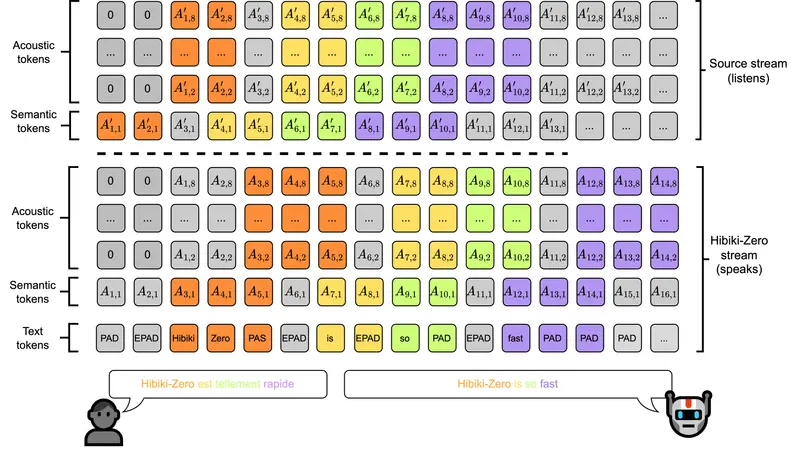
其真正的突破在于训练方法:
- 监督预训练:首先,在由合成数据构建的、仅包含句子级对齐的多语言数据集(法语、西班牙语、葡萄牙语、德语到英语)上进行监督学习,获得一个基础翻译模型。
- GRPO 强化学习优化:随后,引入一种名为 组相对策略优化(Group Relative Policy Optimization, GRPO)的新型强化学习技术。该方法使用基于 BLEU 的过程奖励,自动学习最优的“读写”策略——即在听到多少上下文后开始翻译,从而在保持高翻译质量的同时,显著降低端到端延迟。研究还证明,通过一个简单的超参数,即可灵活调控模型在质量与延迟之间的权衡。
卓越性能与评估结果
Hibiki-Zero 在多项客观和主观评估中均取得了最先进(SOTA)的结果:
- 主观评价(0-100分):
- 法语→英语:音频质量 64.5,说话人相似度 70.0,语音自然度 67.2。
- 西班牙语→英语:音频质量 66.8,说话人相似度 69.0,语音自然度 66.2。
相比基线模型 Seamless 和前代 Hibiki,跨语言说话人相似度提升尤为显著。
- 客观指标:
- 法语→英语:BLEU 30.6,平均延迟 6.1秒。
- 西班牙语→英语:BLEU 32.3,平均延迟 5.6秒。
模型在提升翻译准确性的同时,成功降低了延迟。
高效推理与新语言适应能力
在推理阶段,Hibiki-Zero 采用简单的温度采样策略,这使其天然支持批处理。在单张 H100 GPU 上,其批处理推理速度可达实时速度的 3 倍。
更重要的是,Hibiki-Zero 展现了强大的新语言适应能力。研究团队仅使用一个包含不到 1000 小时意大利语语音的句子级对齐数据集,通过监督微调结合 GRPO 强化学习流程,就成功训练出了一个具备竞争力的意英翻译模型。这证明了该方法能以极低的成本和复杂度,将现有模型快速扩展至新语种。
目前,Kyutai 已将 Hibiki-Zero 的全部推理代码和模型权重开源,为社区提供了一个强大、高效且易于扩展的实时语音翻译解决方案。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











