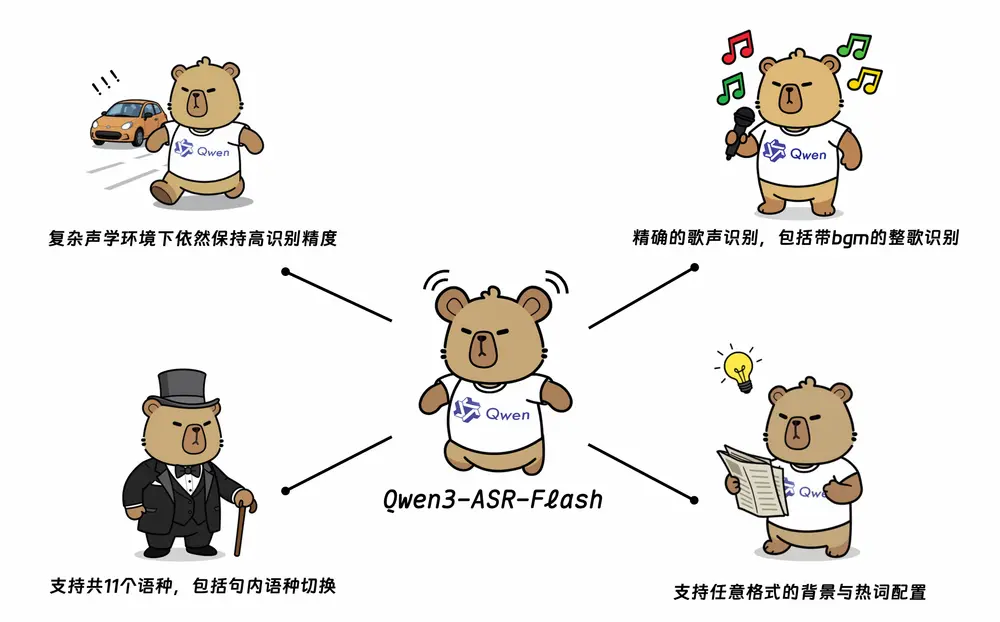
文本转语音(TTS)领域迎来一位重量级开源选手 —— OpenAudio S1-mini。
这是由 Fish Audio 团队 推出的 S1 模型的轻量化版本,参数规模为 5亿(0.5B),基于超过 200万小时 的多语言音频数据训练而成。它不仅支持 14种主流语言,还具备丰富的情感、语调与特殊音效控制能力,是当前开源 TTS 领域中表现最为全面的模型之一。
- GitHub:https://github.com/fishaudio/fish-speech
- 模型:https://huggingface.co/fishaudio/openaudio-s1-mini
- Demo:https://huggingface.co/spaces/fishaudio/openaudio-s1-mini
最重要的是:S1-mini 完全免费且可本地部署,非常适合个人开发者、研究人员和内容创作者使用(仅限非商业用途)。
🎯 核心亮点一览
| 功能 | 描述 |
|---|---|
| 多语言支持 | 支持英语、中文、日语、德语等 14 种语言 |
| 情感丰富 | 提供 50+ 种情感与语气控制标签 |
| RLHF 强化学习 | 基于人类反馈优化语音自然度 |
| 特殊效果支持 | 笑声、哭泣、喊叫、耳语等多种音效 |
| 开源可用 | 可本地部署,适用于非商业用途 |
🔊 支持的语言列表(持续扩展)
目前,OpenAudio S1-mini 支持以下 14 种语言:
- 英语 (en)
- 中文 (zh)
- 日语 (ja)
- 德语 (de)
- 法语 (fr)
- 西班牙语 (es)
- 韩语 (ko)
- 阿拉伯语 (ar)
- 俄语 (ru)
- 荷兰语 (nl)
- 意大利语 (it)
- 波兰语 (pl)
- 葡萄牙语 (pt)
团队表示,未来将逐步增加对更多语言的支持,进一步提升其全球适用性。
😲 情感与语气控制:让 AI 更有“人味”
S1-mini 最引人注目的功能之一是其强大的情感与语气控制能力,通过特殊的文本标记即可实现语音情绪的变化。以下是部分支持的指令示例:
✅ 基础情感:
(生气) (伤心) (兴奋) (惊讶) (满意) (高兴)
(害怕) (担心) (沮丧) (紧张) (挫败) (郁闷)
(同情) (尴尬) (厌恶) (感动) (自豪) (放松)
(感激) (自信) (感兴趣) (好奇) (困惑) (快乐)✅ 高级情感:
(鄙视) (不开心) (焦虑) (歇斯底里) (冷漠)
(不耐烦) (内疚) (轻蔑) (恐慌) (愤怒) (不情愿)
(热衷) (不赞成) (消极) (否认) (震惊) (严肃)
(讽刺) (安抚) (安慰) (真诚) (冷笑)
(犹豫) (屈服) (痛苦) (尴尬) (觉得有趣)✅ 语调标记:
(急促的语调) (喊叫) (尖叫) (耳语) (柔和的语调)✅ 特殊音频效果:
(笑声) (轻笑) (抽泣) (大声哭泣) (叹息) (喘息)
(呻吟) (人群笑声) (背景笑声) (观众笑声)此外,你还可以通过重复关键词如 “哈,哈,哈” 来引导模型生成特定类型的笑声或其他音效。
当前情感控制主要支持 英语、中文和日语,其他语言将在后续版本中陆续加入。
🧠 模型架构与性能表现
OpenAudio S1 系列包含两个主要变体:
| 模型 | 参数量 | 是否开源 | 商用许可 |
|---|---|---|---|
| S1 | 40亿 | ❌(专有) | ✅(需授权) |
| S1-mini | 5亿 | ✅(开源) | ❌(仅限非商用) |
S1-mini 是 S1 的蒸馏版本,在保持高质量输出的同时大幅降低了计算资源需求,使其更适合本地部署与推理。
📊 自动评估指标(英文测试集)
| 模型 | WER(词错误率) | CER(字符错误率) | 扬声器距离(越小越好) |
|---|---|---|---|
| S1 | 0.008 | 0.004 | 0.332 |
| S1-mini | 0.011 | 0.005 | 0.380 |
尽管稍逊于旗舰版 S1,但 S1-mini 在开源 TTS 模型中仍表现出色,尤其在情感控制方面远超同类模型。
🛠️ 技术细节与部署方式
- 训练数据:超过 200 万小时的多语言语音数据
- 强化学习:采用在线 RLHF(人类反馈强化学习),提升语音自然度
- 部署支持:提供完整的 Docker 和 API 示例,便于本地运行
- 许可证:CC-BY-NC-SA-4.0,仅限非商业用途
你可以在 Fish Speech GitHub 获取完整模型与部署指南。
🧩 如何体验?
你可以通过以下几种方式体验 OpenAudio S1-mini:
- 在线试听:访问 Fish Audio Playground 直接试用
- GitHub 项目页:查看模型文档与部署说明:Fish Speech GitHub
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











