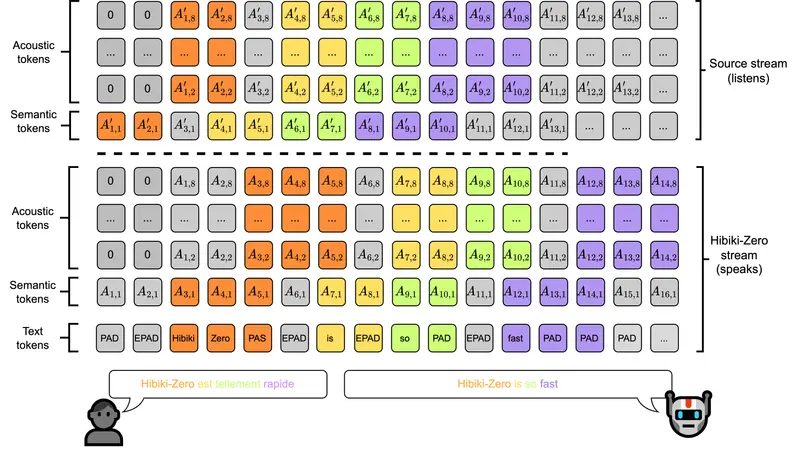
Mistral AI 推出全新 Voxtral Transcribe 2 系列语音转文本(ASR)模型,包含面向批量离线处理的 Voxtral Mini Transcribe V2 和专为低延迟实时场景打造的 Voxtral Realtime,凭借顶尖转录精度、原生多语言支持、企业级实用功能,以及 Voxtral Realtime 全量开源的优势,成为兼顾云端效率与本地隐私部署的新一代ASR方案,同时配套Mistral Studio音频体验平台,可即时测试全功能。
- API:https://console.mistral.ai/build/audio/speech-to-text
- Voxtral Realtime:https://huggingface.co/mistralai/Voxtral-Mini-4B-Realtime-2602
- 文档:https://docs.mistral.ai/capabilities/audio_transcription

双模型产品矩阵:精准覆盖离线/实时全场景
两款模型分工明确,从低成本批量转录到200ms内超低延迟实时交互,全方位适配语音转写的各类需求,且均原生支持13种语言,中文、英语、日语等主流语种表现亮眼。
| 模型名称 | 核心定位 | 核心优势 | 部署方式 | API定价 |
|---|---|---|---|---|
| Voxtral Mini Transcribe V2 | 批量离线转录 | 4%超低词错误率、3小时长音频、极致性价比、全企业功能 | 云端API | 0.003美元/分钟 |
| Voxtral Realtime | 实时流式转录 | 200ms以下可配延迟、40亿轻量化参数、Apache 2.0开源 | 云端API+本地/边缘部署 | 0.006美元/分钟 |
核心亮点:碾压级性能+开源自由+企业级能力
1. 实时模型全开源,隐私部署无门槛
Voxtral Realtime 采用 Apache 2.0 开源协议发布完整模型权重,40亿参数量实现轻量化设计,可直接部署在边缘设备、本地服务器或私有云,数据全程不上云,完美适配金融、医疗、政企等隐私敏感场景,同时满足GDPR、HIPAA等合规要求。
2. 超低延迟+近离线精度,重构实时语音体验
Voxtral Realtime 采用全新原生流式架构,区别于传统离线模型的分块处理方式,音频输入时即可即时转录,无需等待整段音频处理。延迟可灵活配置:
- 最低压至200毫秒以下,满足语音智能体、实时字幕等极致低延迟需求;
- 480ms延迟下,词错误率仅增加1-2%,保持接近离线的转录精度;
- 2.4s延迟(字幕生成主流场景)下,性能与批量版Voxtral Mini Transcribe V2持平。
3. 业界顶尖性价比,批量转录成本骤降
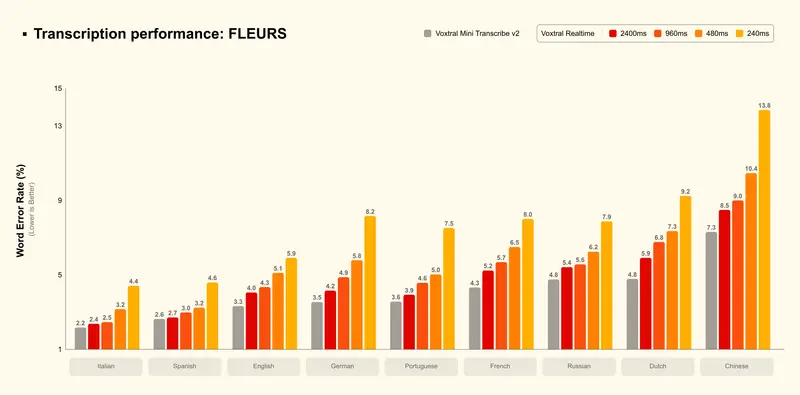
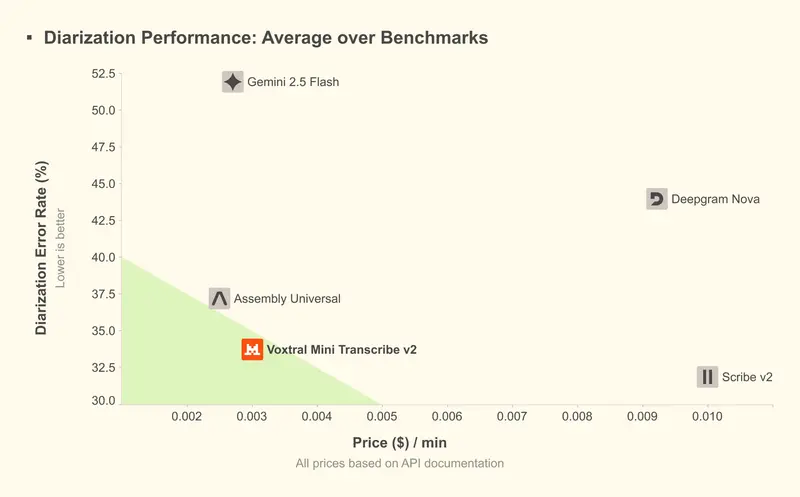
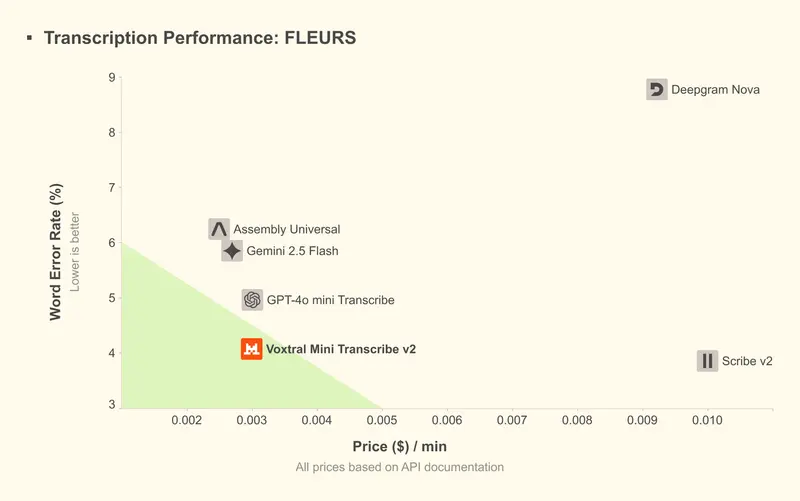
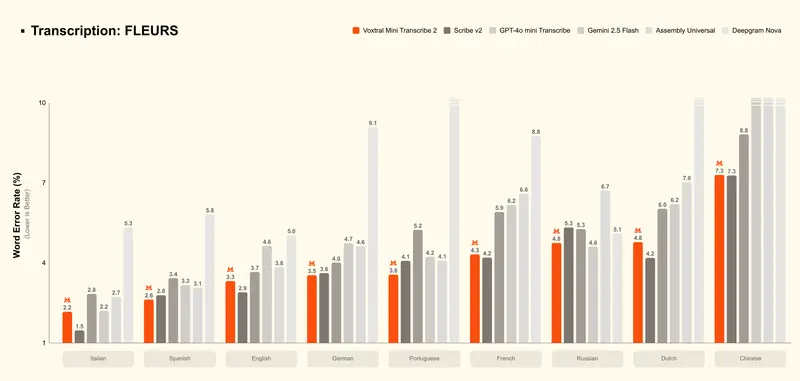
Voxtral Mini Transcribe V2 在FLEURS数据集上实现约4%的词错误率,准确率直接超越GPT-4o mini Transcribe、Gemini 2.5 Flash、Assembly Universal等主流商用转录API;同时处理速度比ElevenLabs Scribe v2快3倍,而成本仅为其1/5,是当前商用转录服务中性价比最优的选择。
4. 全栈企业级功能,一站式满足生产需求
两款模型均内置企业部署所需的核心能力,无需额外拼接第三方工具,覆盖从转录到应用的全流程:
- 说话人分离:自动识别发言者,生成带说话人标签+精确起止时间的转录文本,适配会议、访谈、多方通话;
- 词级时间戳:为每个单词生成精准时间信息,支持字幕制作、音频内容搜索、精准剪辑;
- 上下文偏置:可自定义最多100个单词/短语,引导模型正确拼写专有名词、技术术语、姓名等,解决通用模型的拼写痛点(英语优化至最佳);
- 超强噪音鲁棒性:在工厂车间、繁忙呼叫中心、户外现场录音等复杂声学环境下,仍能保持稳定的转录准确率;
- 超长音频支持:Voxtral Mini Transcribe V2单次请求可处理长达3小时的录音,无需分段上传,提升批量处理效率。
5. 原生多语言支持,主流语种全覆盖
两款模型均完美支持13种语言:英语、中文、印地语、西班牙语、阿拉伯语、法语、葡萄牙语、俄语、德语、日语、韩语、意大利语、荷兰语,其中中文、英语、日语实现顶尖转录品质,非英语语种性能显著优于行业竞品,适配全球化业务场景。
Voxtral Mini Transcribe V2:批量转录的性能标杆
作为离线批量处理的核心模型,Voxtral Mini Transcribe V2聚焦高准确率、长音频、低成本三大核心需求,是会议归档、媒体内容转写、合规录音处理、播客字幕制作等场景的最优解。
除了上述企业级功能,其核心优势还体现在规模化处理效率上:极低的单分钟定价,搭配3小时长音频支持,可实现海量音频的低成本、高效率转录标注,大幅降低企业内容数字化的成本。
Mistral Studio 音频体验平台:零成本即时测试
同步推出的Mistral Studio音频体验平台,由Voxtral Transcribe 2全量驱动,无需开发接入,即可直接测试所有核心功能:
- 支持上传.mp3、.wav、.m4a、.flac、.ogg等主流音频格式,单文件最大1GB,最多可同时上传10个;
- 可视化操作:一键开关说话人分离、自由选择时间戳粒度、自定义添加上下文偏置词;
- 结果可直接查看、导出,快速验证模型效果,为API接入或本地部署提供参考。
全行业应用场景:重构语音转写工作流
Voxtral Transcribe 2凭借双模型的灵活组合,可赋能全行业的语音相关应用,打造更高效、更智能的语音工作流:
1. 会议智能
多语言会议录音一键转录,说话人分离清晰标记发言者与发言时间,结合极致性价比,可实现企业海量会议内容的规模化归档与分析。
2. 语音智能体/虚拟助手
将Voxtral Realtime与LLM、TTS管道对接,打造延迟低于200ms的对话式AI,实现自然、无感知的语音交互,适配智能音箱、车载助手、企业虚拟客服等场景。
3. 联络中心自动化
实时转录座席与客户的通话内容,AI系统可同步分析对话情感、智能推荐回复话术、自动填充CRM字段,说话人分离确保发言归属清晰,提升客服效率与服务质量。
4. 媒体与广播
为直播、综艺、影视等内容生成低延迟多语言实时字幕,上下文偏置功能精准处理影视角色名、专业术语,避免通用转录服务的拼写错误。
5. 合规与文档留存
对金融、医疗等行业的业务交互进行全程监控与转录,说话人分离+词级时间戳提供清晰、可追溯的转录记录,满足行业法规的留存与审计要求。
快速开始使用
1. 云端快速试用
- Voxtral Mini Transcribe V2:可直接在Mistral Studio音频体验平台或Le Chat中上传音频测试,也可通过官方API接入,0.003美元/分钟;
- Voxtral Realtime:云端API接入0.006美元/分钟,流式接口适配实时应用开发。
2. 本地/边缘部署(Voxtral Realtime 开源版)
模型权重已全量发布在Hugging Face Hub,可直接下载部署,支持Transformers、vLLM、TGI等主流推理框架,消费级GPU即可实现实时运行,核心步骤如下:
- 从Hugging Face Hub下载开源模型权重;
- 安装Python依赖(transformers、torch、soundfile等);
- 加载模型与处理器,调用流式推理接口实现实时音频转录。
3. 官方文档
可通过Mistral官方文档,查看API接入规范、模型部署指南、参数配置详解等全量内容,快速完成开发与部署。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











