在 AI 绘画与视频生成领域,显存(VRAM)和系统内存(RAM) 一直是限制创作者发挥的最大瓶颈。面对动辄数十 GB 的图像和视频模型,许多用户不得不忍受频繁的“显存不足(OOM)”崩溃,或是依赖缓慢的系统分页文件(Swap),导致生成速度骤降。
- 官方说明:https://blog.comfy.org/p/dynamic-vram-in-comfyui-saving-local
今日,ComfyUI 正式推出了 动态显存 (Dynamic Memory) 系统。这是一次底层架构的重构,彻底解决显存危机,让最大的开源模型也能在消费级硬件上高效运行。
核心突破:从“预测加载”到“按需故障处理”
传统的 PyTorch 显存管理依赖于预先分配:在推理开始前,系统必须估算并加载所有权重到显存中。如果估算错误或显存不足,程序就会崩溃或被迫使用慢速硬盘交换。
动态显存 引入了一个自定义的 PyTorch 分配器,彻底改变了这一逻辑:
1. 虚拟基址寄存器 (VBAR):零成本占位
- 机制:加载模型时,ComfyUI 不再立即占用物理显存,而是创建一个 VBAR。它只消耗 GPU 的虚拟地址空间,物理显存占用为 零。
- 优势:你可以瞬间“加载”一个 56GB 的模型,而实际上没有任何数据被搬入显存。
2. fault() API:毫秒级按需加载
- 机制:只有当计算真正需要某一层权重的那一毫秒,系统才会通过
fault()API 将该部分数据调入显存。 - 效果:实现了真正的流式推理。数据只在需要时存在,用完即释放或降级。
3. 智能分级与水位线系统
- 优先级管理:最近使用的权重拥有最高优先级。
- 自动驱逐:当显存紧张时,系统会自动驱逐低优先级权重。
- 水位线保护:一旦某部分权重被驱逐,系统会设置“水位线”,防止程序无谓地反复尝试加载已满的显存,避免性能抖动。
4. 未提交显存映射 (Uncommitted Memory Mapping)
- 新加载器:ComfyUI 现在使用自定义的 safetensors 加载器,将模型文件以未提交的文件支持显存方式映射。
- 操作系统协作:这些显存处于“未提交”状态,操作系统可以随时回收它们给其他程序使用,而不会导致 ComfyUI 崩溃。当 ComfyUI 再次需要时,OS 会自动从高速 NVMe SSD 重新读取。
- 告别分页文件:以前显存不足时会写入缓慢的系统分页文件(Swap),现在直接释放显存并回退到未提交状态,彻底消除了因 Swap 导致的卡顿。
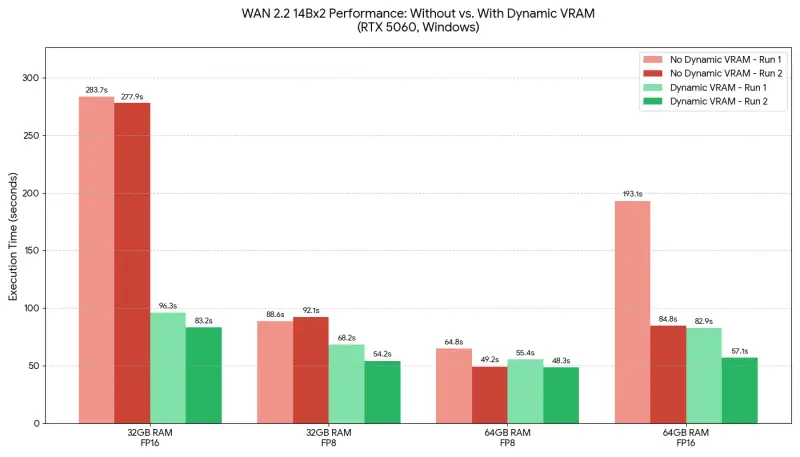
性能飞跃:基准测试与现实意义
实测数据
- 视频工作流 (Windows, RTX 4060/5060, 32GB RAM):
- 成功运行总大小为 56GB (2x28GB fp16) 的扩散模型。
- 在传统模式下,这需要至少 64GB+ 显存且极易崩溃,现在丝滑运行。
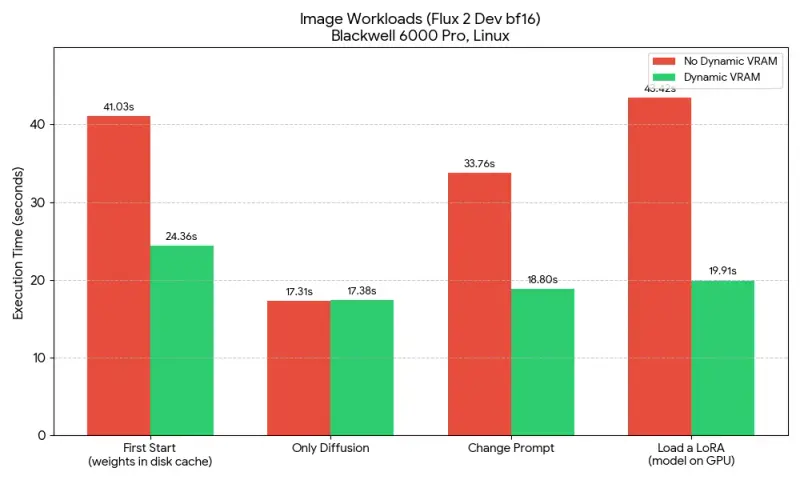
- Flux 2 Dev (Linux, Blackwell 6000 Pro):
- 模型加载时间显著缩短,近乎瞬时。
- 整体工作流执行速度提升,消除了因显存交换带来的延迟。
用户体验改进
| 特性 | 传统模式 | 动态显存模式 |
|---|---|---|
| 大模型加载 | 缓慢,易 OOM | 瞬时加载,永不 OOM |
| 显存占用 | 固定高位,无法释放 | 动态伸缩,按需分配 |
| 分页文件 (Swap) | 频繁使用,导致卡顿 | 完全避免 |
| 显存利用率 | 保守,常有闲置 | 极高,充分利用最快显存 |
| 多模型切换 | 需手动卸载,繁琐 | 自动平衡,无缝切换 |
💡 关于任务管理器的提示:
在 Windows 任务管理器中,你可能仍会看到较高的显存占用。这是 ComfyUI 的智能缓存策略:如果有空闲显存,它会留住权重以加速下次调用。但关键在于,这些缓存永远不会被推送到分页文件。一旦其他应用需要显存,ComfyUI 会立即释放,确保系统流畅。
技术深度解析:为什么它更快?
- 减少总线流量:不再需要在显存 (VRAM) 和系统内存 (RAM) 之间频繁搬运整个模型权重。数据仅在必要时从磁盘流入显存,或在显存内就地释放。
- 消除预测误差:不再需要开发者或用户去猜测“这个工作流需要多少显存”,分配器实时感知并调整。
- 开发简化:节点开发者无需再编写复杂的显存清理代码,底层分配器自动处理一切。
未来路线图
ComfyUI 团队并未止步于此,后续计划包括:
- 多硬件支持:即将适配 AMD GPU 及其他非 Nvidia 硬件。
- 中间值优化:智能释放节点间的临时张量,进一步降低峰值显存。
- 极致磁盘卸载:针对超高速 NVMe SSD 优化,实现完全基于磁盘的模型卸载,理论上可运行远超物理显存限制的巨型模型。
动态显存 是 ComfyUI 自诞生以来最重要的底层更新之一。它不仅解决了“能不能跑”的问题,更解决了“跑得顺不顺”的痛点。
对于拥有 12GB/16GB 显存显卡的用户,这意味着可以挑战以前不敢想象的复杂工作流;对于显存有限的笔记本用户,这意味着本地 AI 创作不再是奢望。ComfyUI 正通过技术创新,抹平硬件差距,让最先进的 AI 模型真正属于每一个人。
立即更新 ComfyUI,体验这场内存管理的革命。如果你的 NVMe 够快,也许明天,你就能在本地跑起那个曾经只存在于云端的巨型模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...