
当 AI 生成音乐从“预设播放”走向“实时演奏”,我们正在见证创作方式的一次深刻转变。
传统的音乐生成模型通常以“批处理”模式运行:输入一段提示,等待几秒后输出完整音频。这种模式虽能产出完整作品,却缺乏即时反馈与动态控制,难以融入真实的创作流程。
为此,Google DeepMind 与 Magenta 团队联合推出 Magenta RealTime(简称 Magenta RT)——一个开放权重、支持实时交互的音乐生成模型,旨在将 AI 从“内容生产工具”转变为“可演奏的数字乐器”。
- GitHub:https://github.com/magenta/magenta-realtime
- 模型:https://huggingface.co/google/magenta-realtime
- 官方介绍:https://magenta.withgoogle.com/magenta-realtime
作为 Lyria RealTime 的开源版本,Magenta RT 不仅支持文本或音频提示驱动,还能在用户持续输入下动态调整风格、结构与情绪,实现真正意义上的“人机共演”。
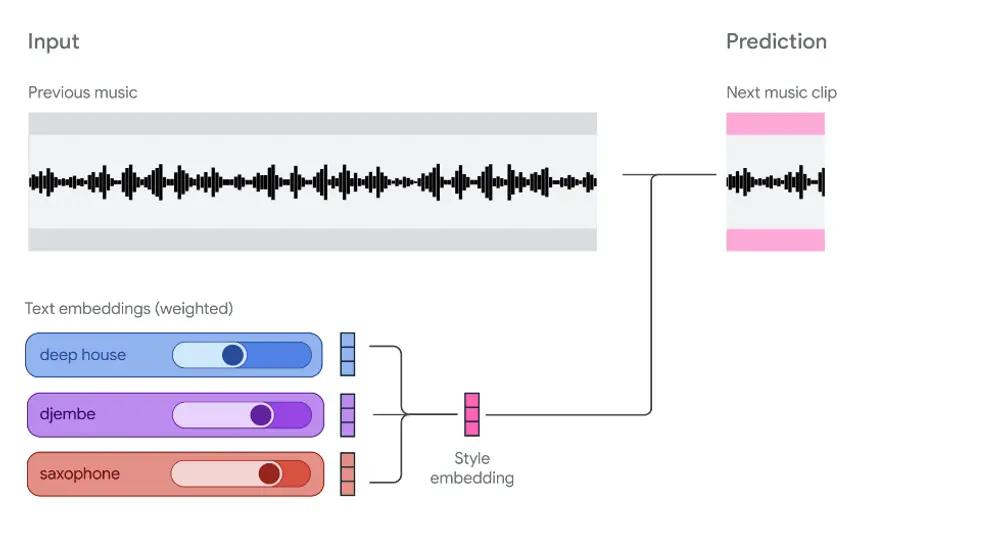
什么是实时音乐生成?
实时音乐生成的核心要求是:
- 实时因子 > 1:生成 X 秒音频所用时间少于 X 秒;
- 因果流式处理:模型只能依赖历史输入,不能“预知未来”;
- 低延迟响应:用户控制信号需在短时间内影响输出。
这些要求使得实时生成远比离线生成更具挑战性。Magenta RT 正是为此而设计。
技术架构:块自回归 + 高保真表示
Magenta RT 基于 MusicLM 架构改进,采用块自回归(Chunk Autoregressive)机制,在性能与延迟之间取得平衡。
工作流程
- 输入处理:
- 用户提供文本描述(如“欢快的爵士钢琴”)或音频片段(如一段吉他 riff);
- 提示被编码为风格嵌入向量;
- 上下文建模:
- 模型维护一个 10 秒的音频上下文窗口,编码为粗粒度 token;
- 音频生成:
- 每 2 秒生成一个新音频块,基于上下文和当前风格嵌入;
- 使用 SpectroStream 解码器输出 48kHz 立体声,音质接近专业录音;
- 实时控制:
- 用户可在生成过程中动态调整提示混合(如“70% 爵士 + 30% 电子”),影响后续输出。
整个过程在 Colab 免费 TPU 上实现 1.6 倍实时因子(2 秒音频生成耗时约 1.25 秒),延迟可控。
核心能力:不只是生成,更是探索
Magenta RT 的价值不仅在于“生成音乐”,更在于它打开了潜在音乐空间的实时探索。
1. 多模态提示混合
支持文本与音频提示的加权融合,例如:
- 用一段非洲鼓点 + “科幻氛围”文本,生成跨文化的实验音景;
- 将自己的哼唱作为起点,引导模型生成变奏。
2. 实时风格插值
通过滑动控制条,用户可在不同风格间平滑过渡,如同 DJ 切换曲风,创造出动态演化的音乐结构。
3. 潜在空间导航
模型内部表示允许用户探索从未听过的乐器组合、节奏模式与和声进行,发现新颖的循环与纹理,用于后续编曲。
4. 交互式音景构建
适用于艺术装置、游戏背景音乐、虚拟空间配乐等场景,音乐随用户行为动态变化,而非固定播放。
开放与可定制:为创作者而生
Magenta RT 是一个开放权重模型,具备以下特点:
| 项目 | 说明 |
|---|---|
| 参数量 | 8 亿 |
| 训练数据 | 约 19 万小时器乐为主的库存音乐 |
| 模型代码 | 开源(GitHub) |
| 权重发布 | Google Cloud Storage 与 Hugging Face |
| 许可协议 | 宽松许可,支持研究与非商业用途,含少量定制条款 |
此外,用户可:
- 本地微调:基于自己的音频数据调整模型风格;
- 实时音频输入:接入麦克风或乐器,实现现场互动;
- 设备端部署:团队正推进消费级硬件上的本地运行,未来可离线使用。
👉 查看 Colab Demo 亲自体验模型推理。
为什么需要实时交互?
Magenta 团队始终相信:AI 应增强而非替代人类创造力。
而实时交互正是实现这一理念的关键:
- 更高的控制带宽:每一次提示调整都直接影响音乐走向,输出更具个性;
- 促进创作流状态:连续的“感知-动作”循环帮助用户进入专注创作的心理状态;
- 强调过程而非结果:音乐不再是“成品”,而是一段可参与的体验;
- 避免被动内容泛滥:实时模型天然限制批量生成,鼓励主动参与。
这正是 Magenta 多年来坚持探索的方向——从 Piano Genie 到 NSynth,再到 AI Duet,始终致力于构建“可演奏的 AI”。
已知局限性
尽管能力强大,Magenta RT 仍有改进空间:
| 局限 | 说明 |
|---|---|
| 音乐风格覆盖 | 训练数据以西方器乐为主,对声乐、全球传统音乐支持有限 |
| 歌词生成 | 不支持条件化歌词生成,可能产生非词汇发声或意外语义内容 |
| 控制延迟 | 最小延迟为 2 秒(块大小决定),高频控制受限 |
| 上下文长度 | 仅能访问最近 10 秒音频,无法构建长期结构(如主歌-副歌循环) |
对于更广泛风格需求,建议使用 Lyria RealTime API(通过 Google AI Studio 接入)。
未来方向
Magenta RT 的发布只是起点。团队正在推进:
- 设备端推理:让模型在手机、笔记本等本地设备运行;
- 下一代模型:追求更低延迟、更高音质、更强交互性;
- 可演奏乐器设计:打造真正意义上的“AI 伴奏伙伴”,支持即兴对话式演奏。
目标是让每个人都能拥有一种新的数字乐器,无需乐理基础,也能表达音乐直觉。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











