TwinFlow是一种通过自对抗流(Self-adversarial Flows)将大型扩散模型(如 Qwen-Image、Z-Image)加速至 1 步或极低步数(2–4 步)生成的先进技术。
ComfyUI-TwinFlow 是一个严格遵循 ComfyUI 节点规范的自定义节点实现,让你在保持工作流灵活性的同时,安全、高效地使用 TwinFlow 的加速能力。
- GitHub:https://github.com/mengqin/ComfyUI-TwinFlow
- 模型:https://huggingface.co/azazeal2/TwinFlow-Z-Image-Turbo-repacked
- 网盘下载:https://pan.quark.cn/s/7e866ff6f828?pwd=ifrG
为什么选择本实现?(vs 其他 TwinFlow 节点)
目前存在另一个 TwinFlow 节点(smthemex/ComfyUI_TwinFlow),但其存在以下问题:
- ❌ 使用独立模型加载器,无法与标准 ComfyUI UNet/CLIP 节点兼容;
- ❌ 内置封闭式 KSampler,难以与其他节点(如 LoRA、ControlNet)组合;
- ❌ 缺少原始论文中的部分调度选项,灵活性受限。
而本实现:
- ✅ 完全基于 ComfyUI 标准接口,模型、VAE、CLIP 均通过标准节点接入;
- ✅ 模块化设计:提供独立的
Model Patcher、Sampler、Scheduler,也可使用一体化KSampler; - ✅ 完整支持 TwinFlow 调度参数(Kumaraswamy 分布、时间间隙等);
- ✅ 兼容 LoRA、IP-Adapter、ControlNet 等第三方节点,可自由构建复杂工作流。
核心功能
| 功能 | 说明 |
|---|---|
| TwinFlow Model Patcher | 注入 TwinFlow 补丁权重(.safetensors 或 .gguf),恢复被 ComfyUI 移除的关键时间嵌入张量(此步骤不可省略) |
| TwinFlow Sampler | 支持 euler(一阶)和 heun(二阶)积分方法 |
| TwinFlow Scheduler | 实现 Kumaraswamy 时间变换,支持自定义时间流分布 |
| TwinFlow KSampler | 一体化节点,简化低步数生成流程 |
安装
cd ComfyUI/custom_nodes
git clone https://github.com/mengqin/ComfyUI-TwinFlow.git
cd ComfyUI-TwinFlow
pip install -r requirements.txt
重启 ComfyUI 后生效。📂 模型准备
将 TwinFlow 补丁文件放入 ComfyUI/models/unet/ 目录:
ComfyUI/
└── models/
└── unet/
└── TwinFlow_Z_Image_Turbo_bf16.safetensors
补丁文件需与基础模型(Qwen-Image / Z-Image)严格对应。
使用方法
步骤 1:模型修补(必需)
- 使用标准节点加载你的 DiT 模型(如 Qwen-Image);
- 将模型连接到
TwinFlow Model Patcher节点; - 在
patch_file中选择对应的 TwinFlow 补丁文件。
⚠️ 重要:TwinFlow 推理依赖一个额外的时间嵌入张量,而 ComfyUI 的标准 UNet 加载器会将其移除。必须通过本修补器恢复,否则生成将失败或失真。
步骤 2:采样(二选一)
方式 A:使用一体化节点(推荐)
- 直接使用
TwinFlow KSampler,设置:steps: 1–4(推荐 1 步用于 Z-Image Turbo,2–4 步用于 Qwen-Image)sampling_style:few:极低步数(1–4 步)any:通用模式mul:多步精细生成
sampling_method:euler(快)或heun(更准)
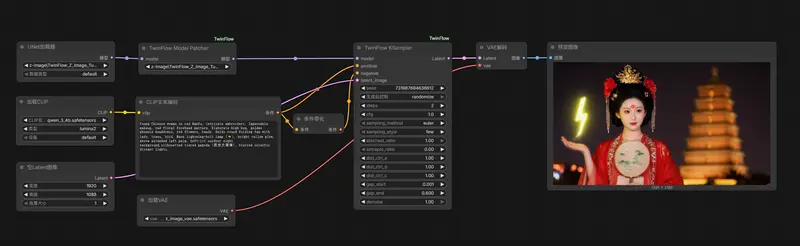
方式 B:自定义采样链
- 将
TwinFlow Sampler+TwinFlow Scheduler连接到标准SamplerCustom节点; - 可自由插入 LoRA、提示词加权、高分辨率修复 等节点。
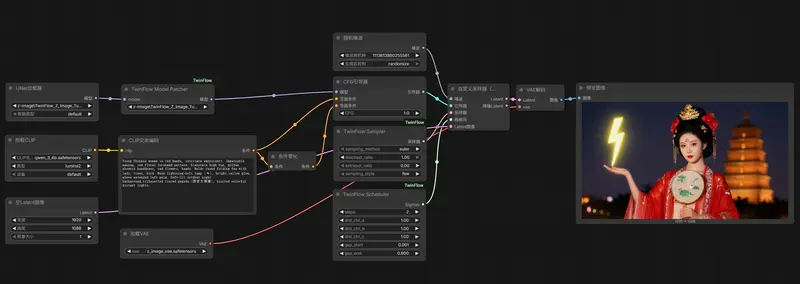
关键参数说明
| 参数 | 作用 |
|---|---|
dist_ctrl_a, b, c | 控制 Kumaraswamy 时间分布的形状,默认 1.0 为线性流 |
gap_start / gap_end | 定义流的时间边界(通常设为 0.0 / 1.0) |
block_number(显存优化) | 若 VRAM > 16GB,可设为 0 以最大化速度 |
注意事项
- 显存需求:
- Qwen-Image(1024×768):约 12GB VRAM(开启模型卸载)
- Z-Image Turbo:12GB VRAM 下 2–3 秒/图(Q8 量化)
- 模型格式:
- GGUF 适用于低显存设备(推荐 Q6_K / Q8_0)
- SafeTensors(BF16/FP16)适用于高精度场景
- 不要混用不同实现:本节点与 smthemex 版本不兼容,请勿同时安装。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











