
当前,大规模多模态生成模型(如 Qwen-Image、Z-Image)在图像与视频生成上展现出惊人能力,但其推理效率仍严重受限——标准扩散或流匹配模型通常需 40–100 次函数评估(NFE)才能生成一张图像。这使得它们难以部署在实时或资源受限场景。
为加速推理,研究者提出了多种“少步生成”方法,但现有方案普遍陷入三重困境:
- 依赖冻结的教师模型(如一致性蒸馏),限制灵活性;
- 引入对抗训练与判别器(如 DMD2、SANA-Sprint),导致训练不稳定、显存爆炸;
- 在极低步数(<4 NFE)下质量显著下降,难以实用。
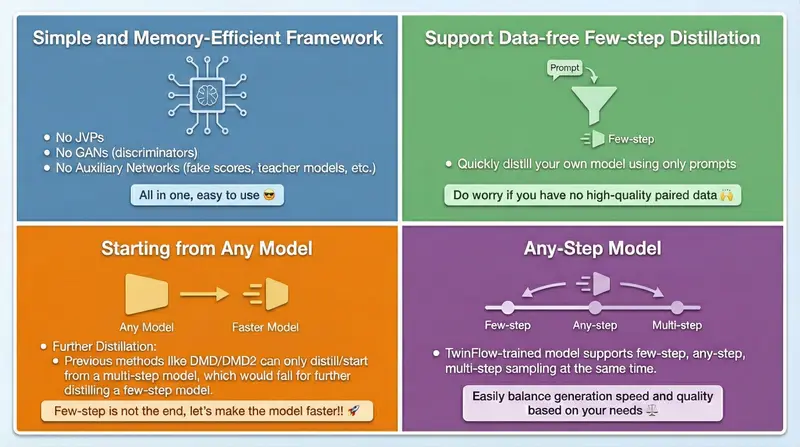
近日,Inclusion AI、上海创智学院、西湖大学与浙江大学联合提出 TwinFlow —— 一个无需教师模型、无需判别器、仅用单模型即可实现1步高质量生成的新框架,为少步生成提供了更简洁、可扩展的路径。
- 项目主页:https://zhenglin-cheng.com/twinflow
- GitHub:https://github.com/inclusionAI/TwinFlow
- TwinFlow-Qwen-Image-v1.0:https://huggingface.co/inclusionAI/TwinFlow
- TwinFlow-Z-Image-Turbo:https://huggingface.co/inclusionAI/TwinFlow-Z-Image-Turbo

TwinFlow 的核心思想:用“孪生轨迹”实现自对抗
TwinFlow 的关键创新在于 “孪生轨迹”(Twin Trajectory) 机制。
传统流匹配模型定义时间区间为 $ t \in [0,1] $,从噪声($t=0$)逐步映射到真实数据($t=1$)。
TwinFlow 则将时间轴对称扩展至 $ t \in [-1,1] $:
- 正向轨迹($t > 0$):将噪声映射为真实数据(常规生成路径)
- 负向轨迹($t < 0$):将同一噪声映射为“伪”数据(即模型当前能力下的不完美输出)
模型通过最小化两条轨迹在速度场(velocity field)上的差异 $\Delta v$,实现自我校正。
这相当于在模型内部构建了一个自监督的对抗信号——无需外部判别器,也无需冻结的教师模型。
训练目标结合了标准多步生成损失与速度匹配损失,通过简单混合即可优化。
三大优势:简洁、高效、可扩展
| 维度 | 传统方法(DMD2 / 一致性模型) | TwinFlow |
|---|---|---|
| 是否需判别器 | 是(1–2个) | ❌ 否 |
| 是否需冻结教师模型 | 是 | ❌ 否 |
| 大模型训练可行性 | 显存溢出风险高 | ✅ 支持全参数训练(如 20B 模型) |
| 1-NFE 生成质量 | 显著下降 | 接近 100-NFE 原始模型 |
1. 极简架构,降低训练复杂度
仅需一个可训练模型,避免维护多个网络(生成器+判别器+教师),大幅减少 GPU 内存占用。
2. 1-NFE 生成媲美百步模型
在 Qwen-Image-20B 上,TwinFlow 仅用 1 次函数评估,即可在 GenEval(0.86)和 DPG-Bench 上匹配原始 100-NFE 模型的性能(0.87),推理成本降低 100 倍。
3. 真正适用于大模型
现有方法(如 VSD、SiD、DMD)因需多模型并行,在 20B 级别常因显存不足失败。TwinFlow 的单模型设计使其首次实现 20B 级别全参数少步蒸馏。
实际进展:Qwen-Image 与 Z-Image 极速版发布
研究团队已基于 TwinFlow 框架推出两款高效生成模型:
- TwinFlow-Qwen-Image-v1.0:1–2 步生成高质量图像,适用于多模态推理与内容创作
- Z-Image-Turbo 优化版:进一步压缩推理步骤,提升生成速度
这些模型表明,少步生成不再是小模型的专利,大模型同样可以做到“快而准”。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











