北京大学、阿里巴巴集团、华盛顿大学、北京理工大学和百安斯实验室的研究人员推出新型图像生成框架 DREAM ENGINE,它通过两阶段训练方法,将 QwenVL 等多模态编码器与扩散模型集成在一起,从而实现高级的文本-图像交错控制,并在生成具有复杂、概念融合输入的图像方面实现了最先进的性能。该框架能够灵活地将文本描述和图像元素结合起来,生成符合用户需求的高质量图像。
- GitHub:https://github.com/chenllliang/DreamEngine
- 模型:https://huggingface.co/leonardPKU/DreamEngine-ObjectFusion
例如,用户可以输入一个指令:“将一只猫(参考图像1)放在海滩上(参考图像2)”,DREAM ENGINE 能够理解文本描述和参考图像的内容,并生成一个包含猫在海滩上的新图像。这种能力使得用户可以通过简单的文本指令和参考图像,精确地控制生成图像的视觉内容。

主要功能
- 文本-图像交错控制:用户可以输入文本描述和多个参考图像,模型能够根据文本指令将不同图像的视觉元素组合起来,生成新的图像。
- 高质量图像生成:在保留扩散模型高质量图像生成能力的同时,扩展了其对复杂多模态指令的理解和执行能力。
- 灵活的图像编辑:支持自由形式的图像编辑任务,例如根据文本指令修改图像中的对象或背景。
- 对象驱动的生成:能够根据输入的多个图像和文本描述,合成新的图像,例如将不同图像中的对象组合到一个场景中。
主要特点
- 高效的两阶段训练范式:通过联合文本-图像对齐和多模态交错指令微调,实现了 LMM 和扩散模型的有效融合。
- 轻量级适配器设计:通过一个简单的适配器层(两层 MLP),将 LMM 的输出与扩散模型的条件空间对齐,无需复杂的架构修改。
- 强大的多模态理解能力:利用 LMM 提供的统一语义空间,实现了文本和图像的无缝对齐,支持复杂的多模态指令。
- 无需更新 LMM 参数:在训练过程中,LMM 的参数保持不变,仅对适配器和扩散模型进行微调,保留了 LMM 原有的多模态理解能力。
工作原理
架构设计:
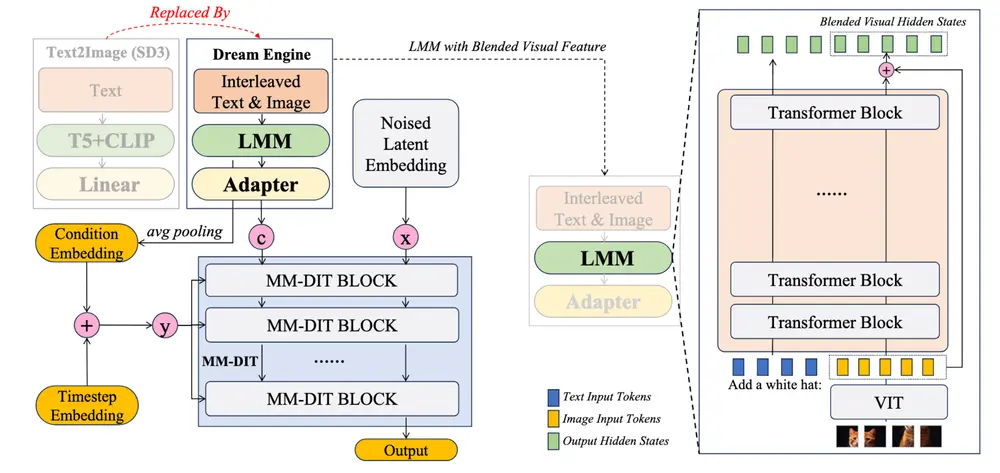
- LMM 替换文本编码器:用 QwenVL 等大型多模态模型替换传统扩散模型中的文本编码器(如 CLIP 和 T5),通过一个轻量级适配器层将 LMM 的输出映射到扩散模型的条件空间。
- 视觉特征融合:通过一个加权和机制(blending ratio)融合 LMM 的视觉特征和原始 ViT 特征,以控制生成图像的视觉一致性。
- 扩散模型模块:采用 MM-DiT 结构,将文本和图像条件嵌入到扩散模型中,通过扩散过程生成图像。
两阶段训练:
- 阶段 1(联合文本-图像对齐):冻结 LMM 和扩散模型参数,仅训练适配器层,通过高质量的图像-文本对和自监督的图像重建任务,对齐 LMM 和扩散模型的表示空间。
- 阶段 2(多模态交错指令微调):解冻扩散模型,训练适配器和扩散模型,通过自由形式图像编辑和对象驱动生成任务,进一步优化模型对复杂多模态指令的理解和执行能力。
具体应用场景
- 创意图像生成:
- 用户可以通过简单的文本指令和参考图像,生成包含多种视觉元素的创意图像,例如将一个角色放置在不同的场景中,或者将多个角色组合到一个场景中。
- 示例:将一只猫(参考图像1)放在海滩上(参考图像2),并为它添加一个超级英雄斗篷(文本指令)。
- 自由形式图像编辑:
- 用户可以输入一张图像和一个编辑指令,模型根据指令修改图像内容,例如更换背景、改变对象的外观等。
- 示例:将图像中的女孩替换为男孩,或者将背景改为宇宙。
- 对象驱动的特征混合:
- 用户可以输入多个图像和一个文本描述,模型根据文本指令将不同图像中的对象特征组合起来,生成新的图像。
- 示例:将一只猫的头部特征与女孩的头巾特征结合起来,生成一只戴着头巾的猫。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











