在本地运行Qwen Image 、WAN2.2等大模型时,显存占用高、推理速度慢是常见瓶颈。模型量化(如 INT8、FP8)可显著降低内存需求并提升推理吞吐,但 ComfyUI 原生对非标准量化格式支持有限。
- convert_to_quant:https://github.com/silveroxides/convert_to_quant
- GitHub:https://github.com/silveroxides/ComfyUI-QuantOps
ComfyUI-QuantOps 是一个扩展插件,专为 ComfyUI 设计,支持加载由 convert_to_quant 工具生成的量化模型,尤其完善支持 INT8 块级量化(Block-wise),让普通用户也能在消费级显卡上高效运行压缩模型。
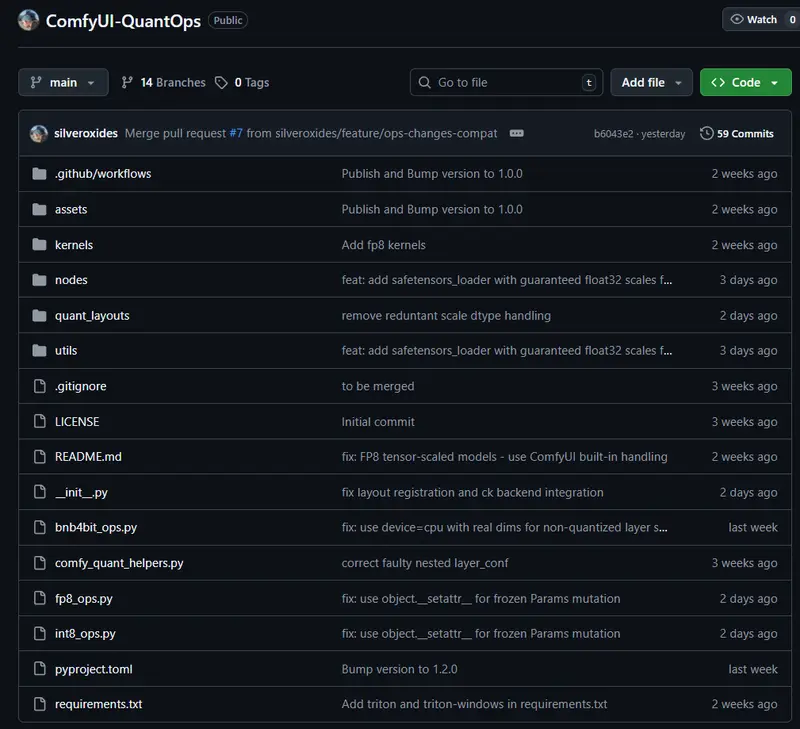
当前支持的量化格式
| 量化类型 | 布局方式 | 状态 |
|---|---|---|
| INT8(块级) | BlockWiseINT8Layout | ✅ 已支持 |
| FP8(张量级) | TensorCoreFP8Layout | ✅ ComfyUI 内置,无需额外插件 |
| FP8(行级 / 块级) | RowWiseFP8Layout / BlockWiseFP8Layout | 🚧 开发中 |
💡 重点:INT8 块量化是目前最实用的方案——相比 FP8,它兼容性更好,且在多数 GPU 上无需特殊硬件支持(如 NVIDIA H100 的 FP8 Tensor Core)。
核心功能
QuantizedModelLoader节点
可直接加载.safetensors格式的 INT8 量化主模型(如 SDXL、SD1.5),无需修改工作流。Load CLIP (Quantized)节点
支持量化后的文本编码器(如 T5-XXL、CLIP),适用于 SD3、FLUX 等多模态架构,进一步节省显存。- GPU 加速(可选)
安装 Triton(Linux)或 triton-windows 后,INT8 推理可获得额外性能提升。
使用流程(以 INT8 为例)
- 量化模型
使用convert_to_quant工具对原始模型进行块级 INT8 量化:convert_to_quant -i model.safetensors --int8 --comfy_quant --simple --block_size 128 - 放置模型文件
- 主模型 →
ComfyUI/models/checkpoints/ - 文本编码器 →
ComfyUI/models/text_encoders/
- 主模型 →
- 在 ComfyUI 中加载
- 主模型:使用 QuantizedModelLoader 节点
- 文本编码器:使用 Load CLIP (Quantized) 节点,并选择对应类型(如
sd3、flux)
实际收益
- 显存占用降低 30%~50%:INT8 模型体积约为原 FP16 模型的一半
- 推理速度提升:整数运算在多数 GPU 上比浮点更快
- 兼容现有工作流:只需替换模型加载节点,无需重构流程
⚠️ 注意:量化可能轻微影响生成质量,建议在“速度快 + 质量可接受”之间权衡。对细节要求极高的场景(如商业印刷)仍推荐使用 FP16 模型。
安装方式
cd ComfyUI/custom_nodes
git clone https://github.com/silveroxides/ComfyUI-QuantOps.git
(可选)启用 Triton 加速:
# 激活 ComfyUI 虚拟环境后执行
pip install triton # Linux
pip install triton-windows # Windows© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











